핵심 요약
- 조합 이미지 검색(CIR)은 참조 이미지 + 수정 텍스트로 검색하는 멀티모달 기술입니다
- CVPR 2025에서 CoLLM(340만 트리플렛 자동 생성)과 IP-CIR(Zero-shot Recall@10 70.07)이 상용화 장벽을 낮췄습니다
- Amazon은 시각 검색 사용량이 YoY 70% 증가했다고 발표했습니다 (Amazon, 2025)
Intro
인테리어 사진을 스크롤하다 마음에 드는 거실을 발견했습니다. 소파 디자인은 좋은데, 가죽 대신 원목 프레임이었으면 좋겠다는 생각이들어서 "이 사진에서 소파만 원목으로 바꿔서 찾아줘"라고 검색창에 입력하고 싶었지만, 그런 검색은 아직 없습니다.
Google Lens는 월 200억 건 이상의 시각 검색 쿼리를 처리하고, 이 중 25%가 상품 구매 의도를 담고 있습니다(Google, 2024). 그런데 "이것과 비슷하되 이 부분만 다르게"라는 요청 앞에서, 기존 검색은 무력합니다. 텍스트 검색도, 이미지 유사도 검색도 마찬가지입니다.
이 간극을 메우려는 기술이 조합 이미지 검색(Composed Image Retrieval, CIR)입니다. 2025년 CVPR에서 발표된 두 편의 논문이 CIR의 상용화를 가로막던 장벽을 각각 다른 방식으로 깨뜨렸는데요, 이 글에서는 그 기술적 접근법과 이커머스에서 왜 이것이 중요한지를 정리해 보겠습니다.
"가죽 소파"를 검색하면 왜 원하는 게 안 나올까?
Google Lens 상업 의도 쿼리의 상당수는 "이것과 비슷하지만 다른" 상품을 찾는 복합 검색입니다(Google, 2024). 그런데 대부분의 이커머스 플랫폼의 상품 검색은 아직도 텍스트 메타데이터 매칭에 의존하고 있습니다.
텍스트 검색의 한계
"약간 더 어두운 질감의 빈티지 가죽 소파"를 검색창에 입력한다고 칩시다. "빈티지"의 기준이 사람마다 다르고, "약간 더 어두운 질감"을 텍스트로 정확히 표현하는 건 거의 불가능합니다. 결국 키워드 조합을 수십 번 바꿔가며 시도하거나, 검색 결과를 눈으로 하나하나 훑게 됩니다.
이미지 유사도 검색의 한계
마음에 드는 소파 사진을 올려서 "비슷한 상품 찾기"를 누를 수 있습니다. 그런데 이 방식은 참조 이미지와 시각적으로 비슷한 결과만 돌려줍니다. 소재를 바꾸고 싶다거나, 색상만 다른 걸 찾고 싶다거나 하는 의도는 반영이 안 됩니다. 원본과 똑같은 소파만 잔뜩 나옵니다.
인테리어/가구 도메인에서 이 문제가 특히 심합니다. 사용자가 올리는 수백만 건의 인테리어 사진(UGC), 전문가 스타일링 샷, 수천만 개의 상품 이미지가 있는데, 이 안에서 "이것과 비슷하지만 이 부분은 다르게"를 처리하려면 이미지와 텍스트를 동시에 이해하는 검색이 필요합니다.
조합 이미지 검색(CIR)은 어떻게 작동하는가?
조합 이미지 검색(Composed Image Retrieval, CIR)은 기준 이미지(Reference Image)와 수정 텍스트(Modification Text)를 결합한 멀티모달 쿼리로 목표 이미지를 검색하는 기술입니다. 2025년 2월 ACM TOIS에 발표된 서베이에 따르면, 2017년 이후 120편 이상의 CIR 논문이 주요 학회에서 발표되었습니다(ACM TOIS, 2025).
아래 그림이 가장 직관적으로 보여줍니다. 흰 셔츠 이미지에 "노란색에 도트 패턴으로"라는 텍스트를 붙이면, 실제로 노란색 도트 셔츠를 찾아냅니다.
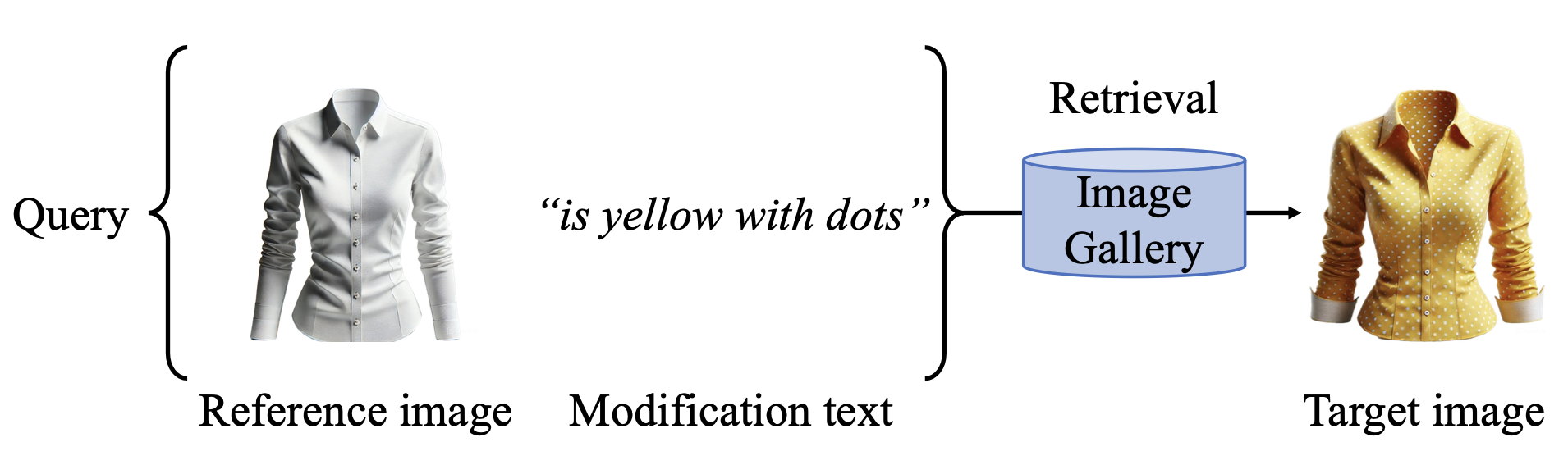
쿼리 구조 자체는 직관적입니다. 사용자가 참조 이미지를 제공하고, "테이블을 유리 재질로 바꿔줘"라는 수정 텍스트를 붙이면, 시스템이 두 모달리티의 의도를 모두 반영한 이미지를 찾아줍니다. 참조 이미지의 시각적 맥락(구도, 분위기, 나머지 요소)은 유지하면서 텍스트가 명시한 속성만 변경된 결과를 찾는 게 핵심입니다.
문제는 학습 데이터입니다. CIR 모델을 학습시키려면 (Reference Image, Modification Text, Target Image) 트리플렛이 필요합니다. "이 거실 사진"과 "소파를 원목으로"라는 텍스트, 그리고 실제로 원목 소파가 놓인 유사한 거실 사진을 짝지어야 합니다. 이걸 수작업으로 만드는 비용이 CIR 연구의 가장 큰 병목이었습니다.
그래서 Zero-shot CIR이 등장했습니다. CLIP처럼 사전 학습된 비전-언어 모델을 활용해서, 트리플렛 학습 없이도 CIR을 수행하려는 접근법입니다. Vision Transformer 기반의 CLIP이 이미지와 텍스트를 같은 임베딩 공간에 매핑하는 능력을 제공하는데요, 비용은 제로에 가깝지만 정확도에서 Supervised 방식에 뒤처지는 게 한계였습니다.
CIR과 기존 검색 방식은 뭐가 다른가?
| 구분 | 텍스트 검색 | 이미지 유사도 검색 (CBIR) | 조합 이미지 검색 (CIR) |
|---|---|---|---|
| 쿼리 | 키워드/문장 | 참조 이미지 | 참조 이미지 + 수정 텍스트 |
| 이해 범위 | 텍스트 메타데이터 | 시각적 유사성 | 시각적 맥락 + 텍스트 의도 |
| 속성 변경 | 간접적 (키워드 변경) | 불가능 | 직접 명시 가능 |
| 사용 예시 | "원목 소파" | [소파 사진] → 비슷한 소파 | [소파 사진] + "원목으로" |
CIR의 다른 접근
2025년 CVPR에서 CIR의 두 가지 난제에 각각 다른 방식으로 답하는 논문이 나왔습니다. CoLLM은 LLM으로 340만 트리플렛을 자동 생성해서 데이터 병목을 없앴고, IP-CIR은 확산 모델로 "상상 속 이미지"를 만들어 Zero-shot 환경에서 Recall@10 70.07을 기록했습니다.
CoLLM: LLM으로 학습 데이터를 자동 생성하다
CIR의 가장 큰 장벽인 트리플렛 데이터, 이걸 사람 대신 LLM이 만들면 어떨까요?
CoLLM은 이 발상에서 출발합니다. 웹에서 무작위로 크롤링한 이미지-캡션 쌍을 LLM에 넣고, 수정 텍스트를 온더플라이(on-the-fly)로 생성합니다. "이 이미지에서 뭘 바꾸면 저 이미지가 되지?"를 LLM이 추론하는 방식입니다.
아래 그림이 CoLLM의 학습 프레임워크를 보여줍니다. (a)는 학습 파이프라인이고, (b)는 추론 시 Reference Image와 Modification Text를 결합하는 과정입니다.
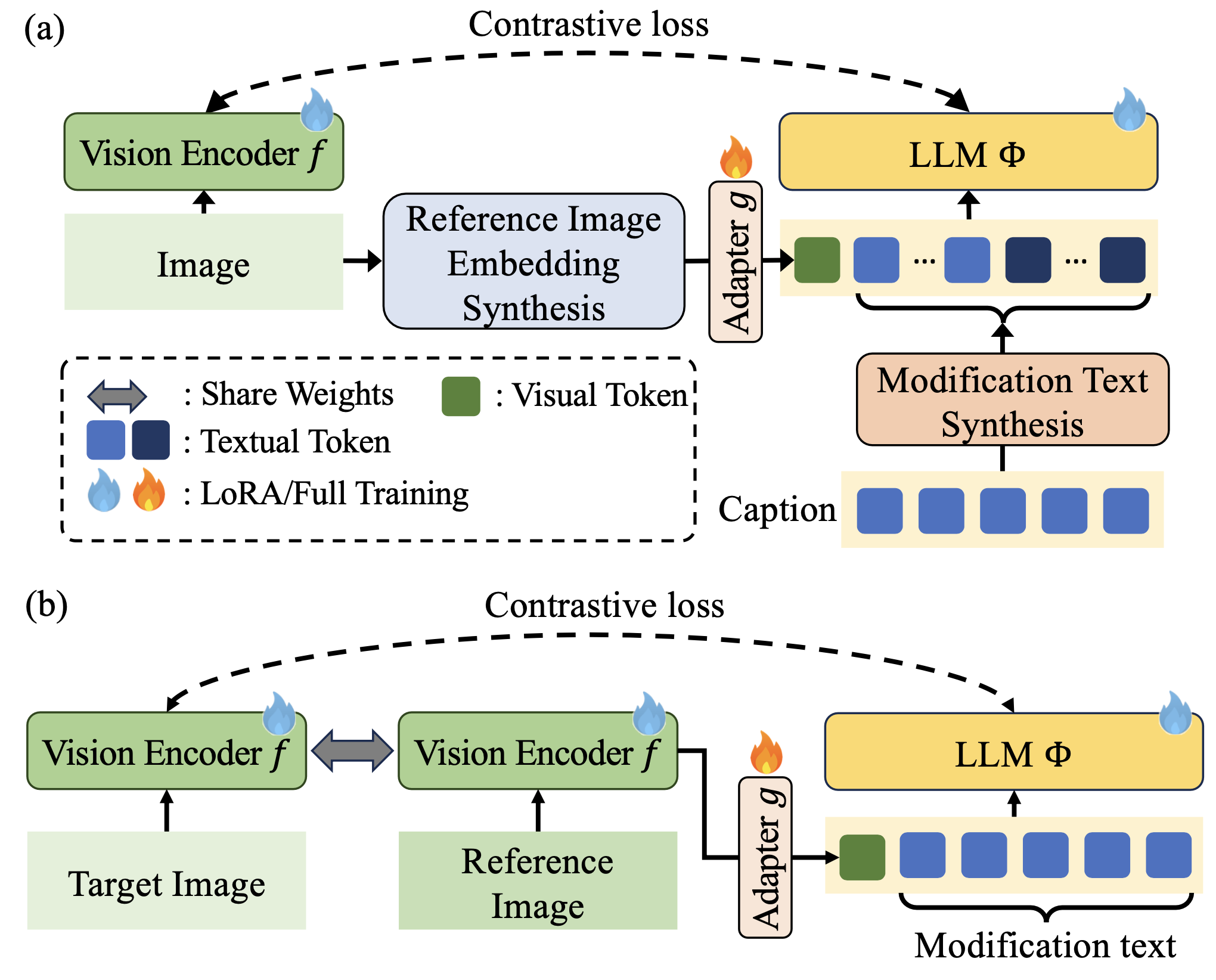
구체적으로 어떻게 트리플렛을 만들까요? 아래 그림을 보면, 두 이미지의 캡션을 비교해서 "A 대신 B"라는 수정 텍스트를 텍스트 보간(Text Interpolation)으로 자동 합성합니다. Reference Image Embedding도 Augmentation + Slerp 보간으로 만듭니다.
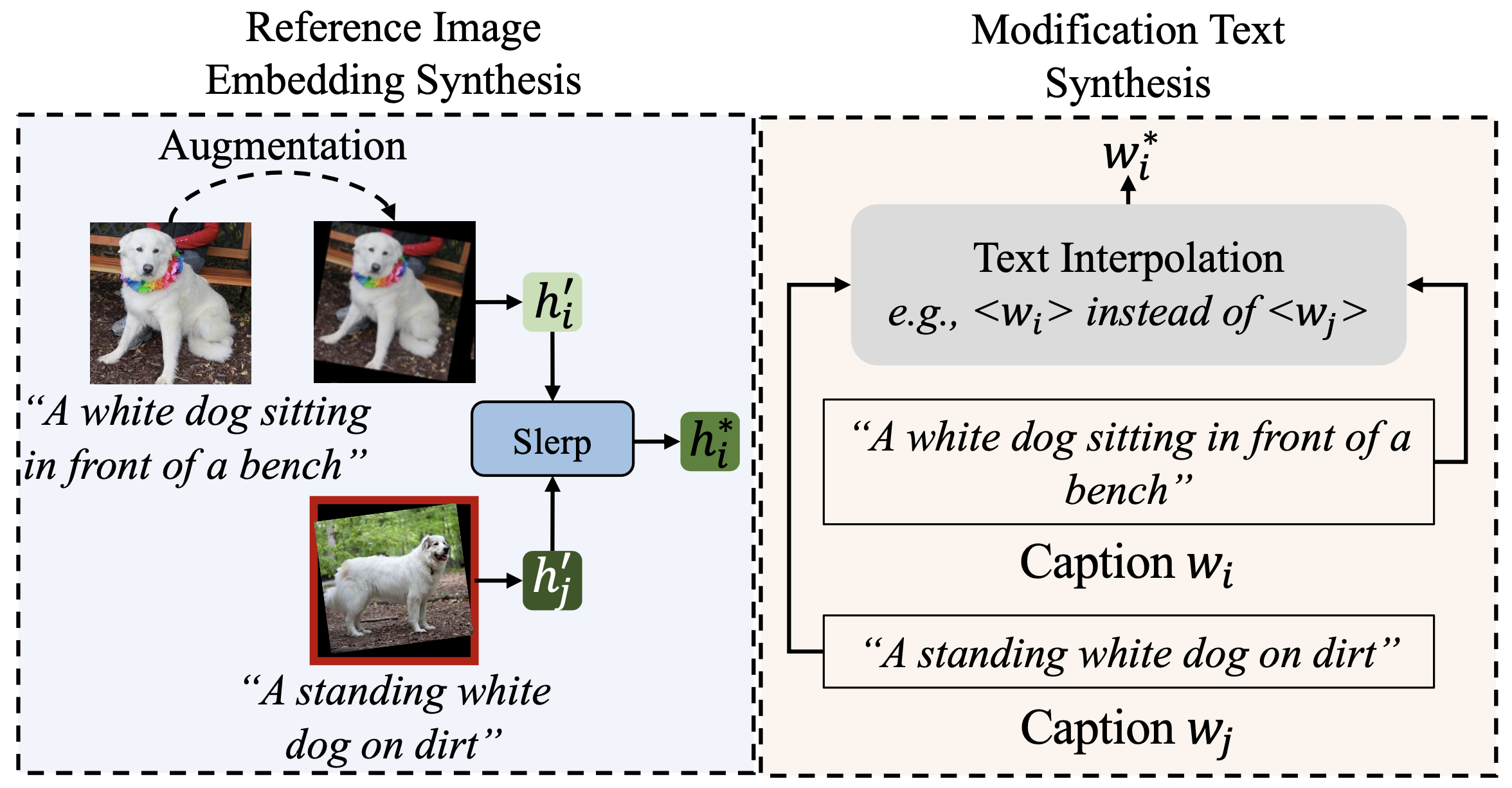
이 파이프라인으로 CoLLM은 340만 개의 트리플렛을 구축했고, MTCIR이라는 데이터셋으로 공개했습니다(CVPR 2025). 참조 이미지와 텍스트의 조인트 임베딩을 깊이 융합한 결과, CIRR과 Fashion-IQ 벤치마크에서 기존 SOTA를 넘겼습니다.
아래 벤치마크 결과를 보면, Synthetic Triplet을 사용한 CoLLM(주황색)이 Without Triplet 방법들(파란 빗금)을 CIRR과 Fashion-IQ 모두에서 크게 앞서는 걸 확인할 수 있습니다.
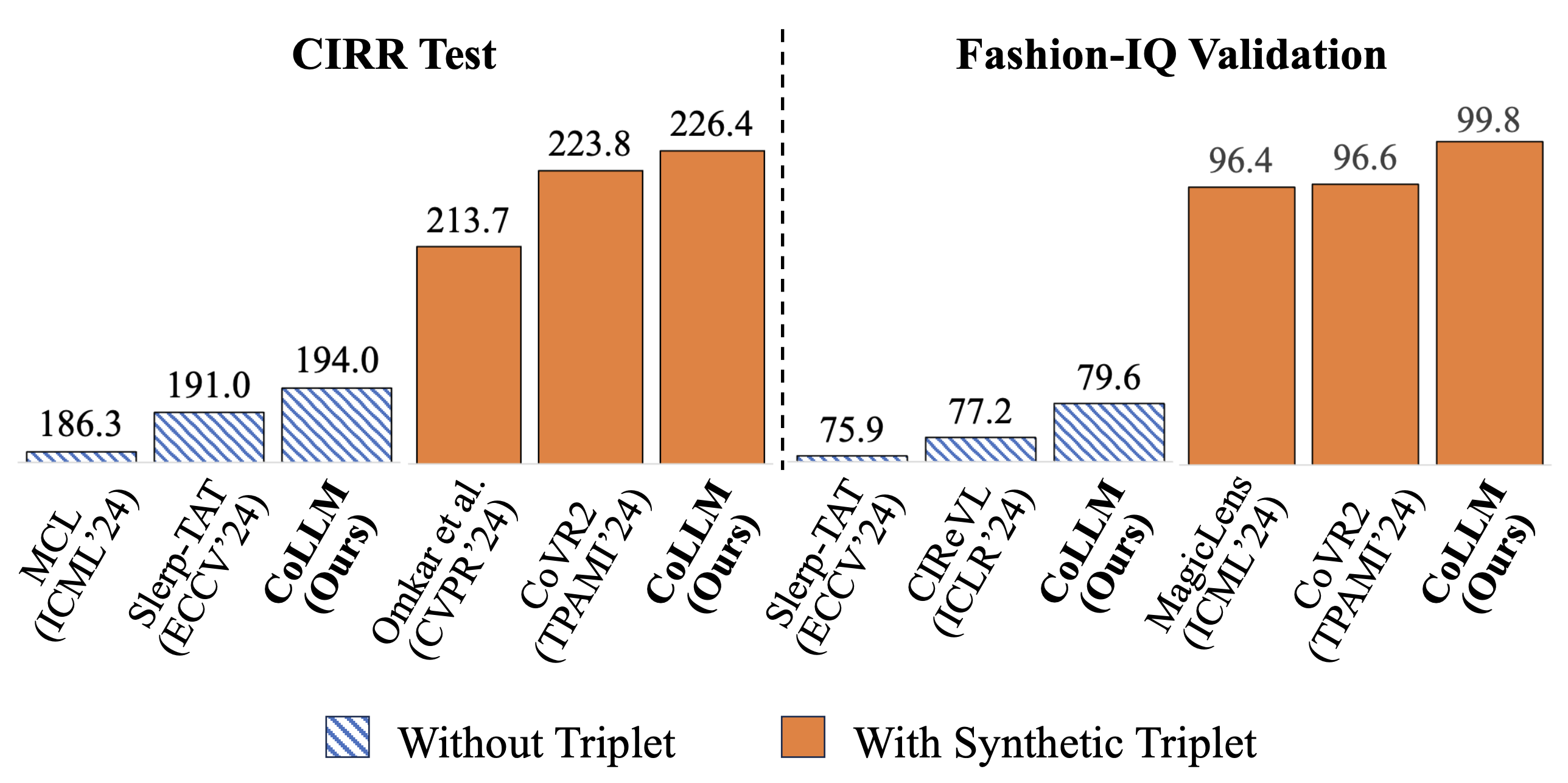
CoLLM의 진짜 가치는 성능 자체보다 수작업 어노테이션 비용 제거에 있습니다. 트리플렛 구축에 들어가던 비용이 사라지면, CIR의 상용화 장벽이 크게 낮아집니다.
IP-CIR: 학습 없이 "상상한 이미지"로 검색하다
CoLLM이 데이터를 자동으로 만드는 접근이라면, IP-CIR(Imagine and Seek)은 아예 데이터 없이 작동하는 접근입니다.
아이디어가 재밌습니다. 사용자가 소파 사진과 "원목 프레임으로"라는 텍스트를 입력하면, IP-CIR은 LLM과 확산 모델(Diffusion Model)을 결합해서 가상 프록시 이미지(Imagined Proxy)를 먼저 만듭니다. "원목 프레임 소파가 놓인 거실"을 상상으로 그려내는 겁니다.
그 다음이 핵심인데요, 생성된 프록시 이미지의 피처와 원본 쿼리(이미지 + 텍스트)의 피처를 균형 메트릭(Balanced Metric)으로 결합합니다. 텍스트 기반 유사도와 이미지 기반 유사도를 동시에 따져서, 모델이 한쪽으로만 끌려가는 편향을 막습니다.
아래 포스터에서 IP-CIR의 전체 파이프라인을 확인할 수 있습니다. 왼쪽의 Introduction에서 기존 방식과의 차이를, 중앙의 Methodology에서 Imagined Proxy 생성과 Balanced Proxy Retrieval 과정을 보여줍니다.

이 아키텍처로 추가 학습 없이 CIRR 데이터셋에서 Recall@10 70.07을 기록했습니다(CVPR 2025). 새 도메인에 바로 적용할 수 있다는 점에서, 빠른 프로토타이핑이 필요한 이커머스 팀에게 매력적입니다.
CoLLM vs IP-CIR: 언제 뭘 써야 할까?
| 구분 | CoLLM | IP-CIR |
|---|---|---|
| 접근법 | Supervised (자동 데이터 생성) | Zero-shot (학습 불필요) |
| 핵심 기술 | LLM + 웹 크롤링 | LLM + Diffusion Model |
| 데이터 | 340만 트리플렛 자동 생성 | 학습 데이터 불필요 |
| 벤치마크 | CIRR, Fashion-IQ SOTA | CIRR Recall@10 70.07 |
| 장점 | 대규모 학습으로 높은 정확도 | 바로 적용 가능, 도메인 무관 |
| 적용 시나리오 | 이미지 데이터 충분할 때 | 빠른 프로토타이핑, 새 도메인 진입 |
도메인 특화 데이터가 풍부한 대형 플랫폼이라면 CoLLM의 자동 트리플렛 파이프라인이 정확도를 더 끌어올릴 수 있습니다. 반면 새 카테고리를 빠르게 검증해야 하거나 학습 인프라가 부족한 팀이라면 IP-CIR의 Zero-shot 접근이 현실적입니다.
아래 정성적 결과를 보면 그 차이가 체감됩니다. "동물이 차도를 걸어가게 해줘"라는 수정 텍스트에 대해, CoLLM + MTCIR 조합이 가장 정확한 결과를 반환합니다.

시각 검색은 이커머스 지표를 실제로 바꾸고 있나?
Amazon은 2025년 전 세계 시각 검색 사용량이 전년 대비 70% 늘었다고 발표했습니다(Amazon, 2025). 단순히 "사진으로 검색하는 사람이 늘었다"는 이야기가 아닙니다. 실제 비즈니스 지표가 움직이고 있습니다.
숫자를 보겠습니다:
- Google Lens: 월 200억+ 쿼리, 4건 중 1건이 구매 의도(Google, 2024)
- 시장 규모: 시각 검색 시장은 연평균 15.2% 성장이 전망되고 있습니다(Market Research Intellect, 2025)
비즈니스 임팩트도 직접적입니다. 시각 검색을 도입한 이커머스 플랫폼에서 전환율 향상과 반품률 감소가 보고되고 있습니다. 사진으로 검색한 사용자가 원하는 제품을 정확히 찾을 확률이 높으니, 어찌 보면 당연한 결과입니다.
여기서 CIR의 가치가 분명해집니다. 지금의 시각 검색이 "비슷한 것 찾기"에 머물러 있다면, CIR은 "비슷하지만 이런 점만 다르게"까지 처리합니다. 이 차이가 전환율 차이로 이어질 수 있습니다.
인테리어 플랫폼에 CIR을 적용하면 어떤 아키텍처가 필요한가?
오늘의집과 같은 인테리어 플랫폼은 사용자 UGC 수백만 건, 전문가 스타일링 샷, 수십만 개의 상품 데이터베이스를 갖고 있습니다. CIR이 가장 큰 가치를 낼 수 있는 도메인입니다.
사용자가 마음에 드는 거실 사진을 플랫폼에서 발견하거나 직접 업로드합니다. "이 소파를 원목 프레임으로 바꿔서 찾아줘"라고 입력합니다. CIR 시스템은 사진 속 소파의 디자인(라인, 비율, 쿠션 형태)은 유지하면서, 소재만 원목으로 변경된 상품을 찾아서 보여줍니다.
이걸 기술적으로 구현하려면 어떤 파이프라인이 필요할까요? CVPR 2025 논문들과 최신 검색 인프라를 조합하면 이런 구조가 나옵니다:
1단계: 가상 프록시 이미지 생성 (IP-CIR 적용)
사용자의 참조 이미지와 수정 텍스트를 받아서, LLM 프롬프팅을 거친 뒤 경량화된 Stable Diffusion으로 프록시 이미지를 만듭니다. Nunchaku 같은 4-bit 양자화 기술을 쓰면 프록시 생성 레이턴시를 크게 줄일 수 있습니다. 이 프록시는 검색용 시각 표현이지, 사용자에게 보여줄 완성 이미지가 아닙니다.
2단계: 멀티스케일 임베딩 파이프라인 (ColPali + MRL)
프록시 이미지와 타겟 데이터베이스 이미지를 VLM(PaliGemma-3B)으로 다중 벡터 임베딩으로 변환합니다. 마트로시카 표현 학습(MRL)을 적용해서 하나의 모델에서 64/128/512/1024 차원 임베딩을 동시에 뽑습니다.
3단계: 검색 파이프라인 최적화 (Milvus/pgvector)
64차원 초소형 임베딩으로 벡터 DB에서 상위 1,000개 후보를 빠르게 추출하고, 원본 다중 벡터 간의 MaxSim으로 최종 랭킹을 매깁니다. 무차별 대입 검색 대비 속도가 수십 배 빨라집니다. RunPod Serverless 같은 서버리스 GPU 인프라를 쓰면 비용도 관리할 수 있습니다.
평가 지표는 어떻게 설계할까?
검색 결과의 품질만 보면 안 됩니다. 모델 성능 지표(Recall@10, 레이턴시)와 비즈니스 지표(전환율, 체류시간, 반품률)를 동시에 추적해야 합니다.
예를 들어 "전체 차원 연산 대비 MRL 64차원 활용 시의 레이턴시 단축률"과 "Recall@10 하락폭"을 벤치마크하면, 속도와 정확도의 최적점을 찾을 수 있습니다. 이 정량적 분석이 인프라 비용과 사용자 경험 사이의 트레이드오프를 결정합니다.
FAQ
CIR(조합 이미지 검색)과 기존 이미지 검색(CBIR)의 차이는 무엇인가?
CBIR은 이미지 간 시각적 유사도만 비교해서 "비슷한 이미지"를 돌려줍니다. CIR은 텍스트로 명시한 수정 의도까지 반영해서, "이 소파와 비슷하지만 파란색으로" 같은 복합 쿼리를 처리할 수 있습니다. 2017년 이후 120편 이상의 관련 논문이 나올 만큼 활발한 연구 분야입니다(ACM TOIS, 2025).
Zero-shot CIR이란 무엇인가?
(Reference, Text, Target) 트리플렛 학습 데이터 없이, CLIP 등 사전 학습 모델만으로 CIR을 수행하는 접근법입니다. IP-CIR은 이 방식으로 CIRR 벤치마크에서 Recall@10 70.07을 달성했습니다(CVPR 2025). 새 도메인에 바로 적용할 수 있어서 프로토타이핑에 유리합니다.
CIR을 실제 이커머스 서비스에 적용하려면 어떤 기술이 필요한가?
멀티모달 임베딩 모델(CLIP/SigLIP), 벡터 데이터베이스(Milvus/pgvector), LLM 기반 텍스트 처리, 프록시 이미지 생성을 위한 확산 모델이 핵심입니다. MRL로 임베딩 차원을 최적화하면 검색 속도를 수십 배 높일 수 있습니다. 시각 검색 시장 자체가 연 15.2% 성장 중이므로(Market Research Intellect, 2025), 이 기술 스택에 대한 투자는 시장 방향과 맞물려 있습니다.
시각 검색을 도입하면 이커머스 전환율이 실제로 올라가나?
Amazon은 시각 검색 사용량이 전년 대비 70% 늘었다고 발표했습니다(Amazon, 2025). 시각 검색 사용자는 텍스트 검색 대비 전환율이 높고 반품률이 낮은 경향이 보고되고 있습니다.
CoLLM과 IP-CIR 중 뭘 먼저 써야 하나?
도메인 특화 이미지 데이터가 충분하면 CoLLM의 자동 트리플렛 파이프라인이 정확도가 더 높습니다. CIRR/Fashion-IQ 벤치마크에서 SOTA를 달성했습니다(CVPR 2025). 빠른 프로토타이핑이나 새 도메인 진입에는 학습 없이 쓸 수 있는 IP-CIR이 적합합니다.
마치며
이커머스 검색은 텍스트에서 이미지로, 이미지에서 멀티모달로 넘어가고 있습니다. CIR은 이 흐름에서 빠질 수 없는 기술입니다.
- CoLLM은 LLM으로 학습 데이터 병목을 없앴고, IP-CIR은 학습 없이 바로 쓸 수 있는 Zero-shot 접근을 열었습니다
- 인테리어/가구처럼 시각적 속성이 구매 결정에 직결되는 도메인이 CIR의 첫 번째 적용 대상이 될 수 있습니다
- 시각 검색 시장이 연 15.2%씩 커지는 지금, "비슷한 것 찾기"를 넘어 "비슷하지만 다른 것 찾기"를 제공하는 플랫폼이 앞서갈 것입니다
References
- Google. "Google Search Innovations." Think with Google, 2024. Link
- Amazon. "Visual Search Shopping Features." About Amazon, 2025. Link
- Li et al. "Improving Composed Image Retrieval with an Imagined Proxy (IP-CIR)." CVPR, 2025. Link
- CoLLM Authors. "A Large Language Model for Composed Image Retrieval." CVPR, 2025. Link
- Zhang et al. "Comprehensive Survey on Composed Image Retrieval." ACM TOIS, 2025. Link
- Market Research Intellect. "Visual Search Market Report." OpenPR, 2025. Link