핵심 요약
- MorphServe는 트래픽 부하에 따라 모델 레이어를 정밀도↔양자화로 실시간 교체하는 동적 서빙 프레임워크입니다 (arXiv, 2025)
- 정밀도 서빙 대비 SLO 위반율 92.45% 감소, P95 TTFT(첫 토큰 생성 시간) 2.2x-3.9x 개선
- 생성 품질 저하는 거의 없으면서 처리량을 크게 높입니다
- AI 추론 워크로드는 2025년 전체 AI 컴퓨트의 약 50%를 차지하며, 2026년에는 2/3까지 늘어날 전망입니다 (Deloitte, 2025)
Intro
이전 글에서 MRL과 CSR로 검색 파이프라인의 스토리지와 속도를 최적화했습니다. 그런데 이 파이프라인을 구동하는 VLM 서빙 인프라는 어떨까요? 모델이 아무리 정확해도, 추론 서버가 트래픽 폭주에 쓰러지면 사용자에게 닿지 않습니다.
이커머스 플랫폼에서 주말 특가가 시작되면 평소 대비 수십 배의 트래픽이 밀려옵니다. 사진 분석, 추천, 랭킹을 담당하는 VLM 서빙 서버의 VRAM이 꽉 차기 시작합니다. TTFT(첫 토큰 생성 시간)가 급등하고, SLO(Service Level Objective) 위반 알림이 쏟아집니다. GPU를 더 띄우자니 콜드 스타트에 수분이 걸립니다. 이미 서비스는 느려지고 있습니다.
기존의 해법은 두 가지였습니다. 항상 정밀도(FP16)로 서빙하거나, 항상 양자화(INT8/INT4)로 서빙하거나. 하지만 둘 다 답이 아닙니다. MorphServe는 세 번째 길을 제시합니다.
왜 "항상 양자화"도 "항상 정밀도"도 답이 아닌가?
LLM/VLM 서빙의 핵심 딜레마는 이렇습니다. 정밀도(FP16) 서빙은 품질이 최고지만 GPU 리소스를 많이 잡아먹어서, 트래픽이 폭증하면 TTFT가 급등하고 SLO를 위반합니다. 반대로 정적 양자화(INT8/INT4) 서빙은 GPU 효율이 높지만, 트래픽이 적을 때도 불필요한 품질 저하를 감수해야 합니다.
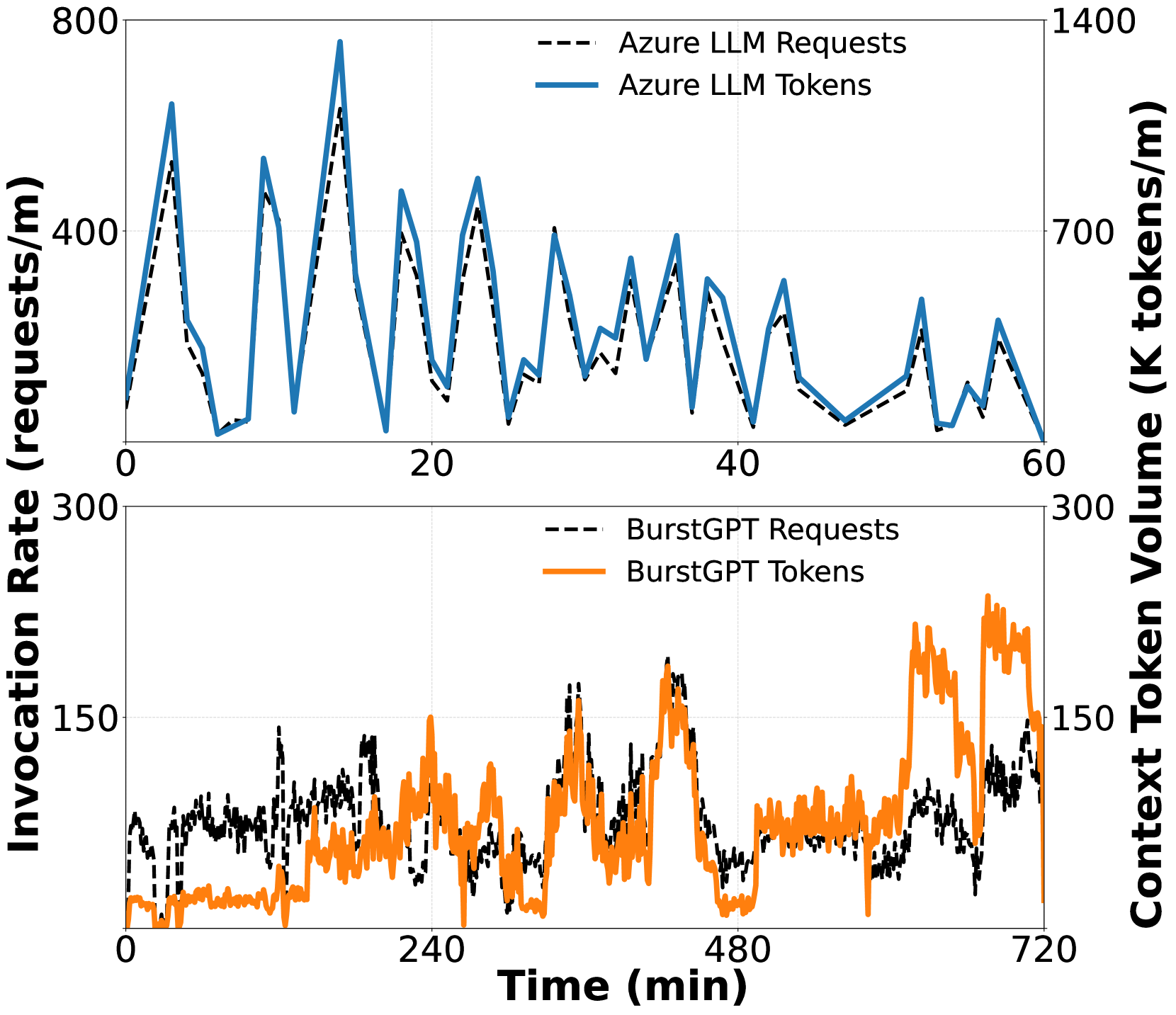
LLM 추론 비용은 연간 10배씩 떨어지고 있고, GPT-4 급 모델의 백만 토큰당 비용은 2022년 $20에서 2024년 $0.40으로 50배 감소했습니다(a16z, 2024). 비용이 내려가면서 더 많은 서비스가 LLM/VLM을 도입하고, 그만큼 트래픽 폭주에 대한 서빙 안정성이 중요해집니다.
실제 LLM 서비스의 트래픽 패턴을 보면, 요청이 일정하게 들어오지 않습니다. 갑자기 폭증했다가 잠잠해지는 버스트(Bursty) 패턴이 반복됩니다. 이커머스에서는 이게 더 극단적인데요, 주말 특가, 연말 세일, 타임딜 같은 이벤트 때마다 수십 배의 트래픽 스파이크가 발생합니다.
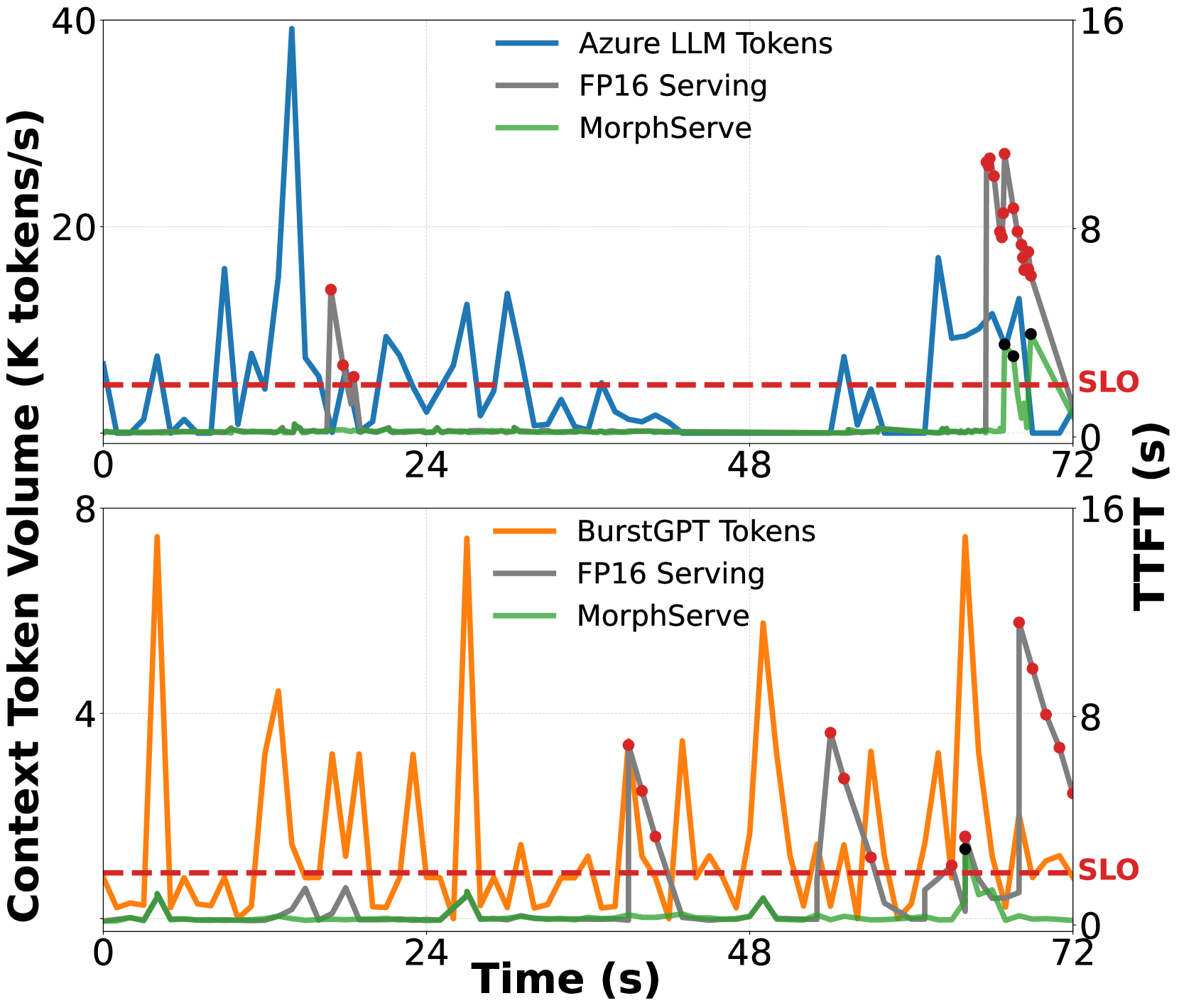
정밀도 서빙에서는 이 스파이크 구간에서 TTFT가 급등합니다. 사용자가 추천 결과를 수 초 이상 기다려야 하는 상황이 됩니다.
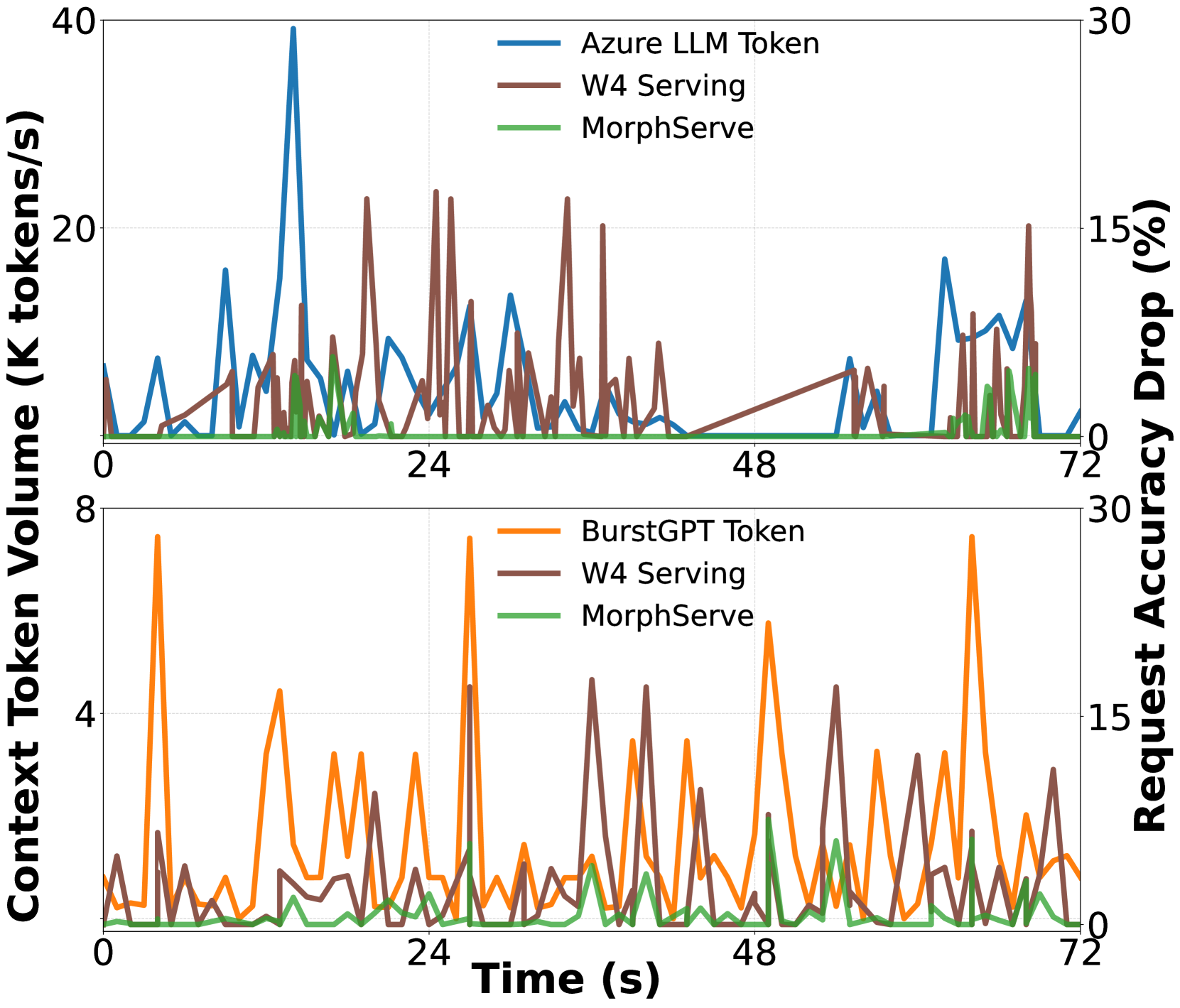
그렇다고 항상 양자화로 서빙하면, 트래픽이 적은 평시에도 품질 손실이 계속됩니다. 추천 정확도가 떨어지면 전환율에 직접 영향을 줍니다.
| 구분 | 정밀도 서빙 (FP16) | 정적 양자화 (INT8) | MorphServe (동적) |
|---|---|---|---|
| 평시 품질 | 최고 | 저하 감수 | 최고 (정밀도 유지) |
| 폭주 시 SLO | 위반 빈발 | 개선되지만 한계 | 92.45% 위반 감소 |
| GPU 효율 | 낮음 | 높음 | 상황 적응형 |
| 적응 능력 | 없음 | 없음 | 실시간 전환 |
MorphServe의 통찰은 간단합니다. "평시에는 정밀도, 폭주 시에만 양자화." 트래픽에 따라 모델의 형태(morphology)를 바꾸는 겁니다.
MorphServe는 어떻게 모델 형태를 바꾸는가?
MorphServe의 아키텍처는 피드백 제어 루프로 구성됩니다. Serving Monitor가 워크로드를 실시간 감지하고, Morphing Controller가 전환 결정을 내리고, Morphing Actuator가 실제 레이어 교체를 수행합니다.
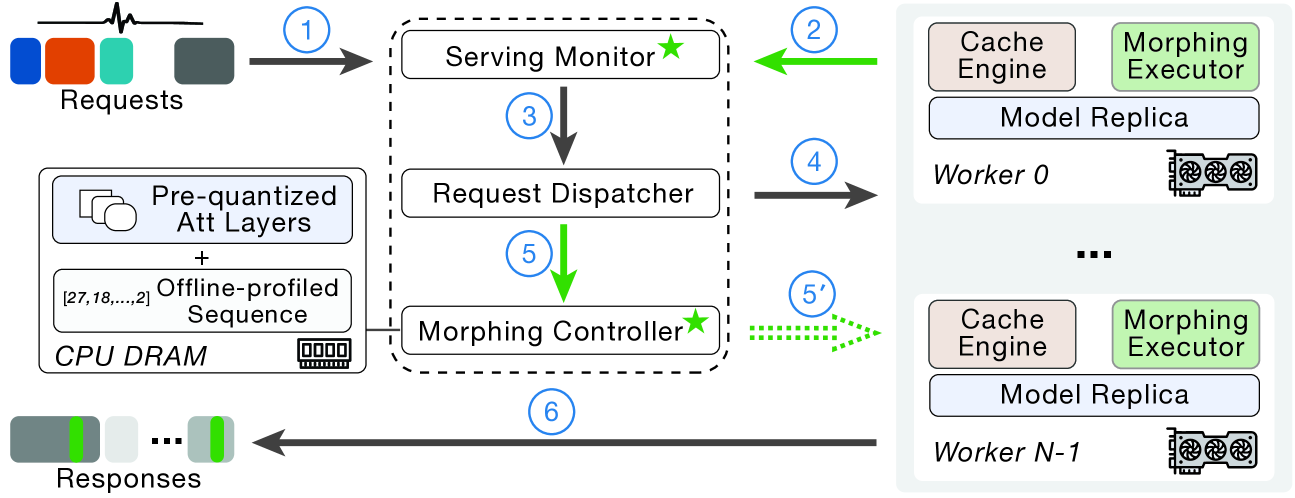
핵심은 두 가지 비동기 토큰 레벨 메커니즘입니다.
메커니즘 1: 런타임 양자화 레이어 스와핑
모든 레이어가 출력 품질에 같은 영향을 주지 않습니다. MorphServe는 각 레이어의 품질 기여도를 사전에 프로파일링해둡니다. 부하가 폭증하면, 영향도가 적은 레이어부터 미리 메모리에 올려둔 INT8 양자화 버전으로 백그라운드에서 교체합니다.
이 과정이 비동기로 일어나기 때문에, 진행 중인 요청의 처리가 중단되지 않습니다. 레이어 하나를 바꾸는 건 밀리초 단위여서, 사용자는 전환을 체감하지 못합니다. 트래픽이 줄어들면 다시 정밀도 레이어로 복원됩니다.
Nunchaku 같은 정적 4-bit 양자화와의 차이점은, MorphServe는 "항상 양자화"가 아니라 "필요할 때만 양자화"한다는 점입니다. 평시에는 정밀도를 유지하니 품질 손실이 없습니다.
메커니즘 2: 압력 인지형 KV 캐시 리사이징
KV(Key-Value) 캐시는 LLM 추론에서 GPU VRAM의 주요 소비원입니다. 긴 컨텍스트 요청이 몰리면 KV 캐시가 급격히 늘어나서 VRAM이 가득 찹니다. 이 상태에서 새 요청이 들어오면 OOM(Out of Memory) 크래시가 발생합니다.
MorphServe는 VRAM 사용률과 평균 TTFT 지연을 초 단위로 모니터링합니다. 메모리 압력이 임계치를 돌파하면, 과거 토큰의 KV 캐시 용량을 동적으로 줄이거나 오래된 캐시를 폐기합니다. 기존 요청의 생성은 계속 진행되면서(state-preserving), 새 요청도 수용할 수 있는 공간을 확보하는 겁니다.
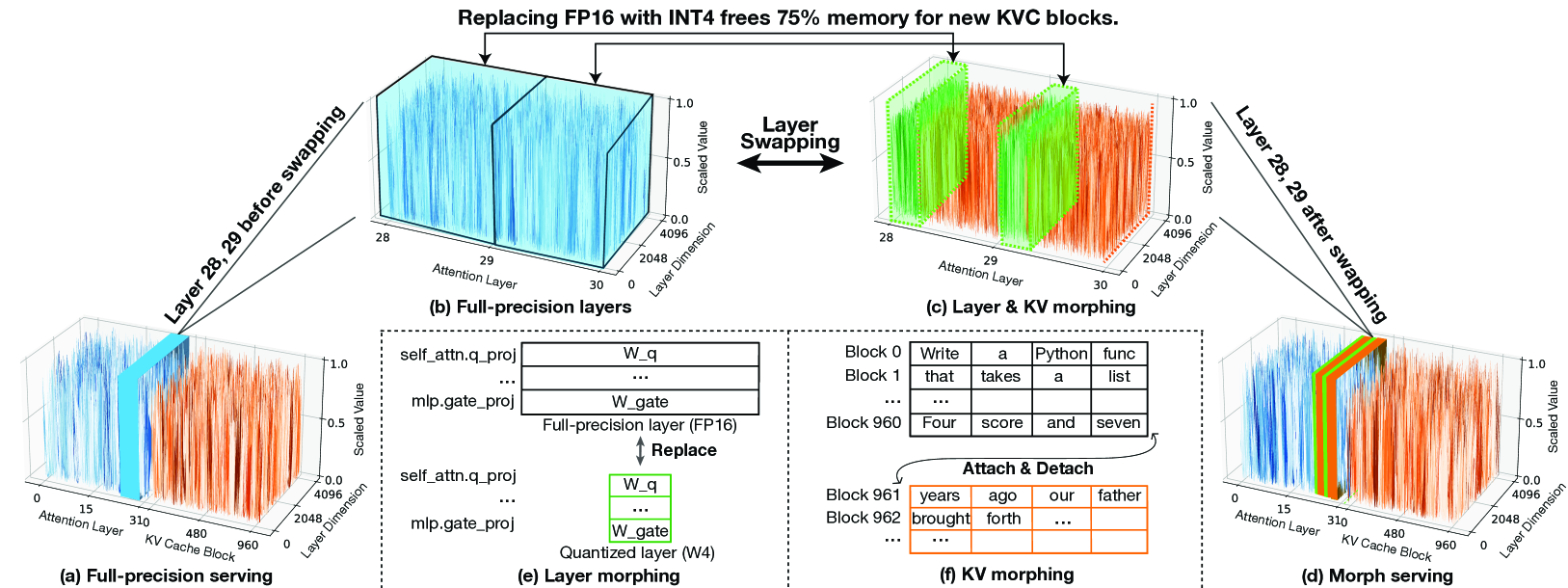
두 메커니즘이 결합되면, 모델은 트래픽에 맞춰 형태를 바꿉니다. 평시에는 풀 정밀도 + 넉넉한 KV 캐시로 최고 품질을, 폭주 시에는 부분 양자화 + 압축된 KV 캐시로 처리량을 확보합니다.
벤치마크: 정말 품질 저하 없이 SLO를 지킬 수 있나?
Vicuna와 Llama 계열 모델에서 실제 워크로드 트레이스로 실험한 결과입니다.
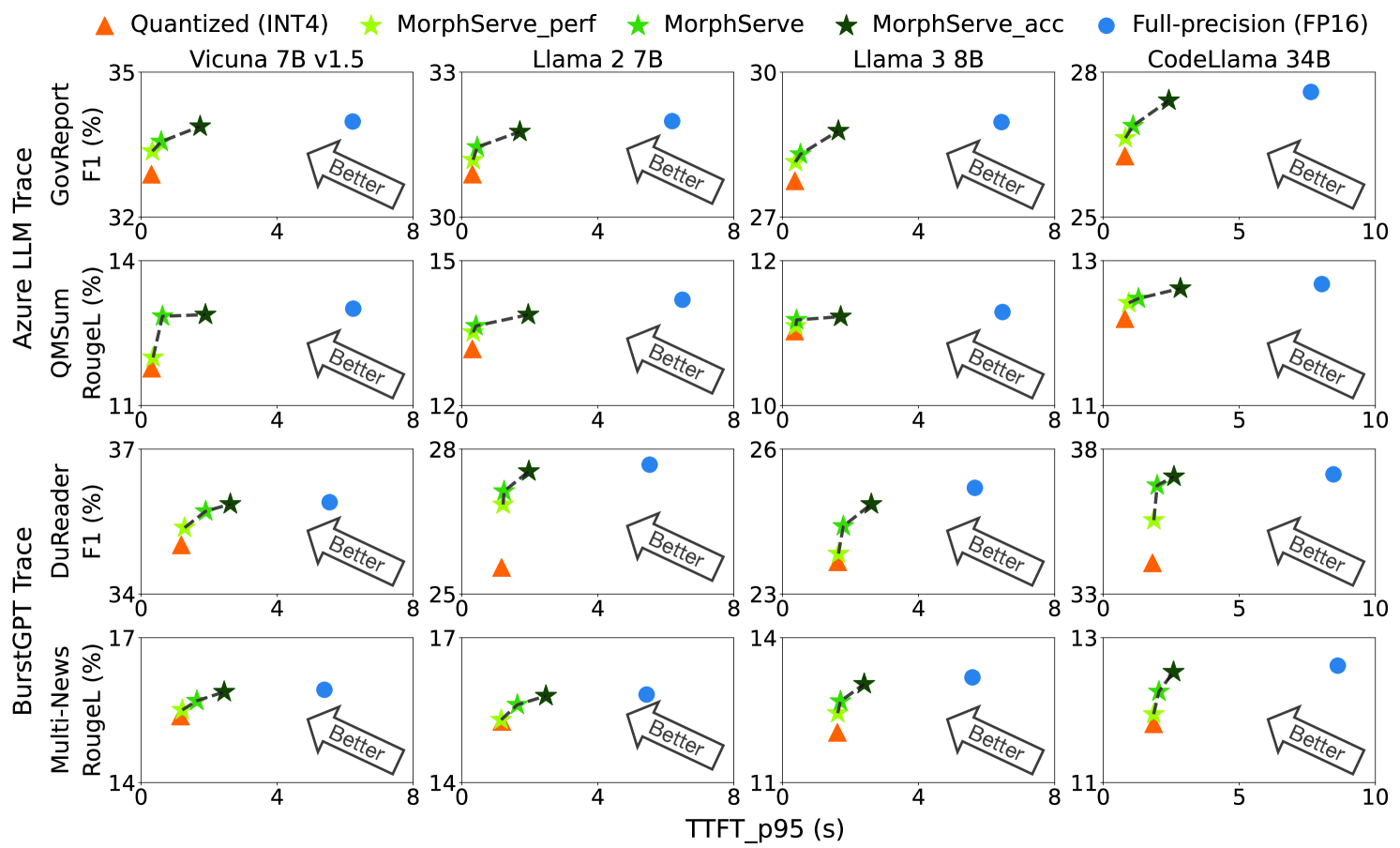
| 지표 | 정밀도 서빙 대비 MorphServe |
|---|---|
| SLO 위반율 | 92.45% 감소 |
| P95 TTFT | 2.2x-3.9x 개선 |
| 생성 품질 | 거의 저하 없음 |
| 구현 규모 | Python ~2,200줄 + C++/CUDA ~500줄 |
가장 중요한 건 마지막 줄입니다. 극단적인 지연 시간 방어에도 불구하고, 모델의 생성 품질은 거의 관측되지 않을 수준으로만 변했습니다. 추천 정확도나 분류 성능에 실질적 영향이 없다는 뜻입니다.
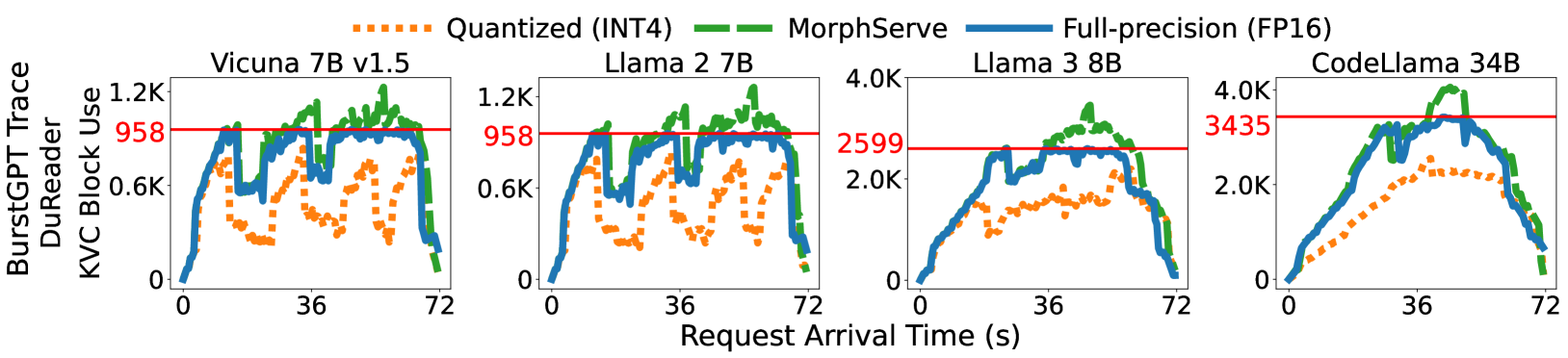
위 그래프를 보면, 정밀도 서빙(회색)은 트래픽 폭주 시 KV 캐시가 포화되어 지연이 급등하는 반면, MorphServe(녹색)는 KV 캐시 용량을 동적으로 조절하며 안정적인 레이턴시를 유지합니다.
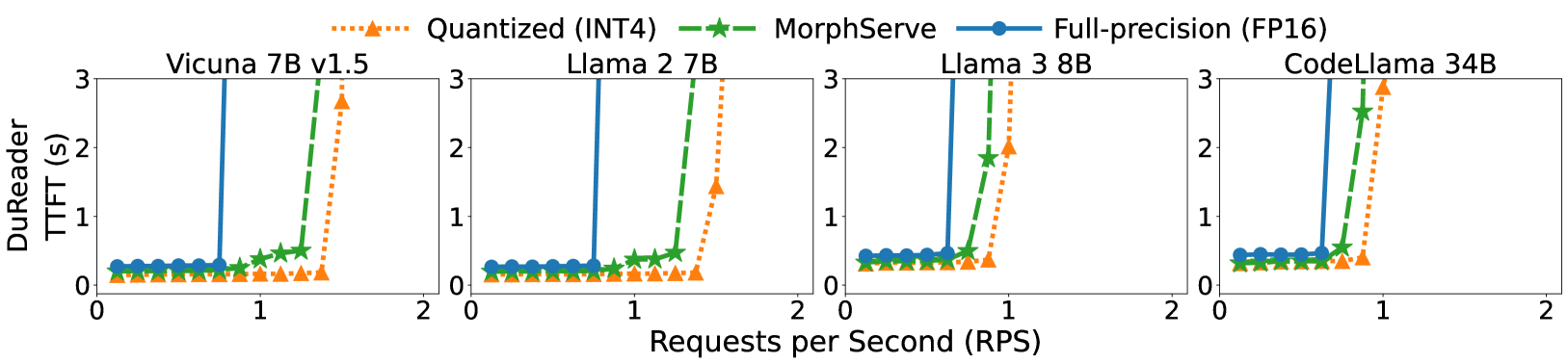
처리량 관점에서도, MorphServe는 정밀도 서빙이 포화되는 요청률에서도 안정적으로 동작합니다. 포화 지점(saturation point)을 뒤로 미루는 효과입니다.
서빙 인프라에 MorphServe를 적용하면?
추천/분류 시스템은 Vol.1의 CIR로 상품을 찾고, Vol.2의 ColPali로 후기를 검색하고, Vol.3의 MRL/CSR로 검색 속도를 최적화합니다. 이 파이프라인을 구동하는 VLM 추론 서버에 MorphServe를 적용하면 이런 구조가 됩니다:
평시 (트래픽 보통)
VLM 서버가 FP16 정밀도로 동작합니다. ColPali 임베딩 생성, 추천 랭킹, 이미지 분류 모두 최고 품질로 처리됩니다. KV 캐시도 넉넉하게 유지됩니다.
폭주 시 (주말 특가, 타임딜)
Serving Monitor가 TTFT 급등과 VRAM 압력을 감지합니다. Morphing Controller가 영향도 낮은 레이어를 INT8로 스와핑 결정을 내립니다. KV 캐시도 동적으로 축소됩니다. 사용자는 추천 결과를 계속 받아보고, SLO는 유지됩니다.
트래픽 감소
부하가 줄어들면 자동으로 정밀도 레이어로 복원됩니다. 별도의 수동 개입 없이, 모델이 트래픽에 맞춰 스스로 적응하는 구조입니다.
평가 지표
MorphServe 도입 효과를 측정하려면 두 가지를 동시에 봐야 합니다:
- 인프라 지표: P95/P99 TTFT, SLO 위반율, GPU 활용률, OOM 발생 빈도
- 비즈니스 지표: 추천 정확도(정밀도↔양자화 전환 시 변화), 페이지 로딩 시간, 전환율
다음 글에서는 MorphServe의 기반이 되는 어텐션 엔진 자체를 최적화하는 방법, MLSys 2025 최우수 논문 FlashInfer의 Block-sparse 포맷을 다루겠습니다.
FAQ
MorphServe란 무엇인가?
트래픽 부하에 따라 LLM/VLM 모델의 레이어를 정밀도(FP16)↔양자화(INT8)로 실시간 전환하는 동적 서빙 프레임워크입니다. 두 가지 핵심 메커니즘(양자화 레이어 스와핑 + 압력 인지형 KV 캐시 리사이징)으로, 정밀도 서빙 대비 SLO 위반율을 92.45% 줄이고 P95 TTFT를 2.2x-3.9x 개선합니다(arXiv, 2025).
양자화 레이어 스와핑은 기존 정적 양자화와 뭐가 다른가?
정적 양자화는 모든 레이어를 항상 양자화 상태로 유지합니다. 트래픽이 적을 때도 품질 손실이 발생합니다. MorphServe의 레이어 스와핑은 필요할 때만 영향도 낮은 레이어를 양자화하고, 부하가 줄면 정밀도로 복원합니다. 평시에는 최고 품질, 폭주 시에만 선택적 양자화입니다.
KV 캐시 리사이징은 왜 필요한가?
KV 캐시는 LLM 추론에서 GPU VRAM의 주요 소비원입니다. 긴 컨텍스트 요청이 몰리면 VRAM이 가득 차서 OOM 크래시가 발생합니다. MorphServe는 메모리 압력을 실시간 모니터링하고, 임계치 돌파 시 과거 토큰의 KV 캐시를 동적으로 축소하여 OOM을 방지하면서 새 요청을 수용합니다.
MorphServe를 도입하면 추천 품질이 떨어지지 않나?
Vicuna, Llama 계열 실험에서 생성 품질 저하는 거의 관측되지 않았습니다(arXiv, 2025). 영향도가 적은 레이어만 선택적으로 양자화하고, 트래픽이 줄면 즉시 복원하기 때문입니다. 실제 도입 시에는 추천 정확도 A/B 테스트로 검증이 필요합니다.
이 시리즈의 Vol.1-4는 어떻게 연결되나?
Vol.1(CIR)로 상품을 찾고, Vol.2(ColPali)로 후기를 검색하고, Vol.3(MRL/CSR)로 검색 속도를 최적화하고, Vol.4(MorphServe)로 이 모든 것을 구동하는 추론 서버의 안정성을 확보합니다. 검색 모델 → 검색 인프라 → 서빙 인프라로 이어지는 완전한 파이프라인입니다.
마치며
LLM/VLM 서빙의 현실은 "항상 최고 품질" 또는 "항상 양자화" 중 하나를 선택하는 게 아닙니다. 트래픽은 동적이니, 서빙도 동적이어야 합니다.
- MorphServe는 레이어 스와핑과 KV 캐시 리사이징이라는 두 가지 런타임 메커니즘으로, 정밀도 서빙 대비 SLO 위반율 92.45% 감소와 P95 TTFT 2.2x-3.9x 개선을 달성합니다
- 이커머스처럼 트래픽 변동이 심한 환경에서 "평시 정밀도, 폭주 시 양자화"라는 적응형 전략이 현실적입니다
- Python ~2,200줄 + C++/CUDA ~500줄의 상대적으로 경량 구현이어서, 기존 서빙 프레임워크에 통합 가능합니다
다음 글에서는 어텐션 엔진 자체를 최적화하는 FlashInfer(MLSys 2025 최우수 논문)의 Block-sparse 포맷과 메모리 처리량 증가를 다루겠습니다.
References
- Chen et al. "MorphServe: Efficient and Workload-Aware LLM Serving via Runtime Quantized Layer Swapping and KV Cache Resizing." arXiv, 2025. Link
- Deloitte. "AI Compute Shift from Training to Inference." via Computerworld, 2025. Link
- a16z. "LLMflation: LLM Inference Cost." 2024. Link
- Kwon et al. "Efficient Memory Management for Large Language Model Serving with PagedAttention (vLLM)." SOSP, 2023. Link