핵심 요약
- 2023년 학회 논문의 16%에 불과했던 VLM 연구가 2025년에는 40%를 차지합니다 (arXiv:2510.09586, 2025)
- MoE 아키텍처가 VLM의 표준이 되었고, Kimi K2.5(1T/32B), Qwen3.5(397B/17B) 등 거대 모델이 적은 연산으로 동작합니다
- Qwen3.5가 MMMU 85.0으로 GPT-5(84.2)를 넘어서며 오픈소스 VLM이 클로즈드 모델을 최초로 추월했습니다
- NEO, VL-JEPA 같은 모듈형 패러다임을 벗어난 새로운 접근이 등장하고 있습니다
Intro
CVPR, ICLR, NeurIPS 세 학회에서 VLM 관련 논문 비중이 2023년 16%에서 2025년 40%로 급증했습니다(arXiv:2510.09586, 2025). 26,104편의 논문을 분석한 서베이가 이 숫자를 보여주는데요, 불과 2년 만에 학계의 관심이 2.5배로 뛴 셈입니다.
2024년 말까지만 해도 GPT-4V가 Vision LLM의 기준점이었습니다. "이미지를 이해하는 LLM"이라고 하면 대부분 GPT-4V를 떠올렸고, 오픈소스 모델과의 격차는 꽤 컸습니다. 그런데 2025년 하반기부터 상황이 달라지기 시작합니다.
InternVL3.5가 Cascade RL로 추론 성능을 16% 끌어올리고, Qwen3-VL이 Thinking 변형을 모든 사이즈에 도입하고, Kimi K2.5가 1T 파라미터 MoE로 에이전트 기능까지 갖추면서 — 오픈소스 VLM 생태계가 폭발적으로 성장했습니다. 그리고 2026년 2월 16일, Qwen3.5가 MMMU 벤치마크에서 85.0을 기록하며 GPT-5(84.2)를 넘어섰습니다. 오픈소스가 클로즈드 모델을 추월한 최초의 사례입니다.
이 글에서는 지난 6개월간 등장한 핵심 모델 7개의 아키텍처를 비교하고, VLM 생태계를 재편하고 있는 5가지 트렌드를 정리합니다. 그리고 ViT-MLP-LLM이라는 모듈형 구조를 완전히 벗어나려는 NEO, VL-JEPA 같은 새로운 패러다임까지 다뤄보겠습니다.
Vision LLM 아키텍처 패러다임의 진화
Vision LLM이라고 하면 "Vision Encoder + Adapter + LLM"이라는 모듈형 구조를 떠올리기 쉽습니다. Vision Transformer가 이미지를 패치로 나누어 인코딩하고, MLP Adapter가 이를 LLM이 이해할 수 있는 표현으로 변환하고, LLM이 최종 응답을 생성하는 구조입니다. LLaVA가 이 패러다임을 대중화했고, 많은 후속 연구가 이 구조를 따랐습니다.
그런데 2025년 하반기부터 이 구조에 대한 도전이 본격화됩니다. 크게 네 가지 패러다임이 경쟁하고 있습니다.
첫 번째는 기존의 Modular 방식입니다. ViT, Adapter, LLM을 각각 독립적으로 발전시키고 조합하는 접근인데요, InternVL3.5와 LLaVA-OneVision-1.5가 이 방식의 최신 성과입니다. 검증된 구조이고 각 컴포넌트를 유연하게 교체할 수 있다는 장점이 있지만, 비전과 언어 사이의 정렬에 근본적인 한계가 존재합니다.
두 번째는 Native Multimodal with MoE입니다. 텍스트와 이미지를 처음부터 하나의 토큰 스트림으로 학습하는 early fusion 방식인데요, 여기에 Mixture of Experts를 결합해서 거대한 파라미터를 효율적으로 운용합니다. Qwen3.5, Kimi K2.5, Llama 4가 이 범주에 속합니다.
세 번째는 Monolithic Unibody입니다. ViT도 Adapter도 없이, 하나의 밀집(dense) 모델이 pixel과 word를 동시에 처리합니다. NEO가 이 접근의 선두주자인데요, 390M 예제만으로 학습하면서도 모듈형 VLM에 근접한 성능을 보여줬습니다(arXiv:2510.14979, 2025).
네 번째는 JEPA 패러다임입니다. Autoregressive 토큰 예측 자체를 벗어나서, 연속적인 임베딩 공간에서 예측하는 방식입니다. Yann LeCun이 제안한 JEPA 프레임워크를 vision-language로 확장한 VL-JEPA가 대표적입니다.
| 패러다임 | 대표 모델 | 장점 | 단점 |
|---|---|---|---|
| Modular ViT-MLP-LLM | InternVL3.5, LLaVA-OV-1.5 | 검증된 구조, 유연한 컴포넌트 교체 | 비전-언어 정렬 한계 |
| Native MoE | Qwen3.5, Kimi K2.5, Llama 4 | 깊은 멀티모달 융합, 효율적 스케일링 | 학습 비용 높음 |
| Unibody | NEO | 완전 통합, 적은 학습 데이터 | 지식 집약 태스크에서 약점 |
| JEPA | VL-JEPA | 효율적 디코딩, 다중 태스크 대응 | 생성 능력 제한 |
이 네 가지가 어떤 트레이드오프를 갖는지, 각 패러다임의 대표 모델을 하나씩 살펴보겠습니다.
핵심 모델 Deep Dive
InternVL3.5 — Cascade RL과 Visual Resolution Router
OpenGVLab(Shanghai AI Lab)이 2025년 8월에 발표한 InternVL3.5는 모듈형 아키텍처의 한계를 세 가지 혁신으로 돌파했습니다(arXiv:2508.18265, 2025).
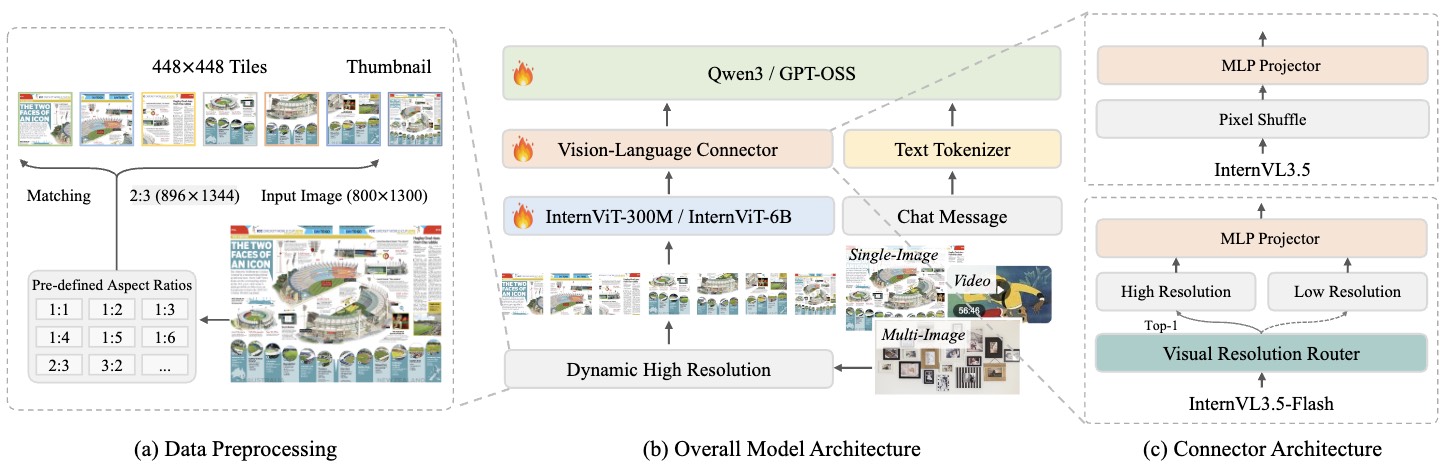
첫 번째 혁신은 Cascade RL(Cascade Reinforcement Learning)입니다. 기존 VLM의 정렬(alignment) 과정은 한 번의 RL로 끝나는 경우가 많았는데요, InternVL3.5는 이를 두 단계로 나눕니다. 먼저 Offline RL(Mixed Preference Optimization)로 안정적인 수렴 기반을 만들고, 그 위에 Online RL(GSPO)로 정밀하게 정렬합니다. 이 coarse-to-fine 전략으로 InternVL3 대비 전체 추론 성능이 16% 향상되었습니다.
두 번째는 Visual Resolution Router(ViR)입니다. 이미지의 모든 패치를 동일한 해상도로 처리하는 건 비효율적이거든요. 의미적으로 중요한 패치는 256 토큰으로 유지하고, 덜 중요한 패치는 64 토큰으로 압축합니다. 패치별 중요도를 동적으로 판단해서 시각 토큰을 최대 50% 절감하면서도, 성능 저하는 거의 없습니다.
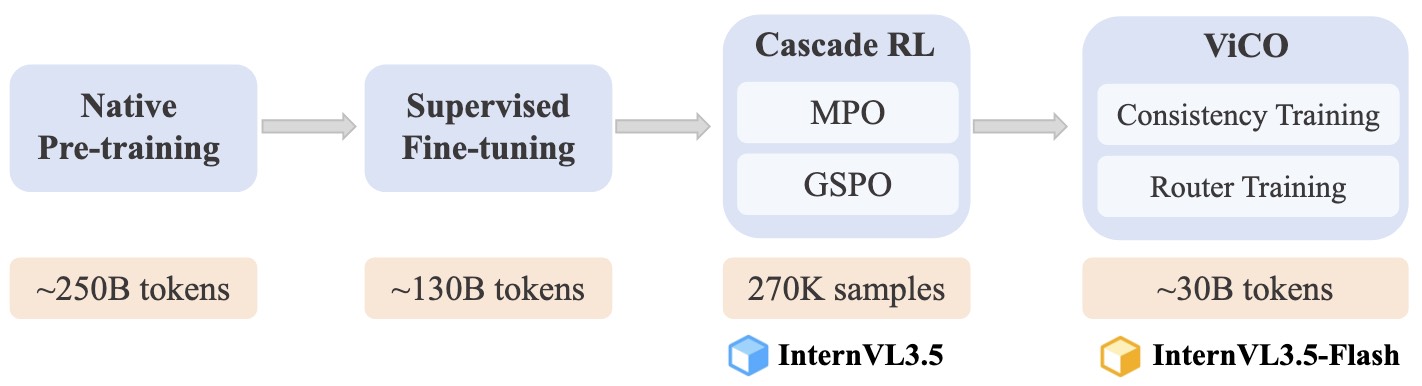
세 번째는 DvD(Decoupled Vision-Language Deployment)입니다. 비전 인코더와 LLM을 별도 GPU에 배치해서 비동기적으로 처리하는 방식인데요, 이를 통해 추론 속도를 4.05배 향상시켰습니다. 시각 인코딩이 끝날 때까지 LLM이 대기하는 병목을 제거한 겁니다.
모델 사이즈도 다양합니다. 1B부터 241B-A28B(MoE)까지 제공하는데, 241B 모델이 MMMU 77.7, 8B 모델이 MMMU 73.4를 기록했습니다. 8B 급에서 73.4라는 수치는 작은 모델치고 상당히 높은 성능입니다.
Qwen3-VL — DeepStack과 Thinking 변형
Alibaba Qwen 팀이 2025년 9월에 발표한 Qwen3-VL은 두 가지 점에서 주목할 만합니다(arXiv:2511.21631, 2025). DeepStack이라는 새로운 비전-언어 정렬 메커니즘, 그리고 모든 모델 사이즈에 Thinking 변형을 동시에 릴리스한 점입니다.
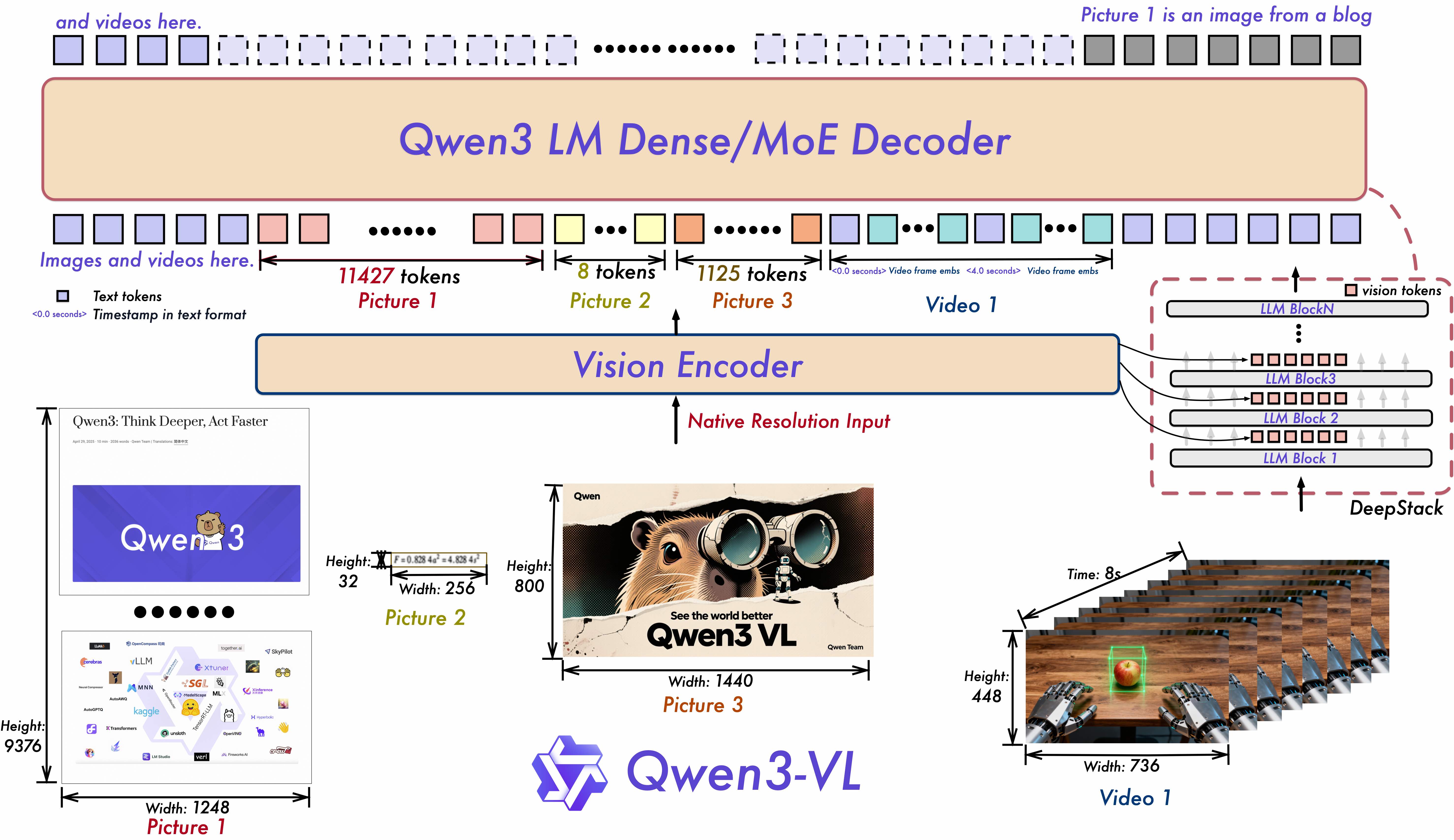
DeepStack의 아이디어는 직관적입니다. 기존 모듈형 VLM은 ViT의 최종 출력만 LLM에 전달하는데요, Qwen3-VL은 ViT의 다층(multi-level) 피처를 LLM의 대응하는 레이어에 직접 라우팅합니다. 초기 레이어의 저수준 시각 정보(에지, 텍스처)와 후기 레이어의 고수준 시맨틱 정보가 각각 적절한 LLM 레이어에 주입되는 구조입니다. 컨텍스트 길이를 늘리지 않고도 비전-언어 정렬을 강화할 수 있다는 게 핵심입니다.
또 하나 눈에 띄는 건 Enhanced interleaved-MRoPE입니다. 이미지와 비디오의 공간-시간 모델링에서 기존 MRoPE의 스펙트럼 불균형 문제를 해결했는데요, 256K 토큰의 네이티브 컨텍스트 윈도우에서 텍스트, 이미지, 비디오를 인터리브 방식으로 처리할 수 있습니다.
모델 라인업은 Dense(2B, 4B, 8B, 32B)와 MoE(30B-A3B, 235B-A22B) 두 축으로 구성됩니다. 그리고 모든 사이즈에 Instruct 변형과 Thinking 변형을 동시에 제공합니다. Thinking 변형은 확장된 Chain-of-Thought 추론을 수행하는데, 수학이나 코드 같은 복잡한 시각 추론 태스크에서 눈에 띄는 성능 향상을 보여줍니다.
플래그십 모델인 235B-A22B는 MMMU 80.6, MMMU-Pro 69.3을 기록했습니다.
Kimi K2.5 — 1T MoE와 Agent Swarm
Moonshot AI가 2026년 1월에 오픈소스로 공개한 Kimi K2.5는 규모와 기능 양쪽에서 인상적입니다(arXiv:2602.02276, 2026).
먼저 규모를 보면, 총 파라미터 1T(1조), 활성화 파라미터 32B인 MoE 아키텍처입니다. 61개 레이어에 384개의 Expert가 있고, 토큰당 8개가 선택됩니다. Multi-head Latent Attention(MLA)과 SwiGLU 활성화를 사용하고, 15T개의 혼합 시각-텍스트 토큰으로 사전학습했습니다.
비전 인코더는 MoonViT(400M params)인데요, 이미지, 비디오, PDF, 텍스트를 네이티브로 처리합니다. 시공간 풀링(spatial-temporal pooling)으로 시각 피처를 압축한 뒤 LLM에 전달하는 구조입니다.
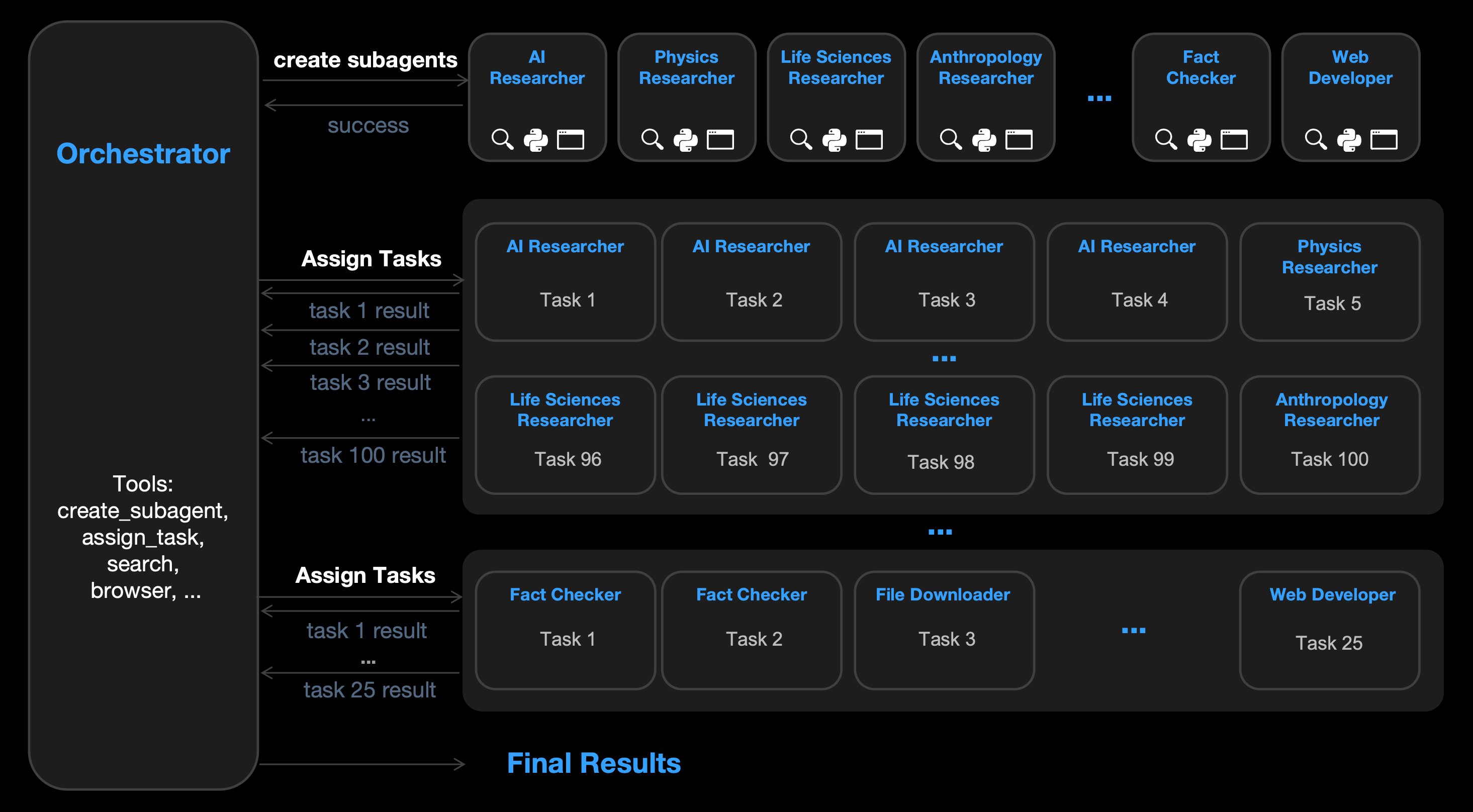
가장 흥미로운 건 Agent Swarm 기능입니다. 복잡한 태스크를 최대 100개의 서브 에이전트로 자동 분해해서 병렬 실행하는데, 총 1,500번의 tool call이 가능합니다(kimi.com/blog/kimi-k2-5, 2026). 단순한 병렬화가 아니라, PARL(Parallel Agent Reinforcement Learning)로 에이전트 오케스트레이션 자체를 학습했다는 점이 다릅니다. 그 결과 단일 에이전트 대비 실행 시간이 4.5배 단축되었습니다.
벤치마크에서도 Agent Swarm의 효과가 뚜렷합니다. BrowseComp에서 Swarm 모드가 78.4%, 표준 모드가 74.9%를 기록했고, MMMU-Pro는 78.5%입니다.
VLM이 단순히 "이미지를 이해하는 모델"에서 "이미지를 이해하고 행동까지 하는 에이전트"로 진화하고 있다는 걸 Kimi K2.5가 보여주고 있습니다.
NEO — Modular VLM 패러다임을 버리다
ViT-MLP-LLM이라는 모듈형 구조가 정말 최선일까요?
EvolvingLMMs Lab이 2025년 10월에 발표한 NEO는 이 질문에 정면으로 답합니다(arXiv:2510.14979, 2025). ICLR 2026에 Accept된 이 논문은 "Native VLM Primitives"라는 개념을 제안하는데요, ViT도 MLP Adapter도 없이 pixel과 word를 하나의 공유 시맨틱 공간에서 정렬하는 단일(unibody) 모델을 구축합니다.
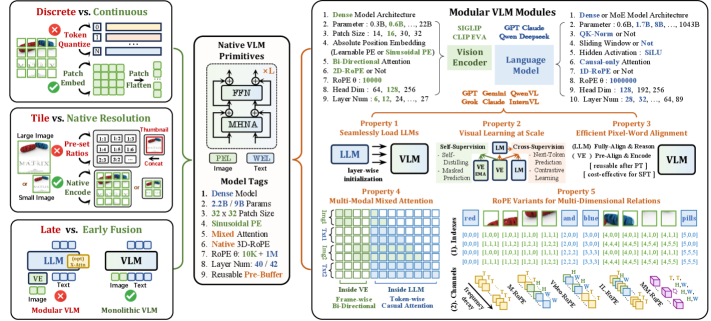
구체적으로 살펴보면, NEO는 Rotary Position Embedding을 비전과 언어 양쪽 모달리티에 동일하게 적용하고, modality-agnostic한 Pre-Buffer로 크로스모달 호환성을 확보합니다. 텍스트 토큰에는 autoregressive causal attention을, 시각 토큰에는 bidirectional attention을 적용하는 Dual Attention 구조를 사용합니다.
인상적인 건 학습 데이터 규모입니다. 기존 모듈형 VLM이 수십억 개의 image-text 쌍을 사용하는 것에 비해, NEO는 390M 예제만으로 학습했습니다. Qwen3-1.7B와 Qwen3-8B를 베이스로 한 NEO-2B와 NEO-9B가 공개되었고, NEO-9B는 MMMU 54.6을 기록했습니다.
54.6이라는 점수가 절대적으로 높지는 않습니다. InternVL3.5-8B의 73.4에 한참 못 미치거든요. 하지만 NEO의 의의는 벤치마크 점수 자체가 아닙니다. 사전 학습된 ViT 없이, 극소량의 데이터로 처음부터 끝까지 단일 모델로 학습해서 모듈형 VLM에 근접한 성능을 보였다는 점이 중요합니다. "ViT가 꼭 필요한가?"라는 근본적인 질문에 대한 첫 번째 실증적 답변인 셈입니다.
다만 지식 집약적인 태스크(MMMU)나 OCR 중심 태스크(InfoVQA, TextVQA)에서는 아직 모듈형 모델에 뒤처집니다. 사전 학습된 ViT가 수십억 장의 이미지에서 축적한 시각 지식을 390M 예제만으로 따라잡기는 어려운 것이 현실입니다.
VL-JEPA — Autoregressive를 넘어서
"다음 토큰을 예측한다"는 autoregressive 방식 말고, 다른 방법은 없을까요?
Meta FAIR와 HKUST가 2025년 12월에 발표한 VL-JEPA는 Yann LeCun이 제안한 JEPA(Joint Embedding Predictive Architecture) 프레임워크를 vision-language로 확장한 모델입니다(arXiv:2512.10942, 2025).
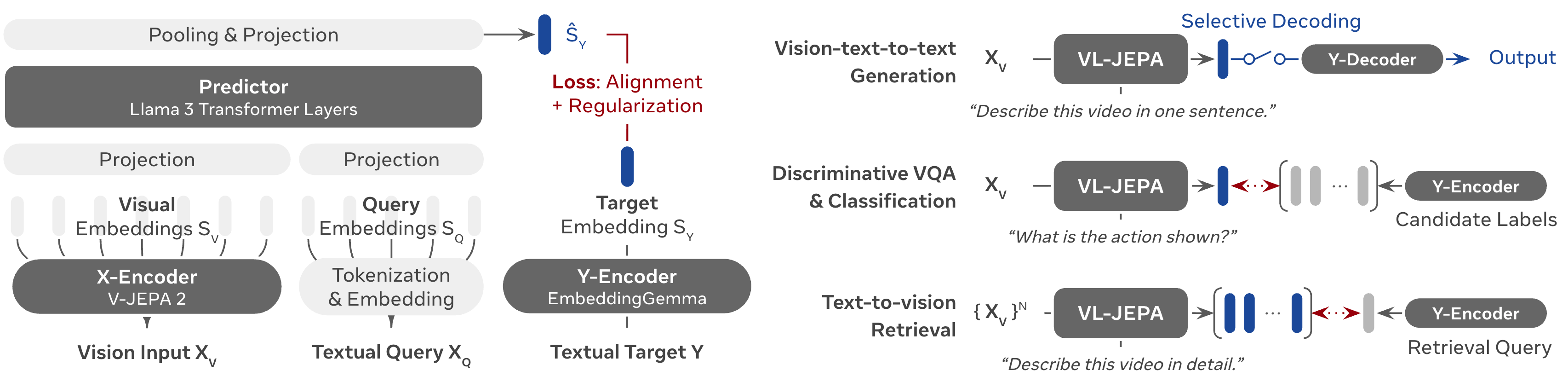
기존 VLM이 이미지를 보고 텍스트 토큰을 하나씩 생성하는 방식이라면, VL-JEPA는 타겟 텍스트의 연속 임베딩(continuous embedding)을 예측합니다. 이산 토큰이 아닌 추상적인 표현 공간에서 학습하기 때문에, 표면적인 언어 변동(같은 의미의 다른 표현)에 강건합니다.
실용적인 측면에서도 장점이 있습니다. Selective Decoding으로 디코딩 연산을 2.85배 절감하고, 학습 시에도 기존 토큰 기반 VLM 대비 학습 파라미터가 50% 적습니다. 1.6B 파라미터로 CLIP, SigLIP2, Perception Encoder를 비디오 분류/검색 태스크에서 능가했습니다.
물론 한계도 있습니다. 연속 임베딩 예측 방식 특성상 자유로운 텍스트 생성에는 제약이 있고, 현재는 분류, 검색, 판별형 VQA 같은 태스크에 특화되어 있습니다. 하지만 autoregressive가 유일한 정답이 아닐 수 있다는 가능성을 보여준 것만으로도 의미가 큽니다.
LLaVA-OneVision-1.5 — $16K로 경쟁력 있는 VLM 학습
VLM 학습에 수십만 달러가 필요하다는 통념을 깨뜨린 모델입니다.
EvolvingLMMs Lab이 2025년 9월에 발표한 LLaVA-OneVision-1.5는 A800 GPU 128대로 약 $16,000의 비용에 학습되었습니다(arXiv:2509.23661, 2025). 데이터, 코드, 가중치 모두 완전 공개입니다.
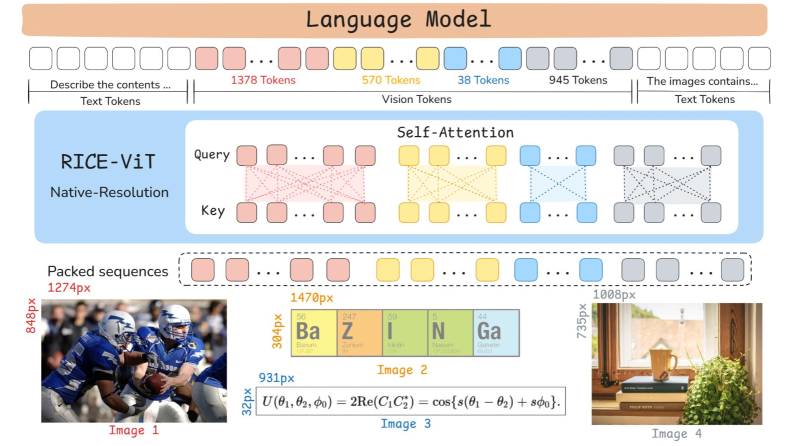
핵심 혁신은 RICE-ViT(Region-level Image Cluster Enriched Vision Transformer)입니다. 450M 이미지와 2.4B 후보 영역으로 학습된 비전 인코더인데요, 이미지 전체를 한 번에 인코딩하는 기존 ViT와 달리 영역(region) 수준의 시맨틱 표현을 강화했습니다. 네이티브 해상도 적응도 지원합니다.
학습은 3단계로 진행됩니다. Stage-1에서 Language-Image Alignment, Stage-1.5에서 85M 개념 균형 데이터셋으로 지식 학습, Stage-2에서 22M 큐레이션된 인스트럭션 데이터로 튜닝합니다. 마지막에 경량 RL 단계를 추가했습니다.
결과도 인상적입니다. 8B 모델이 Qwen2.5-VL-7B를 27개 벤치마크 중 18개에서 초과했고, 4B 모델은 Qwen2.5-VL-3B를 27개 벤치마크 전부에서 넘어섰습니다. $16K라는 학습 비용을 생각하면 놀라운 수치입니다.
LLaVA-OneVision-1.5가 보여준 건 "VLM 학습의 민주화"입니다. 소규모 연구 그룹이나 스타트업도 경쟁력 있는 VLM을 처음부터 학습할 수 있다는 가능성을 열었습니다.
벤치마크 비교
앞서 다룬 모델들을 포함해서, 2026년 2월 현재 주요 Vision LLM의 벤치마크 성능을 한 테이블로 정리합니다.
| 모델 | 타입 | Total Params | Active Params | MMMU | MMMU-Pro |
|---|---|---|---|---|---|
| Qwen3.5-397B-A17B | Open | 397B | 17B | 85.0 | - |
| GPT-5 | Closed | - | - | 84.2 | ~66 |
| Gemini 3 Pro | Closed | - | - | - | 81.0 |
| Qwen3-VL-235B-A22B | Open | 235B | 22B | 80.6 | 69.3 |
| Kimi K2.5 | Open | 1T | 32B | - | 78.5 |
| InternVL3.5-241B-A28B | Open | 241B | 28B | 77.7 | - |
| InternVL3.5-8B | Open | 8B | 8B | 73.4 | - |
| NEO-9B | Open | 9B | 9B | 54.6 | - |
여기서 주목할 점이 두 가지 있습니다.
첫째, Active Params 대비 성능입니다. Qwen3.5는 총 397B 파라미터지만 실제 활성화되는 건 17B에 불과합니다. 17B로 MMMU 85.0을 달성했다는 건, MoE의 효율성이 얼마나 극적인지를 보여줍니다. Kimi K2.5도 마찬가지로 1T 중 32B만 활성화되어 MMMU-Pro 78.5를 기록합니다.
둘째, MMMU와 MMMU-Pro의 차이입니다. MMMU는 대학 수준의 멀티모달 이해력을 측정하는 벤치마크이고, MMMU-Pro는 이를 더 어렵게 만든 버전입니다. 선택지를 증강하고 더 까다로운 문제를 포함해서, 모델 간 성능 차이가 더 뚜렷하게 드러납니다. 같은 모델이라도 MMMU와 MMMU-Pro 점수 사이에 상당한 차이가 있는 걸 볼 수 있는데요, 이는 현재 VLM이 "쉬운 멀티모달 문제"는 잘 풀지만 "어려운 멀티모달 추론"에서는 아직 개선 여지가 크다는 뜻입니다.
오픈소스 모델들이 클로즈드 모델을 따라잡는 속도도 눈여겨볼 만합니다. 2024년 말에는 GPT-4V와 오픈소스 최고 성능 사이에 10점 이상 차이가 있었는데, 지금은 오히려 역전된 상황입니다.
핵심 트렌드 5가지
1. MoE가 VLM의 표준이 되다
위 테이블을 다시 보면, 상위권 모델 대부분이 MoE입니다. Qwen3.5(397B/17B), Kimi K2.5(1T/32B), Qwen3-VL(235B/22B), InternVL3.5-241B(241B/28B), 그리고 Meta의 Llama 4 Maverick까지.
SC'25 워크숍에서 발표된 MoE-Inference-Bench에 따르면, MoE는 동일 품질의 Dense 모델 대비 학습 처리량이 5배 빠르고, 추론 처리량은 50-80% 높습니다(arXiv:2508.17467, 2025). MoE-LLaVA 연구에서는 3B sparse 모델이 LLaVA-1.5-7B dense 모델의 성능을 매칭하면서, V100 8장으로 2일 만에 학습 가능하다는 걸 보여줬습니다(arXiv:2401.15947, 2024).
VLM이 다루는 모달리티가 늘어나면서(이미지, 비디오, 오디오, PDF 등), 모든 모달리티를 dense 모델로 처리하는 건 비현실적입니다. MoE가 표준이 된 건 필연적인 흐름입니다.
2. Native Multimodal로의 전환
"비전 어댑터를 붙이는" 시대에서 "처음부터 멀티모달로 학습하는" 시대로 전환이 진행 중입니다.
Qwen3.5는 텍스트, 이미지, 비디오 토큰을 구분 없이 하나의 시퀀스로 넣어서 처음부터 학습합니다. Llama 4도 early fusion 방식을 채택했고, Kimi K2.5는 15T개의 혼합 시각-텍스트 토큰으로 사전학습했습니다. NEO는 이를 극단까지 밀어붙여서 ViT 자체를 없앴습니다.
왜 이런 전환이 일어나고 있을까요? 모듈형 구조에서는 비전 인코더가 "본 것"을 LLM이 이해할 수 있는 표현으로 "번역"해야 합니다. 이 번역 과정에서 정보 손실이 발생하고, 비전과 언어 사이의 정렬에 근본적인 한계가 생깁니다. Native multimodal 학습은 이 번역 단계를 제거해서 더 깊은 수준의 멀티모달 이해를 가능하게 합니다.
3. Thinking/Reasoning VLM의 등장
텍스트 LLM에서 Chain-of-Thought가 표준이 된 것처럼, VLM에서도 "생각하는 모델"이 등장하고 있습니다.
Qwen3-VL이 대표적입니다. 모든 모델 사이즈(2B~235B)에 Instruct 변형과 Thinking 변형을 동시에 릴리스했는데요, Thinking 변형은 확장된 Chain-of-Thought로 복잡한 시각 추론 문제를 단계적으로 풀어냅니다. 수학 문제가 담긴 이미지, 복잡한 차트 해석, 다단계 논리 추론 같은 태스크에서 특히 효과적입니다.
InternVL3.5도 Cascade RL을 통해 추론 성능을 16% 끌어올렸고, Latent CoT(arXiv:2510.23925, 2025) 연구는 변분추론(variational inference)을 활용한 시각 추론 접근을 제안해서 7개 추론 벤치마크에서 SOTA를 달성했습니다.
시각 정보가 포함된 추론은 텍스트만의 추론보다 훨씬 복잡합니다. 이미지 속 관계, 공간 배치, 시각적 맥락을 모두 고려해야 하기 때문입니다. Thinking VLM은 이 복잡성을 체계적으로 다루려는 시도입니다.
4. 효율성 혁신 경쟁
VLM의 가장 큰 병목은 시각 토큰 수입니다. 이미지 하나를 1024개 패치로 나누면 1024개의 토큰이 LLM에 입력되는데, 여러 장의 이미지나 비디오를 처리하면 토큰 수가 급격히 늘어납니다.
이 문제에 대한 해법이 여러 방향에서 나오고 있습니다. InternVL3.5의 Visual Resolution Router는 패치별 중요도에 따라 시각 토큰을 50% 절감합니다. Kimi-VL의 MoonViT는 고정 그리드가 아닌 네이티브 해상도로 이미지를 처리해서 일반적인 이미지에서 불필요한 연산을 줄입니다. InternVL3.5의 DvD는 비전-언어를 비동기 배치해서 4.05배의 속도향상을 이끌어냈고, VL-JEPA는 디코딩 연산 자체를 2.85배 줄였습니다.
효율성 혁신은 단순히 "더 빠르게"가 아니라 "더 큰 모델을 실용적으로 쓸 수 있게"하는 데 의미가 있습니다. MoE로 파라미터 활성화를 줄이고, ViR로 시각 토큰을 절감하고, DvD로 배포 효율을 높이는 — 이 조합이 1T 파라미터 모델을 실제로 사용 가능하게 만드는 기반입니다.
5. 민주화 — $16K로 경쟁력 있는 VLM
LLaVA-OneVision-1.5가 $16,000에 경쟁력 있는 VLM을 학습할 수 있음을 보여줬습니다. 데이터, 코드, 가중치가 모두 공개되어 있어서 누구든 재현할 수 있습니다.
이 민주화의 배경에는 시장의 빠른 성장이 있습니다. Precedence Research에 따르면 VLM 시장 규모는 2025년 $3.74B에서 2035년 $35.96B로 성장이 전망됩니다(25.41% CAGR)(Precedence Research, 2025). Gartner는 2030년까지 엔터프라이즈 소프트웨어의 80%가 멀티모달을 탑재할 것으로 예측하는데, 2024년에는 이 비율이 10% 미만이었습니다(Gartner, 2025).
시장이 커지면 다양한 도메인에서 특화된 VLM이 필요해집니다. 그때마다 수십만 달러의 학습 비용이 들면 진입 장벽이 너무 높습니다. $16K라는 비용은 대학 연구실이나 초기 스타트업도 VLM 학습에 도전할 수 있다는 뜻이고, 이것이 생태계 전체의 혁신 속도를 높이는 원동력이 됩니다.
Qwen3.5 — 모든 트렌드의 결정체
2026년 2월 16일에 발표된 Qwen3.5는 위에서 다룬 다섯 가지 트렌드를 하나의 모델에 집약합니다(Qwen Research, 2026).

Native Multimodal입니다. Qwen3까지만 해도 텍스트와 비전이 별도 라인(Qwen3 + Qwen3-VL)이었는데, Qwen3.5는 처음부터 텍스트, 이미지, 비디오 토큰을 통합해서 학습합니다. 비전 어댑터를 붙이는 방식이 아니라 early fusion으로 구현된 진정한 네이티브 멀티모달입니다.
MoE입니다. 플래그십 모델은 397B 총 파라미터에 17B 활성화인데요, 122B-A10B, 35B-A3B MoE 변형과 27B dense 변형도 함께 제공됩니다.
아키텍처 혁신도 있습니다. Gated Delta Networks라는 linear attention 변형을 도입했는데요, 기존 트랜스포머의 quadratic attention 비용을 줄이면서도 성능을 유지합니다. 262K 토큰의 네이티브 컨텍스트 윈도우를 지원하고, 201개 언어를 처리합니다.
그리고 결과가 놀랍습니다. MMMU 85.0으로 GPT-5(84.2)를 넘어서며, 오픈소스 모델이 클로즈드 모델을 추월한 최초의 사례가 되었습니다. Qwen3-VL의 비전 벤치마크도 전반적으로 초과합니다.
Qwen3.5가 중요한 이유는 개별 벤치마크 점수가 아닙니다. "네이티브 멀티모달 + MoE + 새로운 어텐션 메커니즘"이라는 조합이 VLM의 다음 세대 아키텍처로 수렴하고 있다는 신호입니다. InternVL3.5가 모듈형의 극한을 보여줬다면, Qwen3.5는 네이티브 멀티모달의 극한을 보여주고 있습니다.
앞으로의 방향
여기서 한 걸음 더 나아가면 어떤 미래가 펼쳐질까요?
가장 활발한 방향은 Vision-Language-Action(VLA)입니다. 이미지를 "이해"하는 것에서 그치지 않고, 이해한 내용을 바탕으로 "행동"까지 하는 모델입니다. 로봇이 사물을 인식하고 집어 올리거나, 자율주행차가 도로 상황을 보고 조향하거나, GUI 에이전트가 화면을 보고 클릭하는 것이 VLA의 영역입니다. ICLR 2026에만 VLA 관련 논문이 164편 제출되었다는 사실이 학계의 관심을 반영합니다.
이해와 생성의 통합도 진행 중입니다. 현재 대부분의 VLM은 이미지를 "이해"하지만 "생성"하지는 못합니다. DeepSeek의 Janus-Pro는 decoupled visual encoding으로 이해와 생성을 하나의 모델에 통합하려 했고, Show-o2는 autoregressive와 flow matching을 3D causal VAE 공간에서 결합했습니다. 하나의 모델이 이미지를 보고, 이해하고, 새로운 이미지를 생성하는 미래가 가까워지고 있습니다.
Kimi K2.5의 Agent Swarm이 보여준 "VLM의 에이전트화"도 주목할 방향입니다. VLM이 단일 쿼리에 응답하는 것을 넘어, 복잡한 태스크를 스스로 분해하고 도구를 사용하고 병렬로 실행하는 방식입니다. LLM 서빙 최적화와 어텐션 연산 최적화의 발전이 이런 에이전트 시나리오를 뒷받침합니다.
그리고 VL-JEPA가 던진 질문 — "autoregressive가 유일한 정답인가?" — 은 앞으로 더 많은 탐구가 필요한 영역입니다. 연속 임베딩 예측이 특정 태스크에서 이미 우위를 보이고 있으니, 이 방향이 범용 VLM으로까지 확장될 수 있을지 지켜볼 만합니다.
FAQ
Vision LLM(VLM)이란 무엇인가요?
Vision LLM은 텍스트뿐 아니라 이미지, 비디오 등 시각 정보를 함께 이해하고 추론하는 대규모 언어 모델입니다. 비전 인코더를 결합하거나, 처음부터 멀티모달로 학습해서 시각 질의응답, 문서 이해, 차트 분석 같은 태스크를 수행합니다. 2025년 기준 주요 학회 논문의 40%가 VLM 관련입니다(arXiv:2510.09586, 2025).
2026년 현재 가장 성능이 좋은 오픈소스 VLM은?
2026년 2월 기준, MMMU 벤치마크에서 Qwen3.5-397B-A17B가 85.0으로 오픈소스 1위입니다(Qwen Research, 2026). 클로즈드 모델인 GPT-5(84.2)를 넘어선 최초의 오픈소스 모델이기도 합니다. 8B급에서는 InternVL3.5-8B(MMMU 73.4)가 가장 높은 성능을 보입니다.
MMMU와 MMMU-Pro 벤치마크의 차이는?
MMMU는 대학 수준의 멀티모달 이해력을 11,550개 문제로 측정하는 벤치마크이고, MMMU-Pro는 3,460개의 더 어려운 문제로 구성된 상위 버전입니다. MMMU-Pro는 증강된 선택지와 복합적인 추론을 요구해서, 같은 모델이라도 MMMU 대비 점수가 크게 낮게 나옵니다. 2026년 2월 기준 MMMU-Pro 최고 성능은 Gemini 3 Pro의 81.0%입니다.
MoE 아키텍처가 VLM에서 중요한 이유는?
MoE는 전체 파라미터 중 일부만 활성화하여 추론하므로, 거대한 모델 용량에 비해 실제 연산 비용이 적습니다. Dense 모델 대비 5배 빠른 학습과 50-80% 높은 추론 처리량이 보고되었습니다(arXiv:2508.17467, 2025). Kimi K2.5(1T/32B), Qwen3.5(397B/17B) 같은 모델이 이 효율성 덕분에 실용적으로 배포 가능합니다.
Vision LLM을 직접 사용해보려면 어떻게 시작하나요?
Hugging Face Transformers 라이브러리로 InternVL3.5, Qwen3-VL 등을 바로 추론할 수 있습니다. 8B급 모델은 단일 GPU(24GB VRAM)에서도 실행 가능합니다. 더 효율적인 서빙이 필요하면 vLLM이나 SGLang 같은 프레임워크를 추천하는데요, 조합 이미지 검색처럼 특화된 태스크에 활용할 수도 있습니다.
References
- InternVL3.5: Advancing Versatility, Reasoning, and Efficiency — arXiv:2508.18265, Aug 2025
- Qwen3-VL Technical Report — arXiv:2511.21631, Nov 2025
- Kimi K2.5 Technical Report — arXiv:2602.02276, Feb 2026
- NEO: From Pixels to Words — Native Vision-Language Primitives at Scale — arXiv:2510.14979, Oct 2025
- VL-JEPA: Joint Embedding Predictive Architecture for Vision-Language — arXiv:2512.10942, Dec 2025
- LLaVA-OneVision-1.5: Improved Baselines for Visual Instruction Tuning — arXiv:2509.23661, Sep 2025
- Qwen3.5: Towards Native Multimodal Agents — Qwen Research, Feb 2026
- Vision Language Models: A Survey of 26K Papers — arXiv:2510.09586, Oct 2025
- Latent Chain-of-Thought for Visual Reasoning — arXiv:2510.23925, Oct 2025
- MoE-Inference-Bench — arXiv:2508.17467, Aug 2025 (SC'25)
- MoE-LLaVA: Mixture of Experts for Large Vision-Language Models — arXiv:2401.15947, Jan 2024
- VLM Market Report — Precedence Research, 2025
- Multimodal Enterprise Prediction — Gartner, Jul 2025
- Kimi K2.5 Official Blog — kimi.com/blog/kimi-k2-5, 2026