핵심 요약
- MRL은 하나의 모델에서 다중 차원 임베딩을 동시에 뽑아, 8.3% 크기에서도 원본 성능의 98.37%를 유지합니다 (NeurIPS 2022)
- CSR은 사전학습 임베딩을 희소 공간에 매핑하여, 재학습 없이 MRL 대비 검색 속도 최대 69배 향상을 달성했습니다 (ICML 2025)
- 64차원 조대 검색 → 원본 차원 정밀 랭킹의 2단계 구조로 5.2TB 스토리지를 0.33TB로 줄일 수 있습니다
- 벡터 DB 시장은 USD 1.5B(2023)에서 USD 4.3B(2028)로 연 23.3% 성장이 전망됩니다 (MarketsandMarkets, 2023)
Intro
MRL과 CSR은 고차원 벡터의 스토리지와 검색 비용을 수십 배 줄이는 임베딩 최적화 기법입니다. MRL은 8.3% 크기에서도 원본 성능의 98.37%를 유지하고(NeurIPS 2022), CSR은 재학습 없이 동일 연산량에서 MRL 대비 7-17% 높은 정확도를 달성합니다(ICML 2025).
이전 글에서 ColPali가 페이지당 1024개의 128차원 벡터를 만든다고 했습니다. 인테리어 후기가 1000만 건이라면, 저장해야 할 벡터는 약 100억 개입니다. float32 기준으로 스토리지만 약 5.2TB가 필요합니다. 이 규모의 벡터를 전수 검색하는 건 물리적으로 불가능합니다.
어떻게 줄일 수 있을까요? 두 가지 방향이 있습니다. 벡터 차원 자체를 줄이거나(MRL), 벡터를 희소하게 만들어서 실제 연산량을 줄이거나(CSR). 이 글에서는 두 접근법을 비교하고, 벡터 DB 하이브리드 검색과 결합한 실전 파이프라인을 정리합니다.
왜 벡터 차원이 문제인가?
수천만 규모의 멀티모달 검색에서 고차원 벡터는 스토리지 비용과 쿼리 레이턴시를 기하급수적으로 증가시킵니다. 기업용 비정형 데이터의 80-90%가 이미지, 문서, 표 형태라는 Gartner 조사(Edge Delta, 2024)를 고려하면, 이 문제는 점점 더 심각해집니다.
구체적으로 계산해 보겠습니다. ColPali가 생성하는 임베딩 기준으로:
| 차원 | 페이지당 벡터 크기 | 1000만 페이지 스토리지 | 상대 검색 속도 |
|---|---|---|---|
| 128 (원본) | 512KB | ~5.2TB | 1x (기준) |
| 64 | 256KB | ~2.6TB | ~2x |
| 32 | 128KB | ~1.3TB | ~4x |
| 16 | 64KB | ~0.65TB | ~8x |
문제는 차원을 단순히 자르면 검색 품질이 급락한다는 점입니다. PCA 같은 사후 차원 축소(post-hoc dimensionality reduction)는 원본 임베딩 공간의 분산을 최대화하도록 설계되어 있지, 검색 품질을 보존하도록 설계되어 있지 않습니다. 그래서 MRL처럼 학습 단계에서 차원 축소를 고려하거나, CSR처럼 아예 다른 표현 공간으로 매핑하는 접근이 필요합니다.
마트로시카 임베딩(MRL)은 어떻게 차원을 줄이는가? (NeurIPS 2022)
MRL(Matryoshka Representation Learning)은 학습 시 다층 손실 함수를 적용하여, 앞쪽 차원에 핵심 정보가 집중되도록 훈련하는 기법입니다. 8.3% 크기(1024차원 → 64차원)에서도 원본 성능의 98.37%를 유지합니다(HuggingFace, 2024).
이름의 유래는 러시아 마트로시카 인형입니다. 큰 인형 안에 작은 인형이, 그 안에 더 작은 인형이 들어있는 구조처럼, 1024차원 벡터 안에 512차원 벡터가, 그 안에 256차원 벡터가 중첩되어 있습니다.
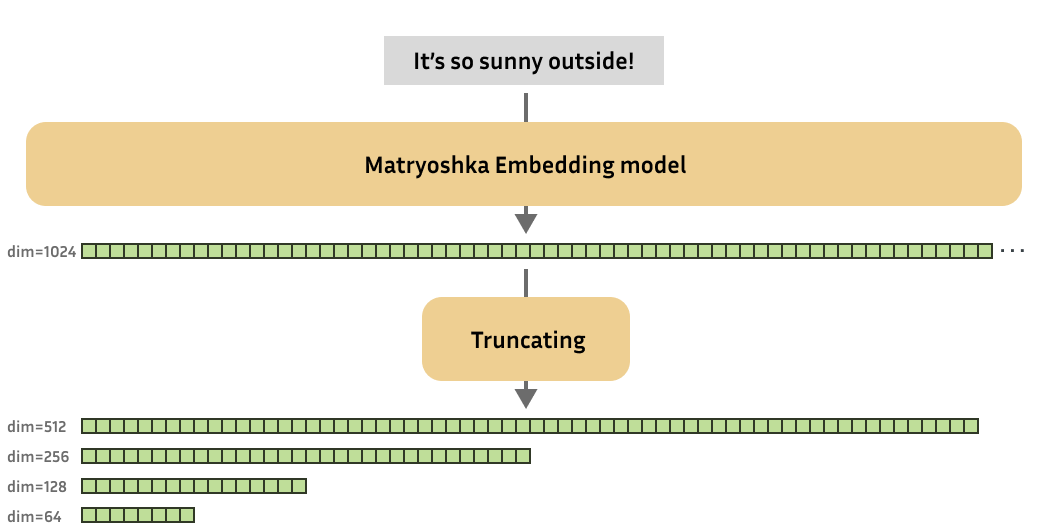
학습 원리는 이렇습니다. 일반적인 임베딩 모델은 최종 차원(예: 1024)에서만 손실 함수를 계산합니다. MRL은 여기에 더해서 64, 128, 256, 512 차원에서도 동시에 손실을 계산하고, 이 모든 손실을 합산합니다. 모델은 앞쪽 64개 차원만으로도 검색 품질이 유지되도록, 핵심 의미 정보를 앞쪽에 집중시키는 법을 학습합니다.
사용법도 간단합니다. 추론 시에는 원하는 차원까지만 잘라서(truncation) 정규화(normalization)하면 끝입니다. 별도의 변환 모델이나 추가 연산이 필요 없습니다.
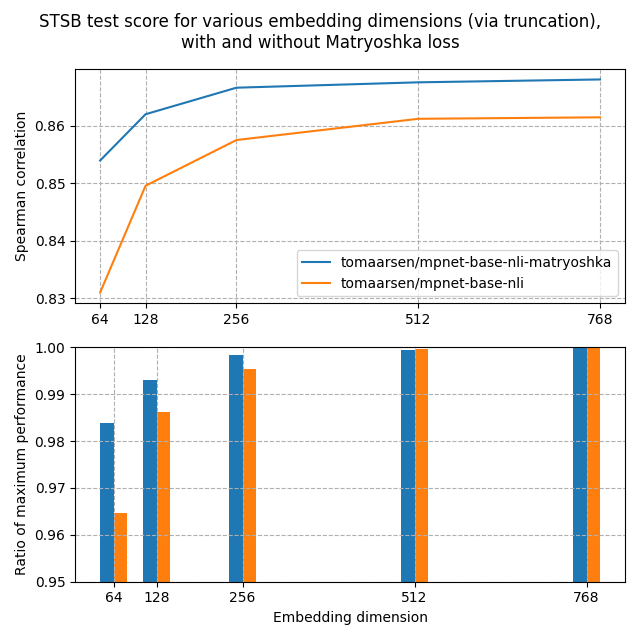
ImageNet-1K에서 MRL은 14배 작은 표현으로 동일한 정확도를 달성했고, 대규모 검색에서 14배 실제 속도 향상을 보였습니다(NeurIPS 2022). MRL의 실전적 위력을 보여주는 사례가 있는데요, OpenAI의 text-embedding-3-large는 256차원만으로도 이전 모델 ada-002의 1536차원 성능을 능가합니다. 6배 작은 벡터로 더 좋은 검색 품질을 얻는 겁니다(OpenAI, 2024). Nomic, Cohere, Alibaba GTE, Mixedbread 등도 MRL을 채택했습니다.
MRL의 실전 활용: 2단계 검색
MRL의 가장 실용적인 활용법은 2단계 검색입니다. 64차원 초소형 임베딩으로 벡터 DB에서 상위 1,000개 후보를 빠르게 추출하고, 원본 차원에서 정밀 랭킹을 매기는 구조입니다. 이전 글에서 다룬 Late Interaction(MaxSim)을 정밀 랭킹 단계에 쓸 수 있습니다.
CSR은 MRL의 한계를 어떻게 넘는가? (ICML 2025)
MRL은 강력하지만 두 가지 한계가 있습니다. 첫째, 전체 모델을 재학습해야 합니다. ColPali처럼 이미 학습된 VLM의 임베딩을 MRL로 바꾸려면 처음부터 다시 학습해야 한다는 뜻입니다. 둘째, 저차원(특히 64 이하)에서 성능이 눈에 띄게 떨어집니다.
CSR(Contrastive Sparse Representation)은 이 두 가지를 동시에 해결합니다. ICML 2025에서 Oral로 발표된 이 논문은 사전학습된 임베딩을 건드리지 않고, 경량 어댑터만 학습해서 희소(sparse) 고차원 공간으로 매핑합니다.
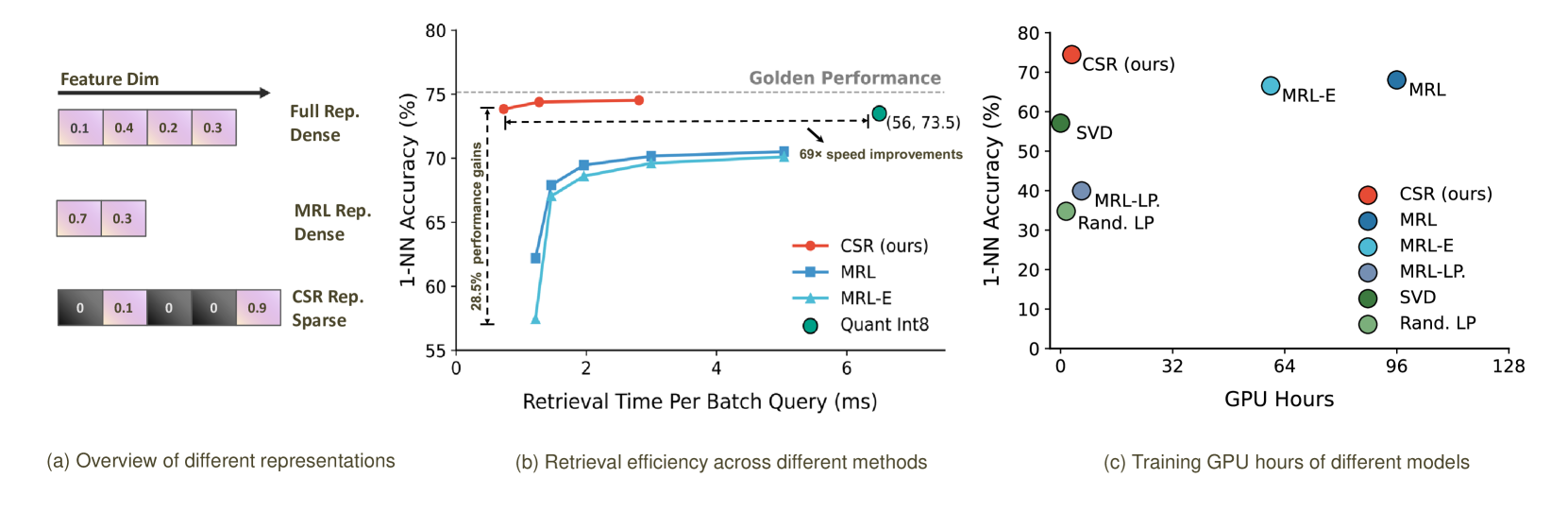
아이디어가 재밌습니다. MRL이 1024차원을 64차원으로 "압축"하는 접근이라면, CSR은 반대로 1024차원을 4096차원으로 "확장"합니다. 대신 TopK 활성화를 적용해서, 실제로 켜지는 차원은 64개 등 소수만 남깁니다. 나머지 차원은 0이니 저장하지 않아도 됩니다.
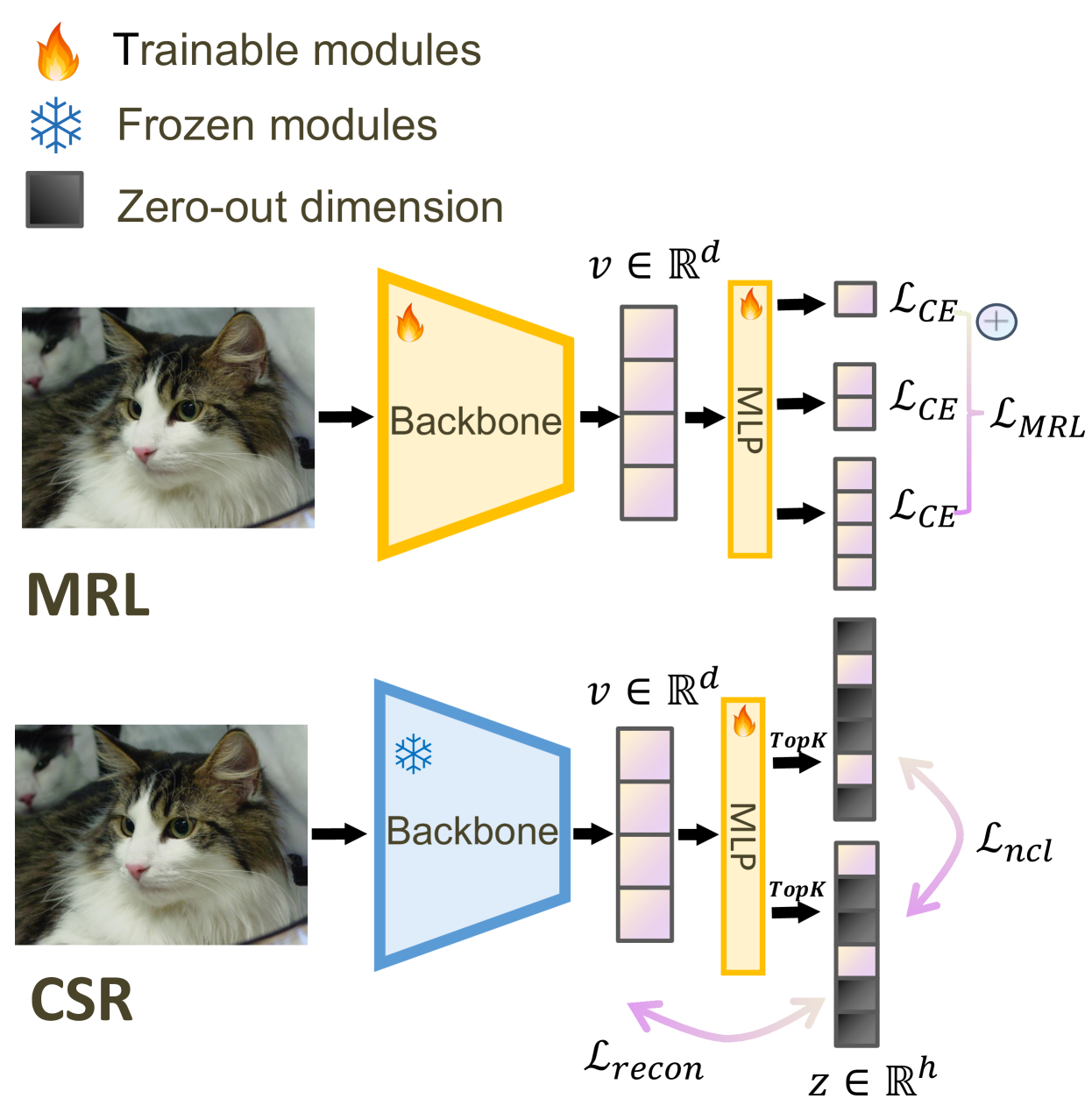
구체적으로는 이렇습니다:
- 사전학습된 임베딩(예: ColPali의 128차원)을 경량 오토인코더에 통과시킵니다
- 고차원 희소 공간(예: 4096차원)으로 투영합니다
- TopK 활성화로 상위 K개 차원만 남기고 나머지를 0으로 만듭니다
- 재구성 손실(reconstruction loss)과 비음수 대비 손실(non-negative contrastive loss)로 학습합니다
CSR의 핵심: 왜 희소 활성화가 효과적인가?
직관적으로, 모든 문서가 모든 차원의 정보를 필요로 하지 않습니다. "화이트 톤 주방" 후기와 "빈티지 원목 서재" 후기는 서로 다른 피처 차원이 활성화되어야 합니다. 희소 활성화는 이 직관을 수학적으로 구현한 것입니다.
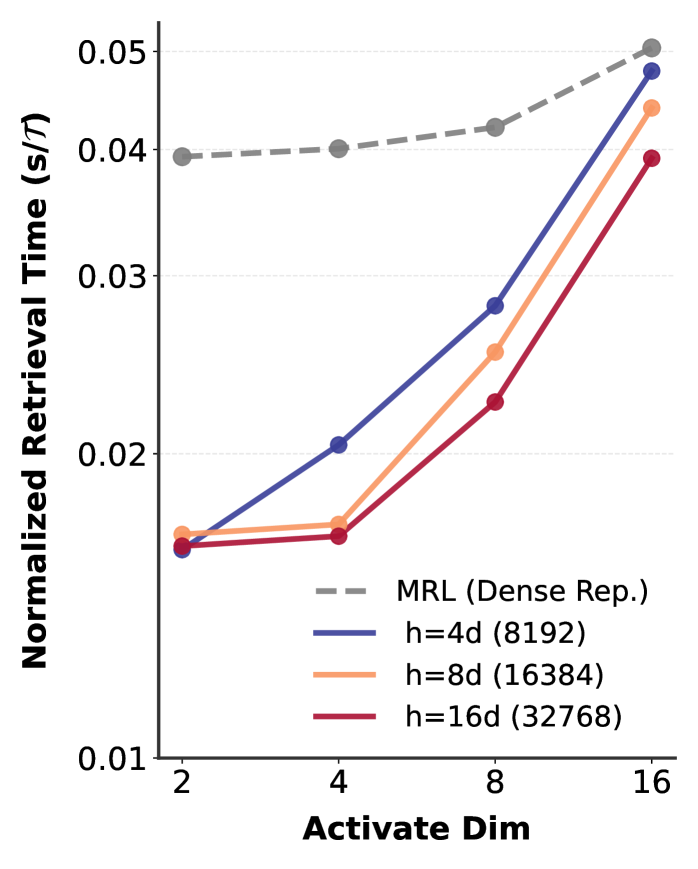
결과적으로, 동일한 연산량에서 CSR은 MRL 대비 ImageNet 분류 17%, MTEB 텍스트 검색 15%, MS COCO 검색 7% 높은 정확도를 보였고, 검색 속도는 최대 69배 빠릅니다(ICML 2025). 학습 시간도 MRL의 극히 일부만 필요합니다.
MRL vs CSR: 언제 뭘 써야 하는가?
모델을 재학습할 수 있으면 MRL의 생태계 성숙도가 유리하고, 사전학습 모델을 그대로 써야 하면 CSR의 재학습 불필요 장점이 결정적입니다.
| 구분 | MRL | CSR |
|---|---|---|
| 발표 | NeurIPS 2022 | ICML 2025 (Oral) |
| 접근법 | 다중 차원 손실 함수로 학습 | 사전학습 임베딩 + 희소 코딩 |
| 재학습 | 전체 모델 재학습 필요 | 경량 어댑터만 학습 |
| 차원 축소 | 앞쪽 N차원 truncation | 희소 TopK 활성화 |
| 동일 연산량 성능 | 기준선 | 7-17% 우수 |
| 검색 속도 | 14배 빠름 (vs 원본) | 최대 69배 빠름 (vs 원본) |
| 생태계 | OpenAI, Nomic 등 광범위 채택 | 초기 단계 (ICML 2025) |
| 적용 시나리오 | 새 모델 학습 가능할 때 | 기존 모델 임베딩 최적화 |
ColPali(PaliGemma-3B)의 임베딩은 이미 학습된 상태입니다. 이 임베딩을 MRL로 바꾸려면 ColPali 전체를 재학습해야 하지만, CSR은 경량 어댑터만 추가하면 됩니다. 빠른 프로토타이핑이 필요한 팀이라면 CSR이 현실적인 선택입니다.
반면, 임베딩 모델을 처음부터 학습하거나, 이미 MRL을 지원하는 모델(OpenAI, Nomic 등)을 쓸 수 있는 상황이라면 MRL의 단순한 사용법(truncation만)과 검증된 생태계가 장점입니다.
벡터 DB에서 하이브리드 검색은 왜 필요한가?
순수 벡터 검색만으로는 키워드 매칭이 필요한 쿼리에서 리콜(Recall)이 떨어집니다. "한샘 시스템 주방"을 검색할 때, 벡터 유사도는 "비슷한 분위기의 주방"을 찾아주지만, "한샘"이라는 브랜드명을 정확히 매칭하지 못할 수 있습니다. Dense Vector(의미 검색)와 Sparse/BM25(키워드 매칭)를 결합한 하이브리드 검색이 프로덕션에서 표준이 되고 있는 이유입니다.
Milvus 2.5는 네이티브 하이브리드 검색을 도입했고, BM25 성능이 Elasticsearch 대비 4배 빠릅니다(Milvus Blog, 2024). JSON 메타데이터 필터링은 최대 100배 빠른 Path Index를 제공합니다.
Milvus vs pgvector: 언제 뭘 쓰나?
| 구분 | Milvus | pgvector |
|---|---|---|
| 규모 | 수천만~수억 벡터 | 수백만 이하 |
| 인프라 | 독립 클러스터 (Kubernetes) | PostgreSQL 확장 |
| 하이브리드 검색 | 네이티브 지원 | 별도 구현 필요 |
| 다중 벡터 | ColPali/ColBERT 지원 | 제한적 |
| 적용 시나리오 | 대규모 프로덕션 | 빠른 프로토타이핑 |
수천만 UGC에서는 Milvus가 적합하고, PoC 단계에서 빠르게 검증하려면 pgvector로 시작하는 게 현실적입니다. RunPod Serverless 같은 서버리스 인프라와 결합하면 초기 비용을 낮출 수 있습니다.
UGC에 적용하면 어떤 파이프라인이 필요한가?
MRL 64차원으로 조대 검색 후 원본 다중 벡터로 정밀 랭킹하는 2단계 구조가 스토리지를 16배 줄이면서 검색 품질을 유지합니다. Vol.1의 CIR, Vol.2의 ColPali, 그리고 이 글의 MRL/CSR을 결합하면 완전한 검색 파이프라인이 됩니다.
1단계: 조대 검색 (MRL 64차원)
MRL로 축소된 64차원 임베딩을 HNSW 인덱스에 저장합니다. 쿼리가 들어오면 이 초소형 벡터로 상위 1,000개 후보를 밀리초 안에 추출합니다. 스토리지는 5.2TB에서 약 0.33TB로, 16배 절감됩니다.
2단계: 정밀 랭킹 (MaxSim)
1,000개 후보에 대해서만 원본 다중 벡터 간 Late Interaction(MaxSim)을 계산합니다. Vol.2에서 다룬 ColPali의 검색 메커니즘을 그대로 씁니다. 전체 DB가 아닌 1,000개만 연산하니 비용이 합리적입니다.
3단계: 하이브리드 보정
BM25 텍스트 점수와 벡터 유사도를 가중 결합합니다. "한샘 시스템 주방"처럼 브랜드명이 포함된 쿼리에서 리콜을 방어합니다. 순수 벡터 검색이 놓치는 키워드 매칭을 Sparse 검색이 보완하는 구조입니다.
평가 지표
Vol.2에서 언급한 것처럼 모델 성능(NDCG@5, Recall@10)과 비즈니스 지표(클릭률, 전환율)를 동시에 추적해야 합니다. 여기에 더해서 "MRL 64차원 조대 검색의 Recall@1000"이 핵심 지표가 됩니다. 정밀 랭킹 단계에서 아무리 정확해도, 조대 검색 단계에서 정답이 빠지면 의미가 없으니까요.
다음 글에서는 이 파이프라인의 VLM 추론 서버가 트래픽 폭주에 어떻게 살아남는지, MorphServe의 압력 인지형 런타임 양자화를 다루겠습니다.
FAQ
MRL(마트로시카 표현 학습)이란 무엇인가?
학습 시 다층 손실 함수를 적용하여, 하나의 모델에서 64/128/256/1024 차원 임베딩을 동시에 뽑는 기법입니다. 러시아 마트로시카 인형처럼 큰 벡터 안에 작은 벡터가 중첩됩니다. OpenAI text-embedding-3-large, Nomic, Alibaba GTE 등이 채택했고, 8.3% 크기에서도 원본 성능의 98.37%를 유지합니다(NeurIPS 2022).
CSR과 MRL의 핵심 차이는 무엇인가?
MRL은 전체 모델을 재학습해야 하지만, CSR은 사전학습된 임베딩에 경량 어댑터만 추가하면 됩니다. CSR은 임베딩을 고차원 희소 공간으로 매핑하고 TopK 활성화를 적용하는 방식으로, 동일 연산량에서 MRL 대비 7-17% 높은 정확도와 최대 69배 빠른 검색 속도를 달성합니다(ICML 2025).
MRL 64차원으로 줄이면 정확도가 얼마나 떨어지나?
HuggingFace의 벤치마크에 따르면, MRL로 학습된 모델은 64차원(원본의 8.3%)에서도 Spearman 유사도 기준 원본 성능의 98.37%를 유지합니다(HuggingFace, 2024). PCA 같은 사후 차원 축소(96.46%)보다 일관되게 높은 성능을 보입니다. 다만 도메인에 따라 차이가 있으므로, 실제 적용 시에는 타겟 데이터셋에서 벤치마크가 필요합니다.
벡터 DB에서 하이브리드 검색은 왜 필요한가?
Dense Vector(의미 검색)만으로는 "한샘 시스템 주방"처럼 특정 키워드가 중요한 쿼리에서 리콜이 떨어집니다. BM25(키워드 매칭)를 결합한 하이브리드 검색이 이 문제를 해결합니다. Milvus 2.5는 네이티브 하이브리드 검색을 지원하며, BM25 성능이 Elasticsearch 대비 4배 빠릅니다(Milvus Blog, 2024).
Vol.2의 ColPali와 Vol.3의 MRL/CSR은 어떻게 결합하나?
ColPali가 생성한 다중 벡터 임베딩에 MRL 또는 CSR을 적용하여 차원을 줄이고, 줄인 벡터를 Milvus에 저장합니다. 검색 시에는 MRL 64차원으로 조대 후보를 추출한 뒤, 원본 벡터 간 Late Interaction(MaxSim)으로 정밀 랭킹을 매기는 2단계 구조입니다. Vol.1의 CIR로 상품을 찾고, Vol.2의 ColPali로 후기를 검색하고, Vol.3의 MRL/CSR로 검색 속도를 최적화하면 완전한 파이프라인이 됩니다.
마치며
벡터 검색의 비용은 "차원 × 벡터 수"로 결정됩니다. MRL과 CSR은 이 공식의 "차원"을 수십 배 줄이는 기술입니다.
- MRL은 학습 단계에서 차원 축소를 고려하여 8.3% 크기에서도 98.37% 성능을 유지하고, OpenAI 등이 이미 채택한 검증된 접근입니다
- CSR은 재학습 없이 사전학습 임베딩을 희소 공간으로 매핑하여, MRL 대비 7-17% 성능 우위와 최대 69배 속도 향상을 달성합니다
- 64차원 조대 검색 → MaxSim 정밀 랭킹 → BM25 하이브리드 보정의 3단계 파이프라인이 수천만 UGC 검색의 현실적 해답입니다
References
- Kusupati et al. "Matryoshka Representation Learning." NeurIPS, 2022. Link
- HuggingFace. "Introduction to Matryoshka Embedding Models." 2024. Link
- Wen et al. "Beyond Matryoshka: Revisiting Sparse Coding for Adaptive Representation (CSR)." ICML, 2025. Link
- Milvus. "Milvus 2.5 Launch." Milvus Blog, 2024. Link
- Zilliz. "Matryoshka Representation Learning Explained." 2024. Link
- MarketsandMarkets. "Vector Database Market Worth $4.3 Billion by 2028." 2023. Link
- OpenAI. "New Embedding Models and API Updates." 2024. Link
- Gartner. "Unstructured Data Statistics." via Edge Delta, 2024. Link
- Weaviate. "OpenAI's Matryoshka Embeddings in Weaviate." Link