핵심 요약
- ColPali는 문서 페이지를 이미지 그대로 인코딩하여 OCR 파이프라인 없이 검색하는 VLM 기반 모델입니다 (ICLR 2025)
- Late Interaction(MaxSim)으로 쿼리 토큰과 문서 패치 간 세밀한 매칭을 수행합니다
- ViDoRe 벤치마크에서 NDCG@5 81.3을 기록하며 기존 OCR 파이프라인(67.0)을 크게 앞섰습니다
- RAG 시장은 2025년 USD 1.94B에서 2030년 USD 9.86B로 성장이 전망됩니다 (MarketsandMarkets, 2025)
Intro
ColPali는 문서 페이지를 이미지 그대로 인코딩하여 OCR 파이프라인 없이 검색하는 ICLR 2025 모델로, ViDoRe 벤치마크에서 NDCG@5 81.3을 기록하며 기존 OCR 기반 최고 성능(67.0)을 14.3p 앞섰습니다(ICLR 2025). OCR 오류가 RAG 정답률을 25.8% 감소시킨다는 연구 결과(arXiv, 2024)를 고려하면, 시각 문서 검색의 패러다임 전환이 필요한 시점입니다.
이전 글에서 조합 이미지 검색(CIR)으로 "이 소파를 원목으로 바꿔서 찾아줘"라는 쿼리를 처리하는 방법을 다뤘습니다. 상품을 찾는 건 해결했는데, 그 상품이 실제로 사용된 인테리어 후기를 찾으려면 어떻게 해야 할까요?
웹사이트에서 "화이트 톤 주방 리모델링" 후기를 검색한다고 칩시다. 텍스트 리뷰는 잔뜩 나오는데, 우리가 원하는 건 사진 속 주방 레이아웃과 사용된 자재 정보가 함께 보이는 후기입니다. 사진 안에 적힌 자재 이름, 가격표, 시공 도면 같은 정보는 텍스트 검색에 걸리지 않습니다. 사진을 일일이 열어봐야 합니다.
이런 인테리어 후기는 텍스트와 사진이 복잡하게 얽힌 "시각적으로 풍부한 문서(Visually Rich Document)"입니다. 기존 검색 시스템이 이런 문서를 처리하려면 OCR로 사진 속 텍스트를 추출하고, 레이아웃을 분석하고, 청킹하고, 임베딩을 만드는 다단계 파이프라인이 필요합니다. 문제는 이 파이프라인이 구조적으로 부서지기 쉽다는 겁니다.
ICLR 2025에서 발표된 ColPali는 이 문제를 근본적으로 다르게 접근합니다. 문서 페이지를 이미지 그대로 인코딩해서, OCR 없이 검색하는 방법입니다. 이 글에서는 ColPali의 기술적 접근법과, 이커머스 UGC 검색에서 왜 이것이 중요한지를 정리해 보겠습니다.
OCR 파이프라인은 왜 부서지는가?
기존 문서 검색의 표준 파이프라인은 이렇습니다: PDF나 이미지를 OCR로 텍스트 추출 → 레이아웃 감지 → 청크 분할 → 텍스트 임베딩 → 벡터 검색. 각 단계가 이전 단계의 출력에 의존하는 직렬 구조입니다.
이 파이프라인에는 세 가지 구조적 약점이 있습니다.
첫째, OCR 오류가 전파됩니다. 표, 차트, 손글씨에서 특히 심각한데요, "OCR Hinders RAG" 논문(ICCV 2025 accepted)에 따르면 현존하는 어떤 OCR 솔루션도 RAG용 고품질 지식 베이스를 구축하기에 충분하지 않으며, OCR 오류가 RAG 시스템의 정답률을 25.8% 감소시킵니다(arXiv, 2024). 최고 성능의 Azure OCR조차 완벽한 텍스트 대비 NDCG@5가 4.5% 낮습니다(Mixedbread, 2025).
둘째, 시각적 맥락이 소실됩니다. 이미지나 표가 지닌 본연의 시각적 맥락이 텍스트화 과정에서 증발합니다. 인테리어 사진 속 주방 레이아웃, 조명 분위기, 자재의 질감 같은 정보는 OCR이 추출할 수 없습니다.
셋째, 다단계 처리의 복잡도입니다. 각 단계마다 별도의 모델과 설정이 필요하고, 어느 한 단계가 실패하면 전체 파이프라인이 무너집니다. 유지보수 비용도 단계 수에 비례해서 늘어납니다.

기존 검색 방식과 뭐가 다른가?
| 구분 | 텍스트 검색 | OCR + 텍스트 검색 | ColPali 시각 문서 검색 |
|---|---|---|---|
| 입력 | 키워드 | 문서 이미지 → OCR → 텍스트 | 문서 이미지 (직접) |
| 처리 단계 | 1단계 | 3-4단계 | 1단계 |
| 시각적 맥락 | 없음 | 부분적 (텍스트만) | 완전 보존 |
| 표/차트 이해 | 불가 | 매우 제한적 | 가능 |
| 오류 전파 | 낮음 | 높음 (OCR → 청킹 → 임베딩) | 없음 |
인테리어 플랫폼의 UGC는 전형적인 시각적 문서입니다. 사용자가 올리는 수백만 건의 후기에는 텍스트 리뷰, 시공 사진, 자재 정보표, 가격 비교 이미지가 뒤섞여 있습니다. 이런 콘텐츠를 OCR 파이프라인으로 처리하는 건 구조적으로 한계가 있습니다.
후기 상호작용(Late Interaction)은 어떻게 작동하는가?
ColPali를 이해하려면 먼저 Late Interaction을 알아야 합니다. 검색 시스템에서 쿼리와 문서가 상호작용하는 방식은 크게 세 가지로 나뉩니다.
첫 번째는 No-interaction(Bi-encoder) 방식입니다. 쿼리와 문서를 각각 하나의 벡터로 압축한 뒤 코사인 유사도를 계산합니다. CLIP이 대표적인데요, 빠르지만 모든 정보를 단일 벡터에 우겨넣다 보니 세밀한 매칭이 어렵습니다.
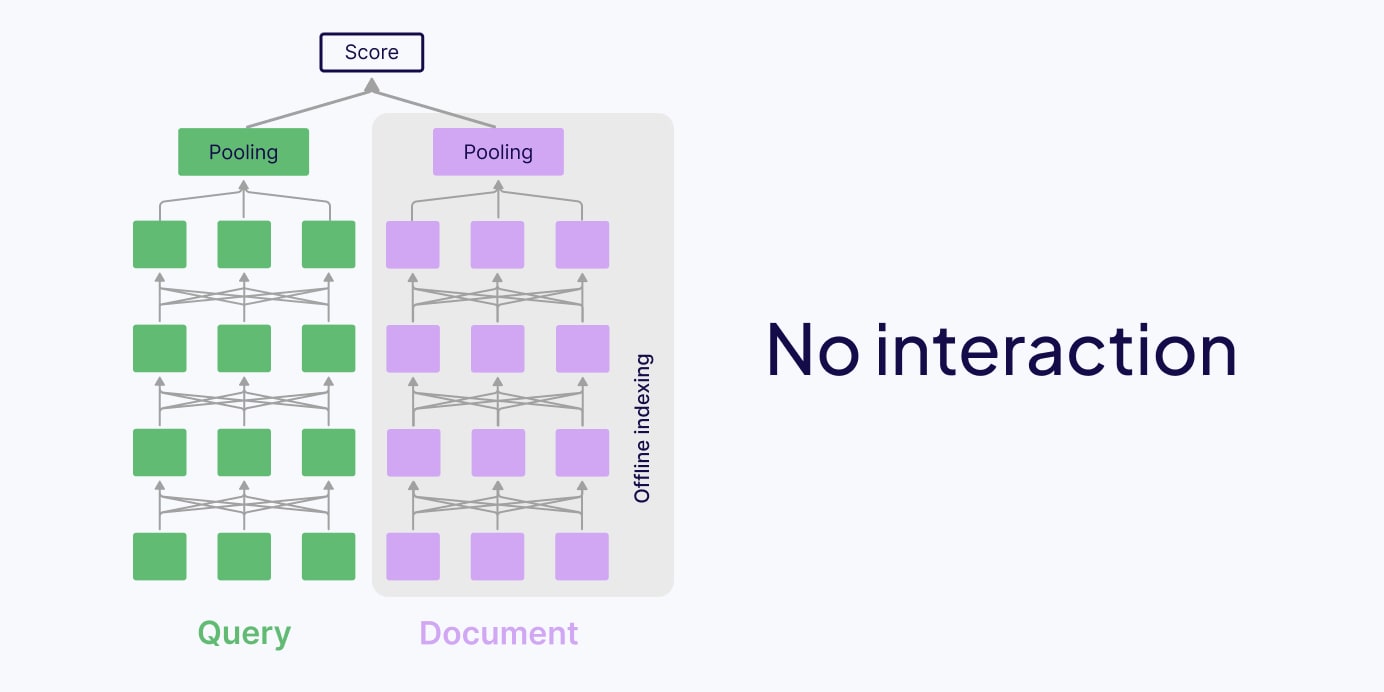
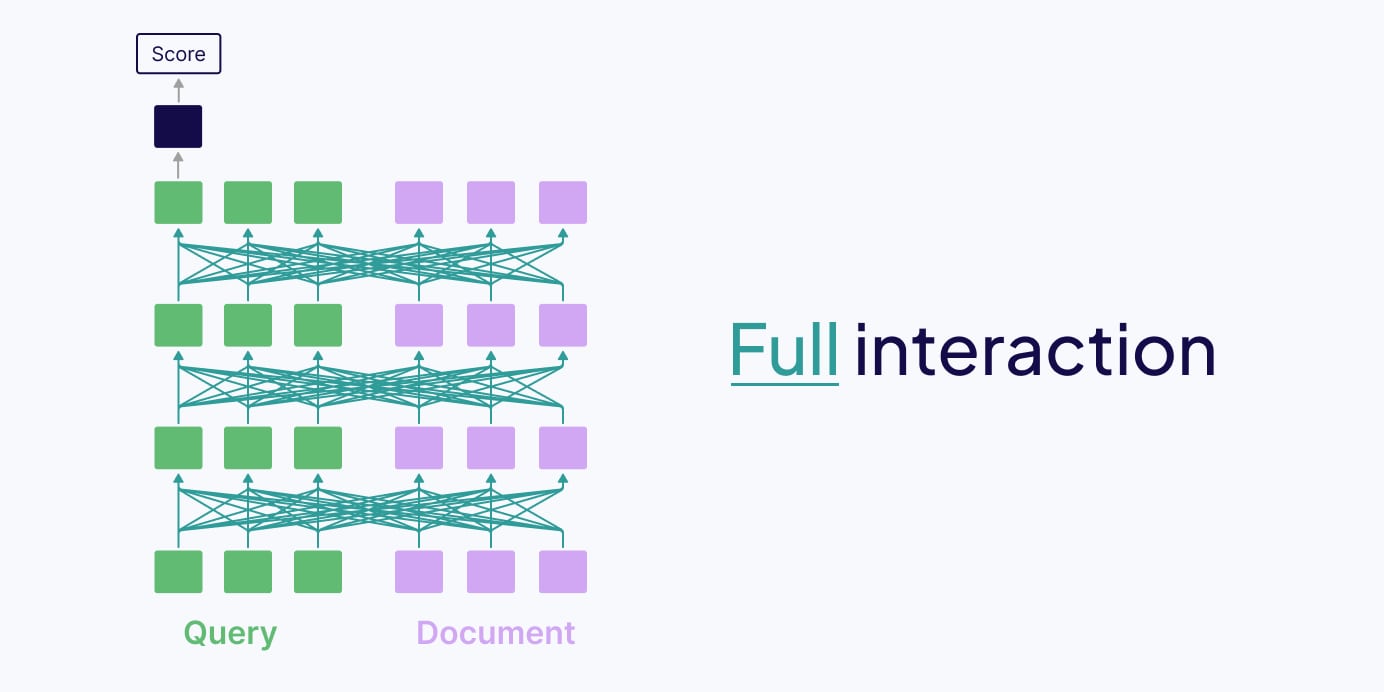
두 번째는 Full-interaction(Cross-encoder) 방식입니다. 쿼리와 문서의 모든 토큰 쌍에 대해 어텐션을 계산합니다. 정확하지만, 모든 쿼리-문서 조합을 실시간으로 연산해야 해서 대규모 검색에는 비현실적입니다.
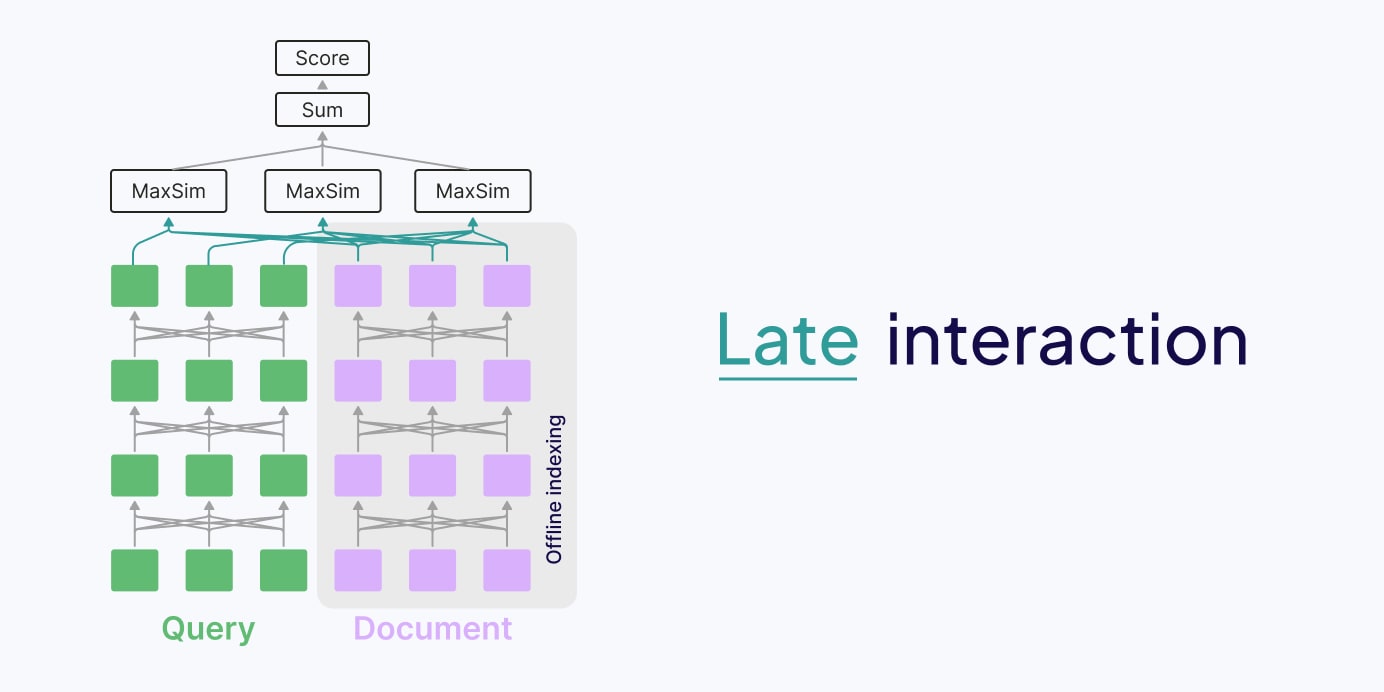
세 번째가 Late Interaction입니다. 쿼리와 문서를 각각 독립적으로 인코딩하되, 단일 벡터가 아닌 토큰 수준의 다중 벡터를 유지합니다. 검색 시점에서 MaxSim(Maximum Similarity) 연산으로 세밀한 매칭을 수행합니다. "빠른 인코딩"과 "정확한 매칭"의 균형점이라고 할 수 있습니다.
MaxSim은 어떻게 계산하는가?
MaxSim의 직관은 간단합니다. 쿼리의 각 토큰에 대해, 문서의 모든 토큰(또는 패치) 중 가장 유사한 것을 찾습니다. 그 최대 유사도를 모든 쿼리 토큰에 대해 합산한 값이 최종 점수입니다.
예를 들어 "화이트 톤 주방"이라는 쿼리가 있으면, "화이트"는 사진 속 흰색 벽면 패치와, "주방"은 싱크대 영역 패치와 가장 높은 유사도를 기록합니다. 각 쿼리 토큰이 문서에서 가장 관련 있는 영역을 독립적으로 찾아내는 구조입니다.
이 방식의 장점은 문서 임베딩을 오프라인으로 미리 계산해둘 수 있다는 점입니다. 검색 시점에는 쿼리 인코딩 + MaxSim 연산만 하면 되니, Cross-encoder 대비 훨씬 빠릅니다. ColBERT(2020)가 텍스트 검색에서 이 패러다임을 처음 제안했고, ColPali가 이를 멀티모달(이미지 패치)로 확장한 겁니다.
ColPali: 문서 페이지를 이미지 그대로 인코딩하다 (ICLR 2025)
ColPali의 핵심 아이디어는 단순합니다. 문서 페이지를 텍스트로 변환하지 말고, 이미지 그대로 인코딩하자. OCR, 레이아웃 감지, 청킹 — 이 모든 단계를 건너뛰고, Vision Transformer 기반의 VLM(Vision Language Model)이 페이지 이미지를 직접 다중 벡터 임베딩으로 변환합니다.
아키텍처를 구체적으로 보겠습니다.
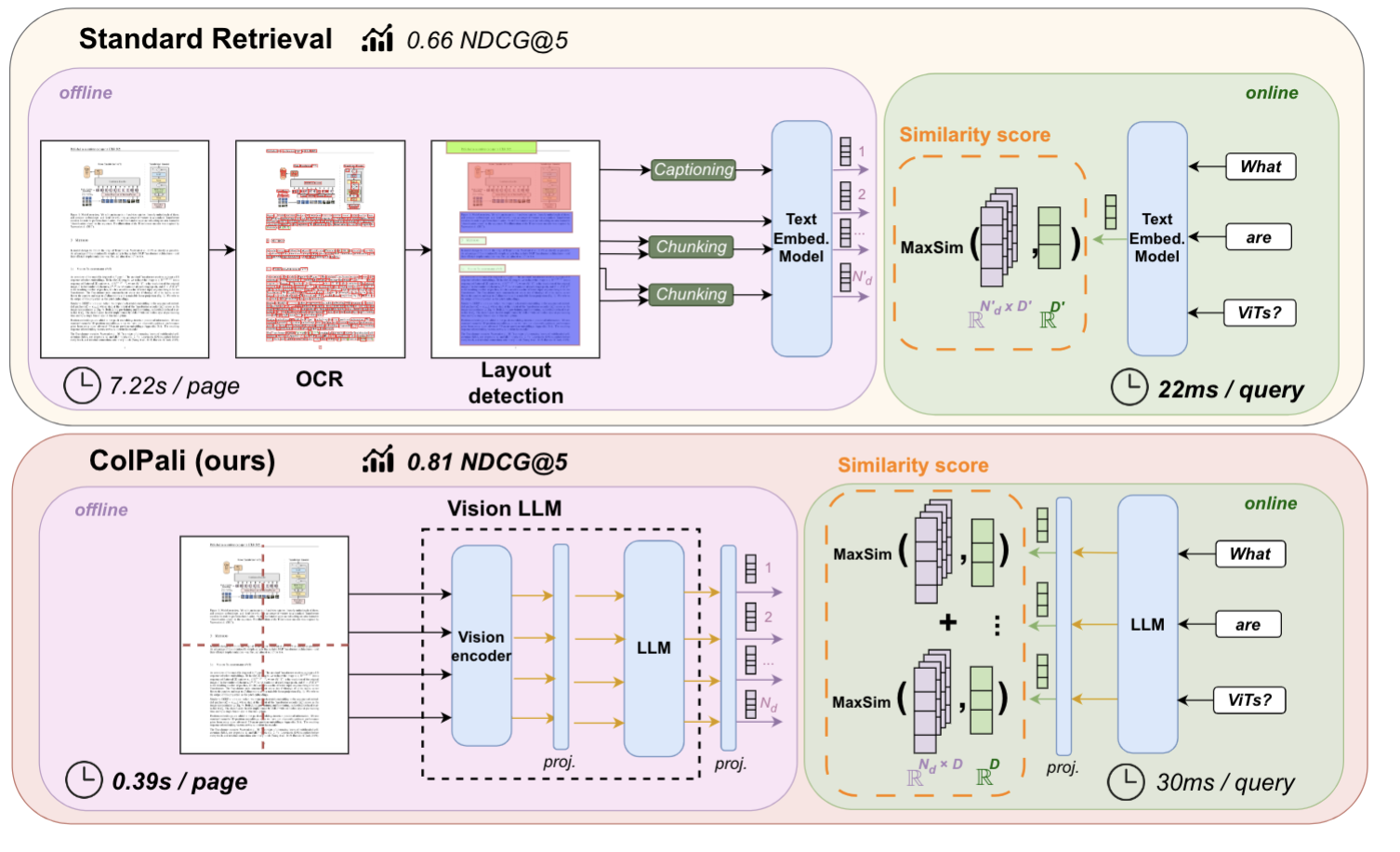
- 문서 페이지 이미지를 PaliGemma-3B(Vision Language Model)에 입력합니다
- 이미지가 1024개의 패치로 분할되고, 각 패치가 128차원 임베딩으로 변환됩니다
- 쿼리 텍스트도 같은 모델을 통해 토큰별 128차원 임베딩으로 변환됩니다
- 검색 시점에서 쿼리 토큰과 문서 패치 간 MaxSim을 계산합니다
이전 글에서 아키텍처 2단계로 "프록시 이미지와 타겟 데이터베이스 이미지를 VLM(PaliGemma-3B)으로 다중 벡터 임베딩으로 변환합니다"라고 언급했는데요, 바로 이 ColPali의 인코딩 방식을 말한 것이었습니다.
학습은 127,460개의 쿼리-페이지 쌍으로 대비 학습(contrastive loss)을 수행합니다. 학습 데이터 규모가 크지 않은데도 성능이 높은 이유는, PaliGemma-3B의 사전 학습된 시각-언어 이해 능력을 Late Interaction으로 효과적으로 활용하기 때문입니다.
ViDoRe 벤치마크에서 무엇을 입증했나?
ViDoRe(Visual Document Retrieval Benchmark)는 ColPali 팀이 함께 공개한 시각 문서 검색 벤치마크입니다. 학술 논문, 보고서, 인포그래픽, 표 등 다양한 문서 유형을 포함하고 있어서, 시각 문서 검색 모델의 종합적인 평가가 가능합니다.
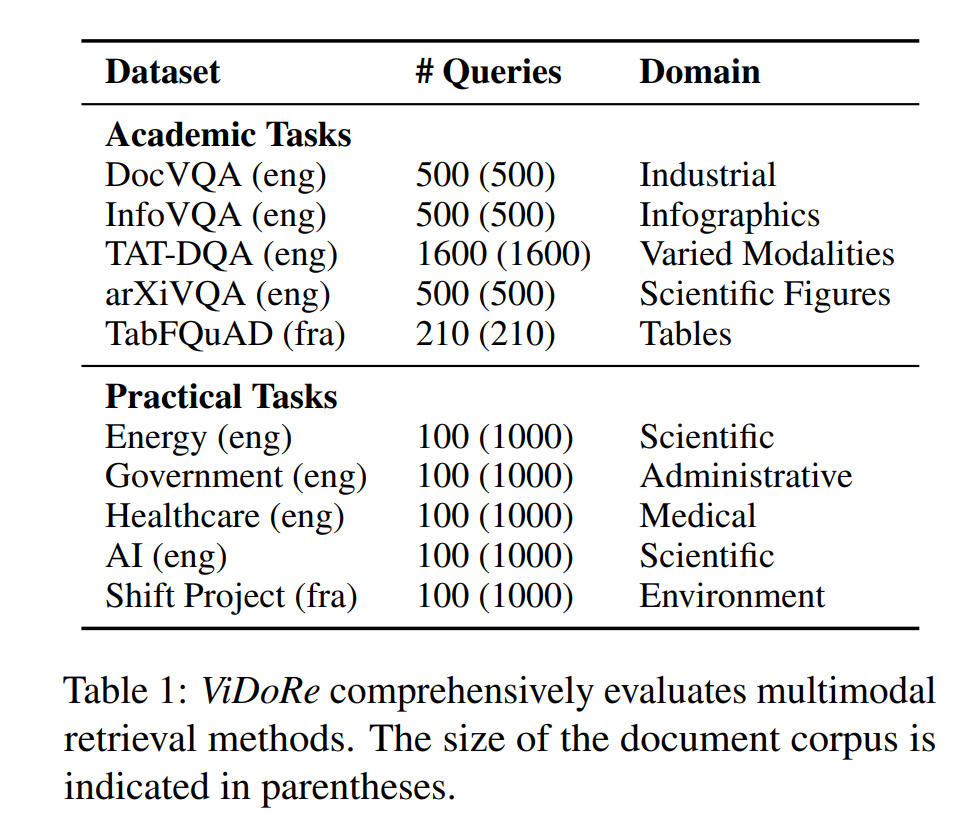
결과가 인상적입니다.
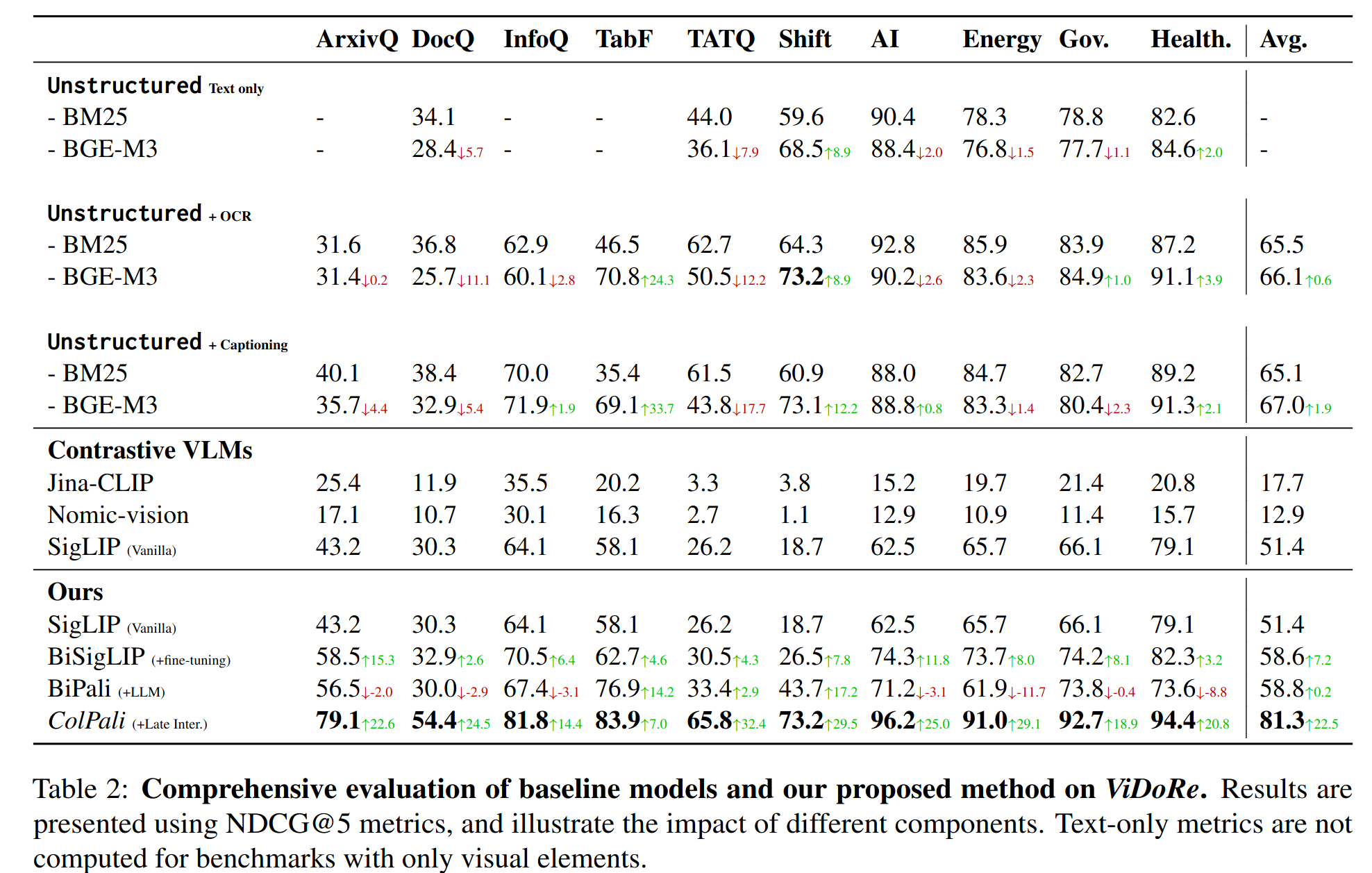
| 모델 | NDCG@5 |
|---|---|
| ColPali | 81.3 |
| Unstructured + BGE-M3 (OCR 기반 최고 성능) | 67.0 |
| Claude Sonnet 캡셔닝 + 텍스트 검색 | 66.7 |
특히 표(TabFQuAD) 데이터에서 차이가 극적입니다: ColPali 83.9 vs OCR 기반 35.4 (+48.5p). 표는 OCR이 가장 취약한 문서 유형인데, ColPali는 표의 시각적 구조를 그대로 인코딩하니 이런 차이가 나는 겁니다.
흥미로운 건 Claude Sonnet으로 문서의 시각 요소를 캡셔닝한 뒤 텍스트 검색을 한 파이프라인도 ColPali에 못 미쳤다는 점입니다. 아무리 좋은 VLM으로 캡셔닝해도, 텍스트로 변환하는 순간 시각적 맥락이 손실된다는 걸 보여줍니다.
어텐션 히트맵으로 보는 ColPali의 "이해력"
ColPali가 정말 문서를 "이해"하는지는 어텐션 히트맵으로 확인할 수 있습니다. 아래 그림에서 hour라는 쿼리 토큰이 문서의 어떤 영역에 주목하는지를 시각화했습니다.
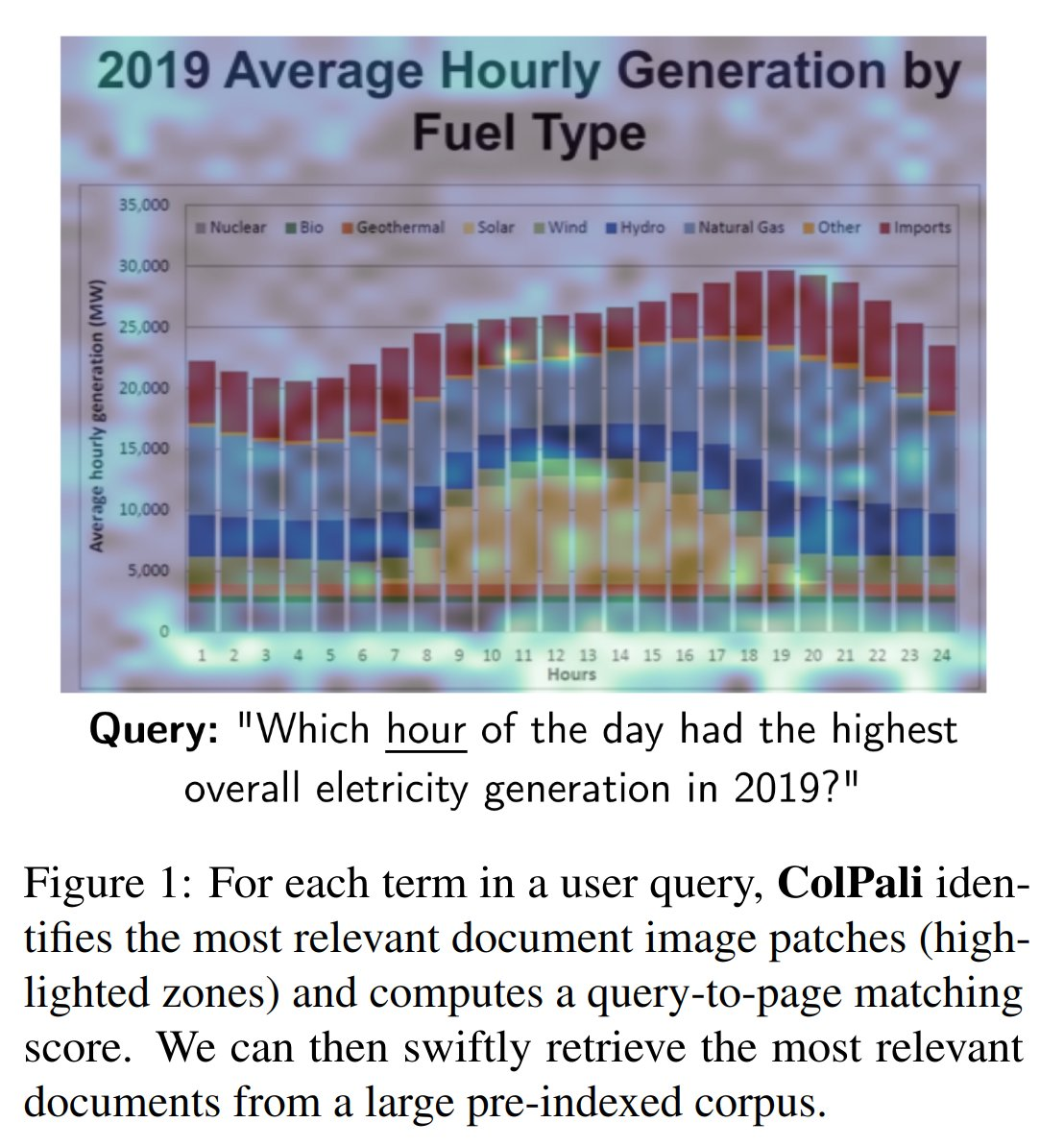
차트의 시간축 영역이 활성화되는 걸 볼 수 있습니다. OCR로 텍스트를 추출하지 않았는데도, 모델이 차트의 시각적 구조를 이해하고 관련 영역을 정확히 찾아내는 겁니다. 이건 단순한 패턴 매칭이 아니라, VLM의 시각-언어 이해 능력이 Late Interaction을 통해 검색에 활용되는 것입니다.
대규모 검색에서 Late Interaction은 실용적인가?
ColPali의 학술적 성능은 입증됐는데, 실제 대규모 서비스에서도 쓸 수 있을까요? 여러 시그널이 긍정적입니다.
Late Interaction 자체는 이미 프로덕션에서 검증된 패러다임입니다. ColBERT를 만든 Omar Khattab(Stanford)의 연구 그룹이 개발한 DSPy 프레임워크가 ColBERT 기반 검색을 핵심 컴포넌트로 채택했고, Vespa(Yahoo의 오픈소스 검색 엔진)도 네이티브 ColBERT 지원을 추가했습니다(Vespa Blog, 2023). 텍스트 검색에서 검증된 Late Interaction이 ColPali를 통해 멀티모달로 확장된 것이므로, 기술적 리스크는 상대적으로 낮습니다.
생태계도 빠르게 성장하고 있습니다. ColPali 이후 ColQwen2는 Qwen2-VL 기반으로 다국어 성능을 강화했고, ColSmol은 경량화에 초점을 맞췄습니다. Milvus, Qdrant 같은 벡터 데이터베이스도 다중 벡터 검색을 공식 지원하기 시작했고, Zilliz는 ColPali + Milvus 통합 가이드를 공개했습니다(Zilliz Blog, 2024).
ColPali의 현실적 한계는?
물론 한계도 있습니다.
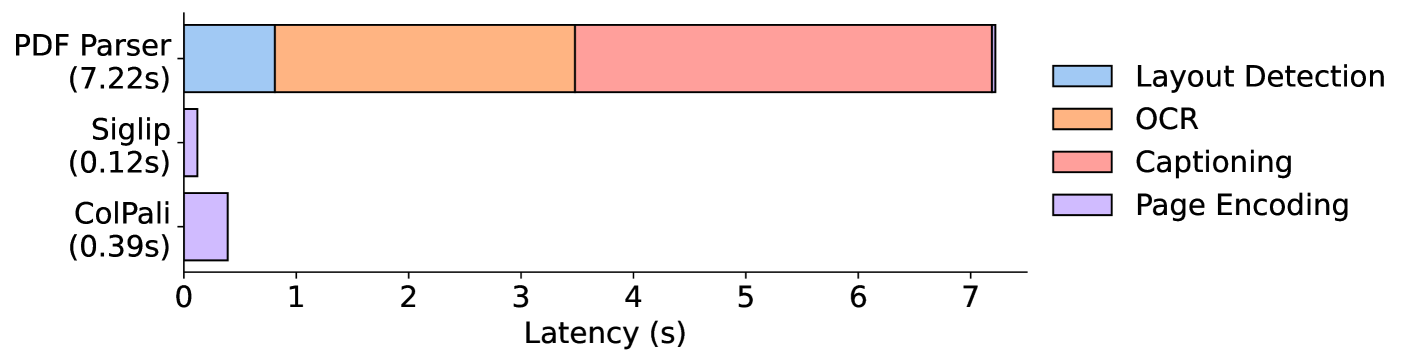
가장 큰 이슈는 스토리지입니다. 페이지당 1024개의 128차원 벡터를 저장해야 하니, 수천만 페이지 규모에서는 스토리지 비용이 상당합니다. 마트로시카 표현 학습(MRL)로 벡터 차원을 64 또는 128로 줄이면 스토리지를 크게 절감할 수 있는데, 이 부분은 시리즈 다음 글에서 상세히 다루겠습니다.
인코딩 레이턴시도 고려해야 합니다. VLM으로 페이지 이미지를 인코딩하는 건 텍스트 임베딩보다 느립니다. 다만 이건 오프라인 인덱싱 단계에서 처리되므로, 검색 시점의 사용자 경험에는 영향을 주지 않습니다. Nunchaku 같은 4-bit 양자화 기술이나 RunPod Serverless 같은 서버리스 GPU 인프라로 인코딩 비용을 관리할 수 있습니다.
UGC에 ColPali를 적용하면 어떤 아키텍처가 필요한가?
인테리어 후기(텍스트 + 사진)를 하나의 시각적 문서로 취급하면, OCR 파이프라인 없이 사진 속 자재 정보까지 검색할 수 있습니다. RAG 시장이 2025년 USD 1.94B에서 2030년 USD 9.86B로 성장이 전망되는 만큼(MarketsandMarkets, 2025), 시각 문서 검색 기술에 대한 투자는 시장 방향과 맞물려 있습니다.
구체적인 시나리오를 그려보겠습니다. 사용자가 "화이트 톤 주방"을 검색하면, 사진 속 주방 레이아웃과 텍스트 리뷰가 함께 고려된 후기가 반환됩니다. OCR로 추출할 수 없었던 사진 속 자재 정보, 시공 도면, 가격표까지 검색 범위에 포함되는 겁니다.
기술적으로 이런 파이프라인이 필요합니다:
1단계: 시각 문서 인코딩 (ColPali 적용)
인테리어 후기 페이지(텍스트 + 사진)를 ColPali로 다중 벡터 임베딩으로 변환합니다. 각 후기가 1024개의 128차원 패치 벡터로 인코딩됩니다. 사진 속 자재명, 가격, 레이아웃 정보가 시각적 맥락과 함께 임베딩에 담깁니다.
2단계: Late Interaction 검색 (MaxSim)
쿼리 텍스트를 토큰별 벡터로 인코딩한 뒤, 인덱싱된 후기 패치들과 MaxSim을 계산합니다. 이전 글의 CIR 쿼리(이미지 + 텍스트)를 입력으로 받을 수도 있습니다. 상품 검색(CIR) → 관련 후기 검색(ColPali)의 완전한 파이프라인이 가능해집니다.
3단계: 사내 지식 탐색(ORI) 확장
같은 아키텍처로 사내 문서(시공 매뉴얼, 디자인 가이드, 자재 카탈로그)도 검색할 수 있습니다. 전사 지식 탐색 시스템에 ColPali를 적용하면, OCR 파이프라인 유지보수 비용을 절감하면서 검색 품질을 높일 수 있습니다.
평가 지표는 어떻게 설계할까?
검색 결과의 품질만 보면 안 됩니다. 모델 성능 지표(NDCG@5, Recall@10, 인코딩 레이턴시)와 비즈니스 지표(검색 결과 클릭률, 후기 열람 후 구매 전환율)를 동시에 추적해야 합니다.
특히 "전체 차원 연산 대비 MRL 64차원 활용 시의 레이턴시 단축률"과 "NDCG@5 하락폭"을 벤치마크하면, 속도와 정확도의 최적점을 찾을 수 있습니다. 수천만 페이지의 벡터를 0초에 가깝게 검색하는 방법은 다음 글에서 다루겠습니다.
FAQ
ColPali와 기존 OCR 기반 문서 검색의 핵심 차이는 무엇인가?
ColPali는 OCR, 레이아웃 감지, 청킹 등의 다단계 파이프라인을 제거하고, VLM으로 문서 페이지 이미지를 직접 다중 벡터 임베딩으로 변환합니다. ViDoRe 벤치마크에서 NDCG@5 81.3으로 OCR 기반 최고 성능(67.0)을 크게 앞섰습니다(ICLR 2025). 시각적 맥락이 완전히 보존되므로 표, 차트, 인포그래픽 검색에서 특히 강합니다.
Late Interaction(후기 상호작용)이란 무엇인가?
쿼리와 문서를 각각 독립적으로 인코딩한 뒤, 검색 시점에서 토큰 수준의 MaxSim(Maximum Similarity) 연산으로 매칭하는 패러다임입니다. ColBERT(2020)가 텍스트 검색에서 처음 제안했고, ColPali가 이를 이미지 패치로 확장했습니다. 빠른 인코딩(Bi-encoder 수준)과 정확한 매칭(Cross-encoder 수준)의 균형점입니다.
ColPali를 실제 서비스에 적용하려면 어떤 인프라가 필요한가?
VLM 추론 서버(PaliGemma-3B 또는 후속 모델), 다중 벡터를 지원하는 벡터 데이터베이스(Milvus, Qdrant 등)가 핵심입니다. 스토리지 최적화를 위해 MRL(마트로시카 표현 학습)로 벡터 차원을 줄일 수 있습니다. 엔터프라이즈 규모에서 기업용 비정형 데이터의 80-90%가 이미지, 문서, 표 형태인 점을 고려하면(Gartner, 2024), 시각 문서 검색 인프라에 대한 투자는 정당화됩니다.
ViDoRe 벤치마크란 무엇인가?
Visual Document Retrieval Benchmark의 약자로, ColPali 팀이 함께 공개한 시각 문서 검색 평가 기준입니다. 학술 논문, 보고서, 인포그래픽, 표 등 다양한 문서 유형을 포함하고 있으며, NDCG@5를 주요 지표로 사용합니다. 현재 ColPali 기반 모델들이 리더보드 상위를 차지하고 있습니다.
Vol.1의 CIR과 Vol.2의 ColPali는 어떤 관계인가?
CIR(조합 이미지 검색)은 "무엇을 찾을까"에 답하는 기술이고, ColPali는 "어떻게 인코딩하고 매칭할까"에 답하는 기술입니다. CIR로 원하는 상품을 찾고, ColPali로 그 상품이 등장하는 후기 문서를 검색하면 완전한 검색 파이프라인이 됩니다. 두 기술 모두 Late Interaction 패러다임을 활용한다는 공통점이 있습니다.
마치며
문서 검색은 "텍스트를 추출해서 검색한다"에서 "문서를 보이는 그대로 검색한다"로 넘어가고 있습니다.
- ColPali는 OCR 파이프라인의 구조적 한계를 VLM + Late Interaction으로 해결했고, ViDoRe에서 NDCG@5 81.3 vs 67.0으로 기존 방식을 크게 앞섰습니다
- 인테리어 후기처럼 텍스트와 사진이 복잡하게 얽힌 UGC가 ColPali의 첫 번째 적용 대상이 될 수 있습니다
- 스토리지와 인코딩 비용이라는 현실적 과제가 남아 있는데, 이건 임베딩 차원 최적화(MRL, CSR)와 벡터 DB 아키텍처로 풀어야 합니다
References
- Faysse et al. "ColPali: Efficient Document Retrieval with Vision Language Models." ICLR, 2025. Link
- Faysse, Manuel. "ColPali: Efficient Document Retrieval with Vision Language Models." Hugging Face Blog. Link
- Shi et al. "OCR Hinders RAG: Evaluating the Cascading Impact of OCR on Retrieval-Augmented Generation." arXiv, 2024. Link
- Mixedbread AI. "The Hidden Ceiling: How OCR Quality Limits RAG Performance." 2025. Link
- Vespa. "Announcing ColBERT Embedder in Vespa." Vespa Blog, 2023. Link
- Zilliz. "ColPali + Milvus: Redefining Document Retrieval." Zilliz Blog, 2024. Link
- MarketsandMarkets. "Retrieval-Augmented Generation Market." 2025. Link
- Gartner. "Unstructured Data Statistics." via Edge Delta, 2024. Link
- Weaviate. "An Overview of Late Interaction Retrieval Models." Link
- illuin-tech. "ColPali GitHub Repository." Link