핵심 요약
- FlashInfer는 block-sparse KV 캐시 포맷으로 이질적인 캐시 구조를 통합 처리하는 어텐션 엔진입니다 (MLSys 2025 Best Paper)
- Inter-token-latency 29-69% 감소, 롱컨텍스트 추론 28-30% 레이턴시 감소를 달성합니다
- 메모리 대역폭 활용률 70-83%로 FlashAttention(~45%) 대비 크게 향상됩니다
- vLLM, SGLang, MLC-Engine 등 주요 서빙 프레임워크의 코어 어텐션 백엔드로 채택되었습니다
Intro
FlashInfer는 block-sparse KV 캐시 포맷과 JIT 커널 컴파일로 LLM 어텐션 연산의 병목을 해소하는 MLSys 2025 최우수 논문으로, inter-token-latency를 29-69% 줄이고 메모리 대역폭 활용률을 70-83%까지 높입니다(MLSys 2025). University of Washington, CMU, NVIDIA 공동 연구이며, vLLM과 SGLang의 코어 어텐션 백엔드로 채택되었습니다.
이전 글에서 MorphServe가 트래픽에 따라 KV 캐시를 동적으로 리사이징한다고 했습니다. 그런데 리사이징된 KV 캐시로 어텐션을 계산하려면, 밀집(dense) 영역과 비어있는(sparse) 영역이 뒤섞인 복잡한 메모리 구조를 처리해야 합니다. 기존 어텐션 커널은 이런 이질적 구조를 잘 다루지 못합니다.
MorphServe가 "언제, 얼마나 바꿀지"를 결정하는 운전대라면, FlashInfer는 "바뀐 상태에서 어텐션을 어떻게 빠르게 계산할지"를 담당하는 엔진입니다. 이 글에서는 FlashInfer가 어텐션 병목을 해소하는 세 가지 핵심 메커니즘을 정리하고, 시리즈 전체를 마무리합니다.
어텐션 연산에서 진짜 병목은 어디인가?
LLM 추론에서 어텐션 계산은 두 가지 다른 성격의 병목을 가집니다. 프리필(Prefill) 단계는 compute-bound입니다. 긴 입력 프롬프트의 모든 토큰에 대해 어텐션을 한 번에 계산하니, GPU 연산 능력이 병목입니다. 반면 디코딩(Decode) 단계는 memory-bound입니다. 토큰을 하나씩 생성할 때마다 이전 히스토리의 KV 캐시를 전부 불러와야 하니, 메모리 대역폭이 병목입니다.
문제는 대부분의 추론 시간이 디코딩에 쓰인다는 점입니다. 사용자가 체감하는 "응답 속도"는 디코딩 레이턴시에 좌우됩니다. 그리고 디코딩 레이턴시는 GPU가 VRAM에서 KV 캐시를 얼마나 빠르게 읽어오느냐에 달려 있습니다.
FlashInfer 논문이 도입하는 Operational Intensity 개념이 이걸 수식으로 정리합니다. 디코딩 단계에서의 연산 강도(computational intensity)는 1/(1/qo + 1/kv)로, KV 캐시 크기가 커질수록 메모리 대역폭이 직접적 병목이 됩니다. FlashAttention이 이 문제를 타일링(tiling)으로 부분 해결했지만, 실제 서빙 환경의 이질적 KV 캐시(다양한 시퀀스 길이, paged memory, sparse 패턴)에서는 메모리 대역폭 활용률이 ~45%에 머물렀습니다.
FlashInfer는 이걸 70-83%까지 끌어올립니다.
FlashInfer는 KV 캐시를 어떻게 통합하는가?: Block-Sparse 포맷
기존 LLM 서빙 프레임워크들은 KV 캐시를 다양한 방식으로 관리합니다. vLLM의 PagedAttention은 페이지 단위로, 일부 시스템은 연속 메모리로, 또 다른 시스템은 sparse 패턴으로 관리합니다. 각 방식마다 별도의 어텐션 커널이 필요했습니다.
FlashInfer는 이 모든 방식을 Block-Sparse Row(BSR) 포맷이라는 하나의 추상화로 통합합니다.
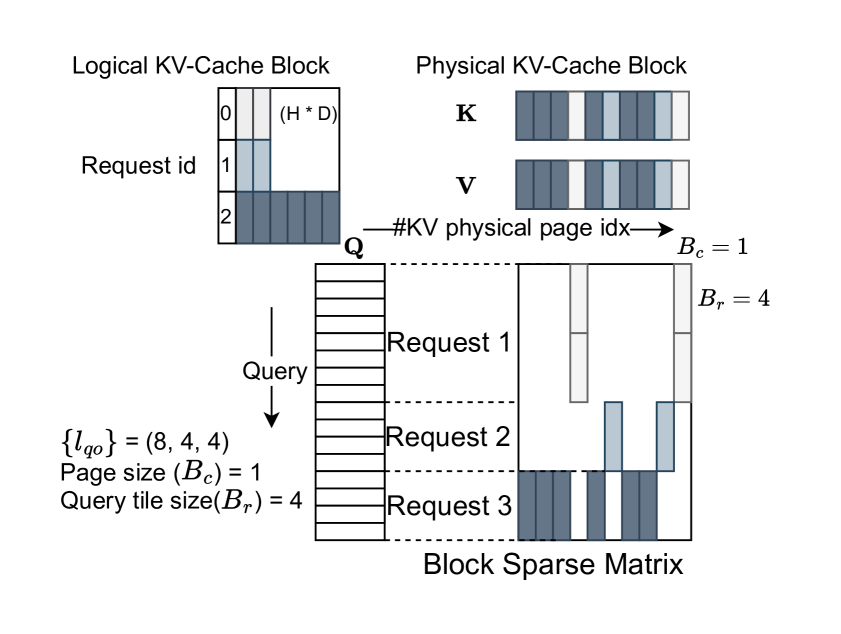
핵심 아이디어는 KV 캐시를 블록 단위의 희소 텐서로 취급하는 것입니다. 각 블록은 연속된 토큰 청크를 나타내고, 희소 메타데이터가 어떤 블록이 활성 상태인지를 명시합니다. Dense 레이아웃, Paged Memory, Sparse Attention 패턴 — 모두 BSR 포맷으로 표현할 수 있습니다.
이전 글의 MorphServe가 KV 캐시를 동적으로 리사이징하면, 일부 블록은 활성 상태이고 일부는 비활성(폐기됨) 상태가 됩니다. FlashInfer의 BSR 포맷은 이 상태를 자연스럽게 표현하고, 비활성 블록은 어텐션 계산에서 스킵합니다. MorphServe와 FlashInfer가 결합되는 지점이 바로 여기입니다.
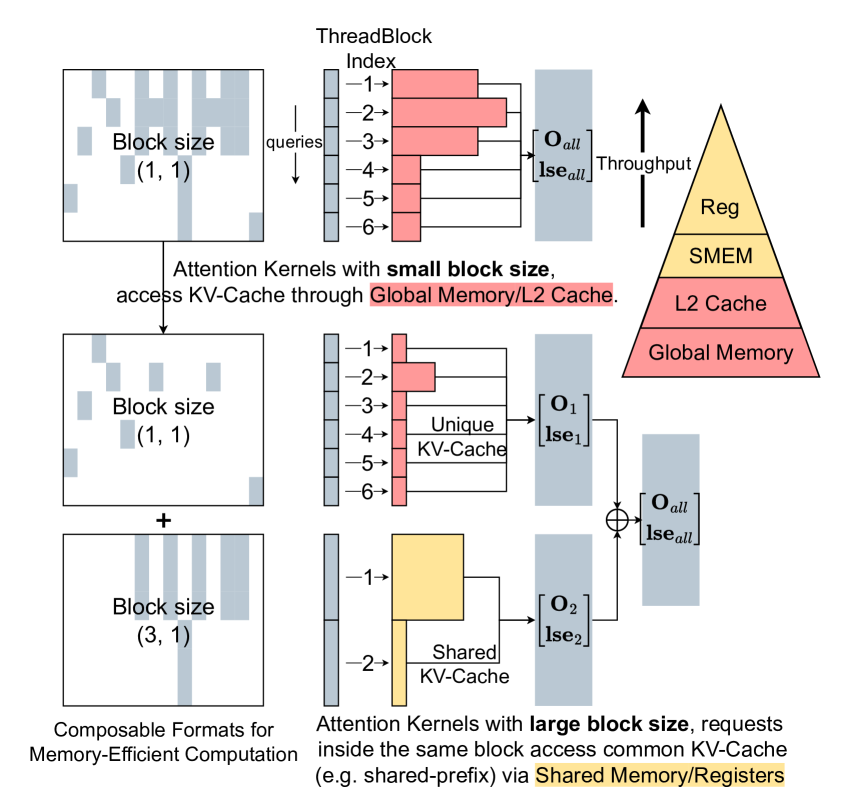
Composable Formats도 중요합니다. 여러 요청이 같은 시스템 프롬프트를 공유하는 경우(이커머스 추천 시스템에서 흔한 패턴), 공유 프리픽스의 KV 캐시를 한 번만 저장하고 요청별 고유 캐시만 별도로 관리합니다. 이 분해(decomposition)를 서로 다른 블록 크기로 표현해서 메모리 효율을 극대화합니다.
JIT 컴파일은 어텐션을 어떻게 빠르게 만드는가?
LLM 추론에서는 어텐션 계산 전후로 다양한 연산이 붙습니다. RoPE(회전 위치 인코딩), 양자화/역양자화, ALiBi, Sliding Window 등. 기존 방식에서는 이 연산들이 각각 별도의 GPU 커널로 실행됩니다. 커널이 바뀔 때마다 GPU 글로벌 메모리를 왕복해야 하니, 메모리 대역폭이 낭비됩니다.
FlashInfer는 이 연산들을 하나의 커널로 융합(fuse)하되, 고정된 커널이 아니라 런타임에 JIT(Just-In-Time) 컴파일합니다.

작동 방식은 이렇습니다. FlashInfer는 어텐션 커널을 "템플릿"으로 정의하고, RoPE/양자화/윈도우 등의 설정을 "변형 함수(variant functor)"로 분리합니다. 사용자가 어텐션 설정을 지정하면, 변형 함수의 CUDA 코드 문자열이 커널 템플릿의 해당 위치에 삽입되고 즉석에서 컴파일됩니다. 이렇게 만들어진 커널은 모든 연산이 하나로 융합되어 있으니, GPU 글로벌 메모리를 반복 왕복할 필요가 없습니다.
기존 방식이 "범용 커널 + 후처리"라면, FlashInfer는 "특화 커널을 즉석 제작"하는 접근입니다. 범용 커널은 모든 경우를 처리해야 해서 불필요한 분기와 메모리 접근이 생기지만, JIT 커널은 현재 설정에 정확히 맞는 코드만 실행합니다.
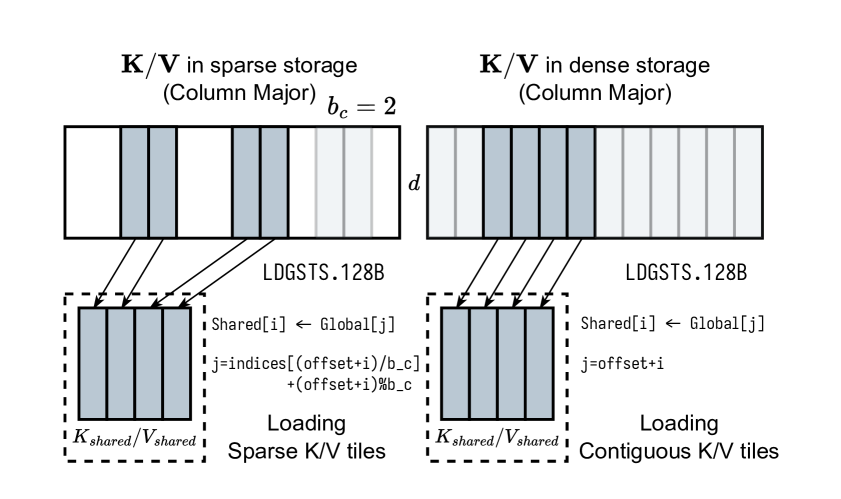
결과가 인상적입니다. RoPE를 융합한 FlashInfer 커널은 융합하지 않은 FlashAttention 대비 28-30% 레이턴시 감소, 1.6-3.7배 대역폭 향상을 보였습니다(MLSys 2025). 이 성능 차이는 롱컨텍스트 추론에서 더 극적으로 나타납니다. 시퀀스가 길수록 KV 캐시 접근 횟수가 늘어나고, 커널 융합의 효과가 누적되기 때문입니다.
벤치마크: FlashInfer는 얼마나 빠른가?
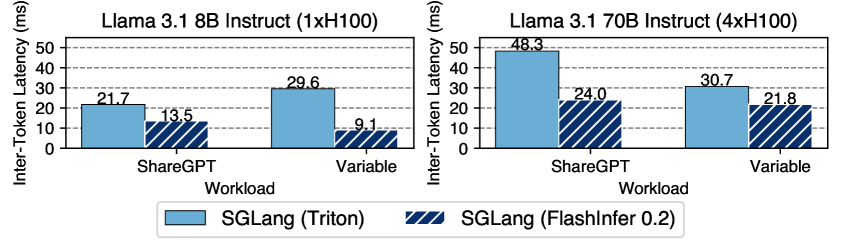
Llama 모델에서 SGLang + FlashInfer와 Triton 백엔드를 비교한 결과입니다.
| 지표 | FlashInfer 성과 |
|---|---|
| Inter-token-latency (ITL) | 29-69% 감소 (vs 컴파일러 백엔드) |
| 롱컨텍스트 추론 레이턴시 | 28-30% 감소 |
| 병렬 생성 속도 | 13-17% 향상 |
| 메모리 대역폭 활용률 | 70-83% (vs FlashAttention ~45%) |
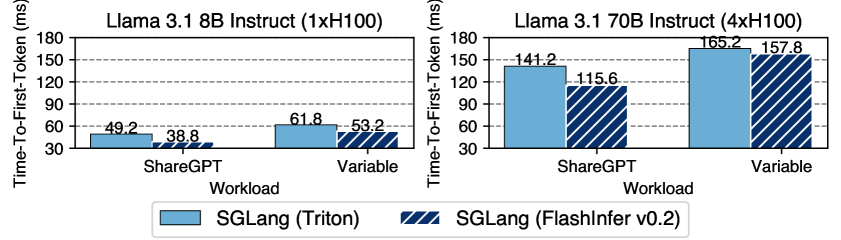
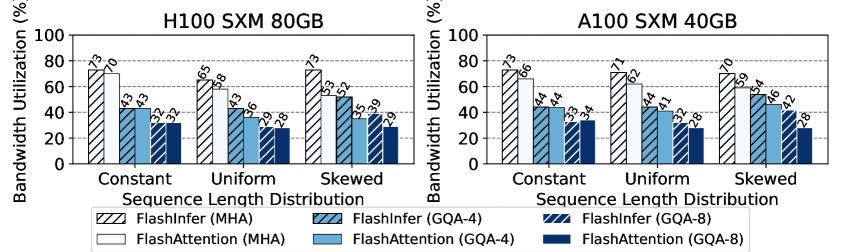
특히 시퀀스 길이가 다양한 실제 서빙 환경(skewed batch)에서 차이가 극적입니다. FlashAttention이 ~45%에 머무는 대역폭 활용률을 FlashInfer는 70-83%까지 끌어올립니다. 이건 FlashInfer의 load-balanced 스케줄러가 배치 내 시퀀스 길이 편차를 효율적으로 처리하기 때문입니다.
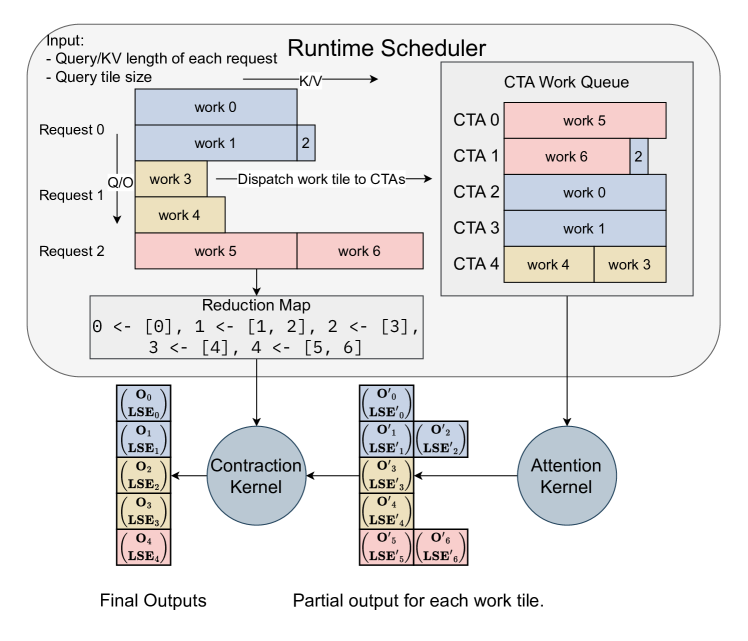
왜 skewed batch에서 차이가 나는지 좀 더 설명하겠습니다. 실제 서빙 환경에서는 한 배치에 시퀀스 길이가 32인 요청과 4096인 요청이 섞여 들어옵니다. 기존 커널은 가장 긴 시퀀스에 맞춰 패딩하거나, 단순히 시퀀스 단위로 GPU 워크그룹을 할당합니다. 짧은 시퀀스를 처리하는 워크그룹은 빨리 끝나고 놀게 되니, GPU 활용률이 떨어집니다. FlashInfer의 스케줄러는 시퀀스를 더 작은 작업 단위로 분해하고, GPU 워크그룹에 균등 분배합니다. 긴 시퀀스는 여러 작업 단위로 나뉘고, 짧은 시퀀스와 인터리빙되어 GPU가 놀지 않습니다.
MorphServe + FlashInfer: 컨트롤러와 엔진의 결합
Vol.4의 MorphServe와 이 글의 FlashInfer를 결합하면, 동적 서빙의 "결정"과 "실행"이 모두 최적화된 구조가 됩니다.
| 역할 | MorphServe (Vol.4) | FlashInfer (Vol.5) |
|---|---|---|
| 핵심 기능 | 트래픽 감지 → 레이어 스와핑/KV 캐시 리사이징 결정 | Block-sparse KV 캐시로 어텐션 효율 계산 |
| 비유 | 운전대 (언제, 얼마나 바꿀지) | 엔진 (바뀐 상태에서 빠르게 계산) |
| 최적화 대상 | 모델 전체 형태 | 어텐션 커널 수준 |
| 논문 | arXiv, 2025 | MLSys 2025 Best Paper |
구체적 시나리오:
- 트래픽 폭주 → MorphServe가 KV 캐시 리사이징 결정 (일부 블록 폐기)
- FlashInfer의 BSR 포맷이 폐기된 블록을 비활성으로 표시
- 어텐션 계산에서 비활성 블록을 스킵 → 연산량 감소
- JIT 커널이 현재 활성 블록 구조에 최적화된 커널 생성
- 결과: 품질 유지 + SLO 준수 + 메모리 효율 극대화
마치며
LLM/VLM 서빙에서 어텐션 연산은 가장 깊은 레이어의 병목입니다. FlashInfer는 이 병목을 세 가지 방향에서 해소합니다.
- Block-sparse KV 캐시 포맷으로 Dense/Paged/Sparse 등 이질적 캐시 구조를 단일 추상화로 통합하여, 커널 파편화 문제를 제거합니다
- JIT 커널 컴파일로 RoPE/양자화 등을 어텐션에 융합하여, GPU 글로벌 메모리 왕복을 최소화합니다
- Load-balanced 스케줄러로 skewed batch에서 GPU 활용률을 70-83%까지 끌어올립니다
이전 글의 MorphServe가 "모델 형태를 트래픽에 맞게 바꾸는" 컨트롤러라면, FlashInfer는 "바뀐 형태에서 어텐션을 빠르게 계산하는" 엔진입니다. 둘을 결합하면 동적 서빙의 결정과 실행이 모두 최적화됩니다.
FAQ
FlashInfer란 무엇인가?
LLM 추론 서빙을 위한 어텐션 엔진으로, block-sparse KV 캐시 포맷과 JIT 커널 컴파일을 핵심으로 합니다. MLSys 2025 최우수 논문을 수상했으며(MLSys 2025), UW, CMU, NVIDIA 공동 연구입니다. vLLM, SGLang, MLC-Engine 등 주요 서빙 프레임워크의 코어 어텐션 백엔드로 채택되었습니다.
Block-sparse KV 캐시 포맷이 왜 중요한가?
실제 서빙 환경에서 KV 캐시는 Dense, Paged, Sparse 등 다양한 형태로 존재합니다. 기존에는 각 형태마다 별도 커널이 필요했습니다. FlashInfer의 BSR 포맷은 이 모든 형태를 하나의 블록 희소 텐서로 통합해서, 단일 커널로 처리합니다. Vol.4의 MorphServe가 KV 캐시를 동적으로 변형해도 FlashInfer가 자연스럽게 처리할 수 있는 이유입니다.
FlashInfer와 FlashAttention의 차이는 무엇인가?
FlashAttention은 어텐션의 메모리 접근 패턴을 타일링으로 최적화합니다. FlashInfer는 여기에 더해서 (1) 이질적 KV 캐시를 block-sparse 포맷으로 통합하고 (2) JIT 컴파일로 RoPE 등을 커널에 융합합니다. 실제 서빙의 skewed batch에서 FlashAttention의 대역폭 활용률이 ~45%인 반면, FlashInfer는 70-83%를 달성합니다.
JIT 커널 컴파일이 어텐션을 어떻게 빠르게 만드나?
어텐션 전후의 연산(RoPE, 양자화, Sliding Window 등)을 별도 커널로 실행하면 GPU 글로벌 메모리를 반복 왕복합니다. FlashInfer는 이 연산들을 런타임에 하나의 커널로 융합하여 메모리 왕복을 제거합니다. RoPE 융합 커널은 28-30% 레이턴시 감소, 1.6-3.7배 대역폭 향상을 보였습니다.
MorphServe와 FlashInfer는 어떤 관계인가?
MorphServe는 트래픽에 따라 레이어 스와핑과 KV 캐시 리사이징을 "결정"하는 컨트롤러이고, FlashInfer는 리사이징된 block-sparse KV 캐시로 어텐션을 "실행"하는 엔진입니다. MorphServe가 KV 캐시 블록을 폐기하면, FlashInfer의 BSR 포맷이 해당 블록을 비활성으로 표시하고 어텐션 계산에서 스킵합니다. 서빙 컨트롤러와 어텐션 엔진이 각자의 레이어에서 최적화를 담당하는 구조입니다.
References
- Ye et al. "FlashInfer: Efficient and Customizable Attention Engine for LLM Inference Serving." MLSys, 2025. Link
- UW Allen School. "Researchers receive Best Paper Award for FlashInfer." 2025. Link
- NVIDIA. "Run High-Performance LLM Inference Kernels Using FlashInfer." 2025. Link
- flashinfer-ai. "FlashInfer GitHub Repository." Link
- vLLM. "FlashInfer Attention Backend Documentation." Link