핵심 요약
- 진짜 중요한 업무 지식은 문서에 없습니다 — 경력자의 머릿속에 암묵지(Tacit Knowledge)로 존재합니다
- 에이전틱 워크(Agentic Work)로 업무를 수행하면, 에이전트에게 맥락을 전달하는 과정에서 암묵지가 자연스럽게 외현화됩니다
- Interloom은 1,650만 달러 투자를 유치하며, 운영 기록에서 "컨텍스트 그래프"를 자동 구축하는 접근을 상용화하고 있습니다
- 암묵지 충돌은 팩트 체크 → 맥락 세분화 → 휴먼 인 더 루프 3단계로 대응합니다
들어가며 — 왜 사내 GPT만으론 부족한가
많은 기업이 RAG, 벡터 DB, OCR을 활용해 사내 문서를 전산화하고 "사내 GPT"를 구축하고 있습니다. 하지만 실제로 써보면 기대만큼 답변 품질이 안 나오는 경우가 많습니다.
왜 그럴까요? 진짜 중요한 지식 상당수가 애초에 문서에 없기 때문일 수 있습니다.
California Management Review는 2026년 3월 기고문에서 이렇게 진단합니다 — 에이전틱 AI 시대의 진짜 차별화 요소는 데이터도 모델도 아닌, 사람들의 판단에 내재된 암묵지(Tacit Knowledge)라고요(California Management Review, 2026.03).
같은 시기 Fortune지는 암묵지를 "컨텍스트 그래프"로 구조화하는 스타트업 Interloom의 1,650만 달러 투자 유치를 소개했습니다(Fortune, 2026.03). Enterprise Knowledge의 2026년 KM 트렌드 보고서는 "엔터프라이즈 수준의 암묵지 포착"을 올해 핵심 트렌드로 꼽았고요(Enterprise Knowledge, 2026.01).
이 글에서는 최신 연구와 사례를 바탕으로 암묵지를 어떻게 수집하고, 어떤 구조로 관리할 수 있는지 정리해봤습니다.
1. 암묵지란 무엇인가 — "우리는 말할 수 있는 것보다 더 많이 안다"
1-1. 정의: 머릿속에만 있는 업무 노하우
영국-헝가리 출신의 철학자 마이클 폴라니(Michael Polanyi)는 "We know more than we can tell(우리는 말할 수 있는 것보다 더 많이 안다)"이라는 유명한 문장으로 암묵지를 정의했습니다.

좀 더 쉽게 풀면 이런 겁니다:
"문서에 적혀 있지도, 영상에 나와 있지도, 업무 가이드에 표현되어 있지도 않은, 머릿속에만 있는 업무 노하우"
경험이 쌓이면서 만들어지고, 사수한테 구전되고, "우리 회사에서는 원래 그렇게 해"라는 말로 전달되는 것들이죠. 경력이 오래될수록 이게 많아집니다.
1-2. 현장에서 만나는 암묵지의 실제 모습
예를 들어볼게요:
회계팀의 계정과목 분배 규칙 — "A 부서의 접대비는 이 계정과목으로 분류하고, B 부서는 접대비 한도를 넘으면 다른 계정과목을 활용한다." 어디에도 명문화되어 있지 않지만, 회계 담당자의 머릿속에는 또렷이 있는 규칙입니다.
보고 자료의 암묵적 포맷 — "차장님께 보고할 때는 영상 콘텐츠를 직접 넣지 말고, 스크린 캡처해서 발표 자료 형태로 만들어야 한다." 매뉴얼에 없지만, 그 팀에서는 모두가 아는 불문율이죠.
재고 관리의 판단 기준 — "프로모션 기간에는 재고가 평시보다 특정 수준 이하로 떨어지면 협력사에 추가 요청을 한다." 그 "특정 수준"은 담당자 머릿속에만 있습니다.
California Management Review는 자동차 제조사 사례를 소개하는데요. 수십 년 경력의 마스터 엔지니어들이 모호한 이슈를 진단하고 트레이드오프를 해결하며 쌓은 판단력이 제품 품질과 개발 속도의 핵심이었지만, 은퇴가 늘면서 이 지식에 접근하기 어려워졌습니다.
1-3. 암묵지 vs 형식지 — 왜 구분이 중요한가
| 구분 | 형식지(Explicit Knowledge) | 암묵지(Tacit Knowledge) |
|---|---|---|
| 존재 형태 | 문서, 매뉴얼, SOP, 위키 | 머릿속, 경험, 직관 |
| 전달 방식 | 읽기, 검색 | 구전, 도제식 교육, 관찰 |
| AI 활용 | RAG, 벡터 DB로 검색 가능 | 구조화 없이는 활용 불가 |
| 기업의 현재 상태 | 전산화 진행 중 | 대부분 방치됨 |
지금 대부분의 기업 AI 프로젝트는 형식지를 다루고 있는데, 정작 경쟁력의 차이를 만드는 건 암묵지 쪽이 아닐까요?
노나카 이쿠지로(Nonaka Ikujiro)와 타케우치 히로타카(Takeuchi Hirotaka)가 제안한 SECI 모델은 암묵지와 형식지가 어떻게 상호 전환되는지를 설명합니다. Socialization(공동화) → Externalization(표출화) → Combination(연결화) → Internalization(내면화)의 네 단계를 거치며 조직 지식이 창출된다는 거죠.
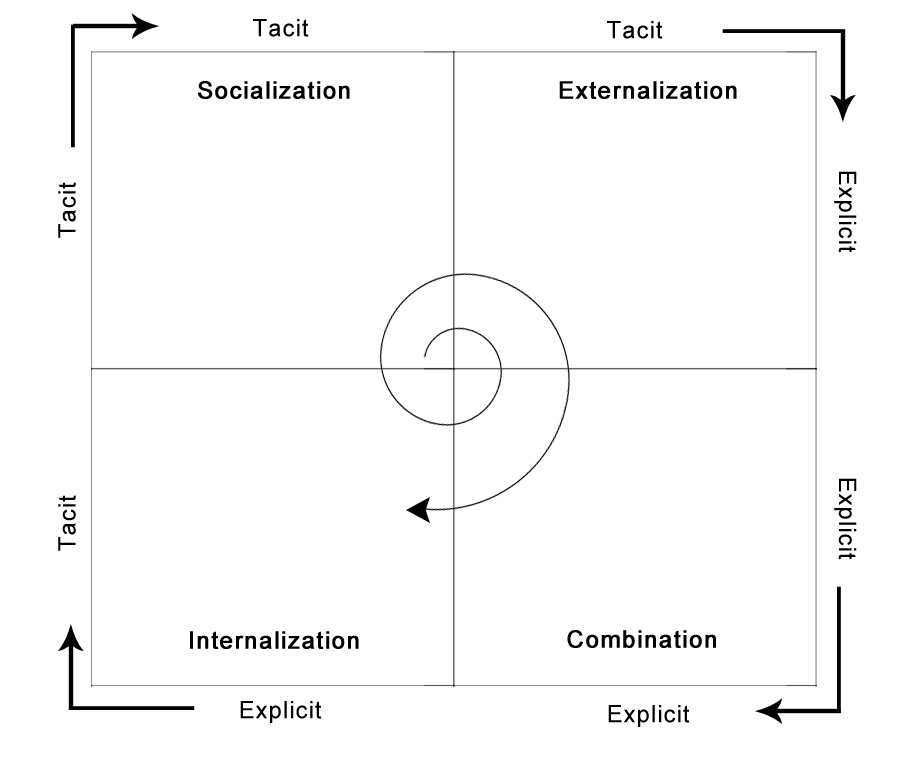
에이전틱 워크가 이 맥락에서 주목받는 건, SECI 모델의 Externalization(표출화) 단계를 자연스럽게 촉진하기 때문입니다. 암묵지가 형식지로 바뀌는 그 단계요.
2. 암묵지를 어떻게 수집할 것인가
2-1. 기존 방식이 실패하는 이유
Enterprise Knowledge의 2026년 보고서에 따르면, 디지털 미팅과 AI 노트 테이킹의 발전으로 엔터프라이즈 수준 암묵지 프로그램의 빌딩 블록이 마련되었지만, 기존 수집 방식은 여전히 한계가 있습니다(Enterprise Knowledge, 2026.01).

전통적인 암묵지 수집 방식은 이랬습니다:
- "업무 노하우를 적어내세요"
- "지식 공유 세션을 진행합니다"
- "업무 프로세스를 문서화하세요"
그런데 이런 방식이 잘 작동했다는 이야기를 별로 들어본 적이 없습니다.
시니어들이 자신의 암묵지를 적극적으로 공개하지 않는 문제도 있고, 본인의 업무 방식이 밖에서 보면 비효율적으로 보일까봐 꺼리는 경우도 있습니다. 그보다 더 근본적인 문제는, 본인도 자기가 어떤 암묵지를 갖고 있는지 모른다는 거예요. 암묵지는 의식적으로 꺼내는 게 아니라 업무 상황에서 그냥 나오는 거니까요.
2-2. 에이전틱 워크: 업무 도구를 직접 쓰지 않는 것
에이전틱 워크(Agentic Work)란, AI 에이전트가 나 대신 업무 도구를 다루게 하고, 이 에이전트를 계속 학습시키는 방식입니다. 시나리오로 비교하면 차이가 분명해집니다.
시나리오: 주간 매출 보고서 작성
🔧 기존 방식 (직접 도구 사용)
- 엑셀을 열어 데이터를 정리한다
- 파워포인트로 보고서를 만든다
- 차장님이 좋아하는 포맷으로 맞춘다
- → 결과물(보고서)만 남고, "왜 이렇게 만들었는지"는 사라짐
🤖 에이전틱 워크 (에이전트에게 업무 지시)
- 에이전트에게: "이번 주 매출 데이터로 보고서 만들어줘"
- 에이전트에게: "차장님 보고용이니까 영상 콘텐츠는 빼고 스크린 캡처 형태로"
- 에이전트에게: "B 부서 접대비는 한도 초과분이 있으니 별도 계정과목으로 처리해서 보여줘"
- → 결과물 + 의도와 맥락(암묵지)이 인풋 프롬프트로 기록됨
에이전틱 워크에서는 사수한테 설명하듯 에이전트에게 맥락을 전달하게 됩니다. "왜 이렇게 해야 하는지"를 말로 풀어주는 과정에서, 본인도 몰랐던 자기 암묵지가 드러나는 거죠.
2-3. 인풋 프롬프트 로깅 → 암묵지 센싱 루프
이걸 조직 차원에서 운영하려면 몇 단계가 필요합니다.
[Phase 1] 에이전트 인프라 구축
- 화이트칼라 업무 전반을 하나의 에이전트로 수행할 수 있는 환경을 세팅합니다
- 핵심은 "특정 업무 자동화 에이전트"가 아니라, "내가 하는 다양한 업무를 에이전트로 수행하는 구조"입니다
- 엑셀, 파워포인트, 슬랙, 노션 등 업무 도구를 에이전트가 다루게 합니다
[Phase 2] 인풋 프롬프트 로깅 시스템
- 누가(Who) 어떤 업무(What)를 에이전트에게 지시할 때, 어떤 맥락(Context)을 전달했는지를 체계적으로 기록합니다
- 에이전트에게 "왜 이렇게 해야 하는지"를 설명하는 순간, 그것이 곧 암묵지의 외현화입니다
[Phase 3] 암묵지 센싱 & 추출
- 로깅된 프롬프트에서 반복적으로 등장하는 맥락, 판단 기준, 예외 규칙을 AI가 자동 식별합니다
- 예: "김 차장님 보고" 관련 프롬프트에서 반복적으로 "영상 빼고 캡처로"라는 패턴이 감지되면 → 암묵지 후보로 포착됩니다
[Phase 4] 컨텍스트 그래프 반영 & PR 프로세스
- 포착된 암묵지를 컨텍스트 그래프에 반영하기 전, 개발의 PR 프로세스와 동일한 검증을 수행합니다
- Knowledge Manager가 이를 검토하고 승인합니다
[Phase 5] 성과 지표 연동 — 선순환 루프
- 에이전트에 암묵지를 잘 전달한 시니어가 생산성 향상으로 성과를 인정받는 구조를 만듭니다
- "내 지식을 뺏기면 끝"이 아니라, "내 암묵지를 에이전트에 녹여서 생산성이 몇 배가 되는 것" 자체가 성과가 됩니다
- 이 선순환이 만들어져야만 지속적인 암묵지 수집이 가능합니다
Interloom이라는 회사가 비슷한 방향으로 움직이고 있어서 참고할 만합니다. 이 회사는 수백만 건의 운영 기록(지원 이메일, 서비스 티켓, 통화 기록)을 분석해 "컨텍스트 그래프" — 조직 내에서 문제가 실제로 어떻게 해결되는지를 지속적으로 업데이트하는 지도 — 를 구축합니다(Fortune, 2026.03). CEO는 이를 구글 맵에 비유하는데요. 구글이 실시간 교통 데이터에서 최적 경로를 학습하듯, 컨텍스트 그래프는 전문가들이 문제를 해결하는 경로를 매핑합니다.
3. 컨텍스트 그래프 설계 — 지식만 넣으면 안 된다
3-1. 왜 "컨텍스트" 그래프인가
보통 지식 베이스는 "무엇을(What)"만 저장하는데, 컨텍스트 그래프는 "누가, 언제, 어떤 상황에서, 왜"까지 같이 들어갑니다.
앤트로픽(Anthropic)은 컨텍스트를 "LLM이 활용하는 토큰 집합"으로 정의하며, LLM을 효과적으로 다루려면 주어진 시점에서 모델이 접근할 수 있는 전체 상태를 고려하고, 그 상태가 어떤 행동을 유발하는지 예측하는 "컨텍스트 내 사고(Thinking in Context)"가 필요하다고 설명합니다. 테라데이터의 CTO는 더 직설적이에요. "컨텍스트 엔지니어링을 단발성 AI 프로젝트로 취급하면 실패하고, 조직의 기반 인프라 역량으로 인식해야 확장 가능한 AI 시스템을 구축할 수 있다"고요(CIO Korea, 2025.11).
3-2. 설계 원칙: 반드시 포함해야 할 메타데이터
암묵지를 컨텍스트 그래프에 저장할 때는 지식 내용뿐 아니라 맥락 정보도 같이 태깅해야 합니다:
| 태그 | 설명 | 예시 |
|---|---|---|
| 화자 (Who) | 이 지식을 제공한 사람 | 김 부장 (영업팀, 15년차) |
| 부서 (Department) | 같은 단어도 부서마다 의미가 다름 | HR팀의 "매출 정리" ≠ CS팀의 "매출 정리" |
| 직급 (Authority) | 의사결정 권한과 관련된 지식의 무게 | 부장의 판단 vs 사원의 관찰 |
| 상황 (Condition) | 이 지식이 적용되는 구체적 조건 | "프로모션 기간에만", "분기 마감 시에만" |
| 소스 (Source) | 수집 경로 | 프롬프트 로그, 팀 회의, 업무 피드백 |
3-3. 시나리오로 보는 컨텍스트 그래프 설계
일반 지식 베이스에 넣는다면 이렇게 되겠죠:
"프로모션 기간에 재고가 부족하면 협력사에 추가 요청한다"
컨텍스트 그래프에 넣는다면 이렇게 바뀝니다:
| 필드 | 값 |
|---|---|
| 지식 내용 | 프로모션 기간 재고 30% 이하 시 협력사 긴급 발주 |
| 화자 | 박 부장 (SCM팀, 12년차) |
| 부서 | Supply Chain Management |
| 적용 상황 | 프로모션 기간 (연 4회: 1월, 4월, 7월, 10월) |
| 소스 | 에이전트 프롬프트 로그 (2026.03.15) |
| 관련 지식 | → 협력사 긴급 발주 프로세스, → 프로모션 재고 기준표 |
| 충돌 가능 지식 | 이 차장의 "재고 20% 이하 시 발주" 기준과 상이 |
기술적으로는 그래프 DB가 자연스러운 선택이지만, RDB에서도 잘 설계하면 충분합니다. 도구 선택보다 메타데이터를 어떻게 모델링하느냐가 더 중요하거든요.
4. 암묵지 충돌 현상 — 가장 어렵고 가장 흥미로운 문제
4-1. 충돌은 반드시 일어난다
A 부장은 "재고 30% 이하일 때 발주"라고 하고, B 차장은 "20% 이하일 때 발주"라고 합니다. AI 에이전트는 어떤 판단을 따라야 할까요?
이것이 암묵지 충돌 현상입니다. Interloom이 커머츠방크에서 도입되었을 때도, 기존 내부 문서의 상당 부분이 서로 충돌하거나 불완전했습니다.
4-2. 충돌 대응의 3단계 프레임워크
1단계: 팩트 체크 — 틀린 정보 제거
가장 먼저 확인할 것은 "둘 중 하나가 사실과 다른가"입니다.
AI 에이전트가 충돌을 감지하면, 양쪽 지식을 ERP 데이터나 실제 발주 이력 등 팩트 데이터와 자동 대조합니다. "지난 3년간 프로모션 기간 실제 긴급 발주 시점"을 분석하면 어느 쪽이 현실에 가까운지 파악할 수 있죠. 이 검증 결과를 Knowledge 매니저에게 자동 보고합니다.
2단계: 맥락 세분화 — 컨텍스트 그래프의 진가
팩트로 해결되지 않는다면, 더 많은 맥락이 필요합니다.
A 부장의 "30% 기준"은 대형 프로모션(설/추석) 기준이고, B 차장의 "20% 기준"은 소규모 시즈널 프로모션 기준일 수 있습니다. 상황(Situation) 태그를 세분화하면 충돌이 아니라 조건부 분기로 전환되는 거예요.
3단계: 조직문화에 따른 판단 — 휴먼 인 더 루프
맥락을 세분화해도 여전히 충돌한다면? 이쯤 되면 기술의 문제가 아니라 조직문화의 문제에 가깝습니다.
결국 "원래 이 회사에선 어떻게 하는데요?"라는 질문으로 돌아옵니다.
AI가 충돌 상황을 정리해서 Knowledge 매니저에게 의사결정 요청서를 올립니다. "A 부장(12년차)은 30%를, B 차장(7년차)은 20%를 권장합니다. 지난 분기 실제 데이터는 28% 시점에서 발주가 이루어졌습니다. 어떤 기준을 채택할까요?" — 사람이 조직문화에 따라 최종 판단을 내리는 구조입니다.
5. Knowledge PR — 개발 문화에서 배우는 지식 관리
5-1. 코드의 PR처럼, 지식의 PR을
개발자 세계에서는 코드가 변경될 때 Pull Request를 올립니다. 무엇이 바뀌었는지, 왜 바뀌었는지를 정리하고, 시니어가 리뷰하죠.
지식도 같은 방식으로 다룰 수 있습니다:
| 코드 PR | Knowledge PR |
|---|---|
| 코드 변경사항 | 컨텍스트 그래프 변경사항 |
| diff (변경 전후 비교) | 지식 변경 전후 비교 |
| 코드 리뷰어 (테크리드) | Knowledge 매니저 |
| 머지 / 리젝트 | 반영 / 보류 / 추가 검증 요청 |
5-2. Knowledge PR 시나리오
마케팅팀 이 대리가 에이전트에게 반복적으로 "인스타그램 광고는 9:16, 페이스북은 1:1로 제작"이라고 지시한다고 가정해봅시다.
AI가 3회 이상 반복 패턴을 감지하면, 암묵지 후보로 식별합니다. 그리고 Knowledge PR이 자동 생성됩니다:
Knowledge PR #127
━━━━━━━━━━━━━━━━━━━━
📌 제목: 소셜 미디어 광고 소재 비율 규칙 추가
📂 대상: 마케팅팀 > 광고 소재 제작 프로세스
👤 소스: 이 대리 (마케팅팀, 2년차)
📊 근거: 프롬프트 로그 3건 (3/1, 3/8, 3/15)
[추가 내용]
- 인스타그램 광고 소재: 9:16 비율
- 페이스북 광고 소재: 1:1 비율
[충돌 검사] 기존 지식과 충돌 없음
[참고] 유튜브 숏츠 소재 비율 규칙은 미등록
→ Knowledge 매니저 검토 요청
Knowledge 매니저가 마케팅팀 리드에게 확인 후, 유튜브 숏츠 비율도 함께 추가하여 승인합니다. 이런 식으로 암묵지가 조직 자산으로 전환되는 거죠.
5-3. Knowledge 매니저의 부활
한때 지식경영(KM) 붐과 함께 주목받았다가 사라진 Knowledge 매니저라는 역할이 다시 떠오르고 있습니다. Enterprise Knowledge의 2026년 트렌드 보고서에 따르면, AI 노트 테이킹과 자동 전사, 디지털 미팅의 발전으로 암묵지 포착의 기술적 기반이 갖춰졌고, 이제 KM 전문가가 대화를 설계하고 전문성을 검증하는 역할을 맡아야 한다고 합니다(Enterprise Knowledge, 2026.01).
6. 실전 적용 로드맵
Gartner는 2026년 말까지 엔터프라이즈 앱의 40%에 AI 에이전트가 통합될 것으로 전망하지만(Gartner, 2025.08), Deloitte에 따르면 에이전틱 AI를 실제 프로덕션에서 사용 중인 조직은 11%에 불과합니다(Deloitte, 2025.12). 이 격차를 메우려면 어디서부터 시작해야 할까요?
Phase 1: 파일럿 팀 선정
- 암묵지가 가장 많이 작동하는 부서를 선정합니다 (회계, SCM, CS 등)
- 시니어 2~3명 대상으로 에이전틱 워크 환경을 구축합니다
- 핵심은 "자동화"가 아니라 "에이전트에게 일을 시키는 방식으로 업무 전환"입니다
Phase 2: 인풋 프롬프트 수집
- 시니어들의 에이전트 사용 패턴을 로깅합니다
- 반복적으로 등장하는 맥락, 조건, 판단 기준을 리스트업합니다
- 주 1회 Knowledge 매니저가 패턴을 리뷰합니다
Phase 3: 컨텍스트 그래프 초기 구축
- 수집된 암묵지를 화자/부서/상황/소스와 함께 구조화합니다
- 그래프 DB든 RDB든, 메타데이터 모델을 먼저 설계합니다
- 충돌 지식은 별도 플래그로 관리합니다
Phase 4: PR 프로세스 & 운영 루프 (지속)
- 새 암묵지 후보 감지 시 PR을 자동 생성합니다
- Knowledge 매니저의 주간 리뷰 & 승인 프로세스를 운영합니다
- 암묵지 기반 성과 지표를 도입합니다 (에이전트 활용 생산성 향상률)
Phase 5: 조직 확산
- 파일럿 성과를 기반으로 타 부서로 확산합니다
- 컨텍스트 그래프 간 크로스 레퍼런스를 구축합니다 (부서 간 연결)
- 신규 입사자 온보딩에 컨텍스트 그래프를 활용하면 학습 속도를 줄일 수 있습니다
7. 마무리 — 조직의 판단 체계를 자산으로
문서 전산화하고 사내 GPT 만드는 건 이미 많은 기업이 하고 있습니다. 그다음이 뭘까요. "우리 회사만의 암묵지, 판단과 맥락을 구조화해서 컨텍스트 그래프로 세팅하는 것"이 다음 단계가 될 수 있지 않을까 싶습니다.
시니어가 에이전트에게 암묵지를 전달하고 → 생산성이 올라가고 → 그게 성과로 인정되고 → 더 많은 암묵지가 공유되는 루프. 이게 돌아야 지속 가능하겠죠.
그리고 이 루프에서 쌓이는 지식을 화자·부서·직급·상황·소스와 함께 구조화한 것이 컨텍스트 그래프고요. 시니어가 만들고 주니어가 학습하는, 조직의 판단 체계 자체가 자산이 되는 구조입니다.
References
- 까칠한AI, "엔터프라이즈 AI 암묵지 설계와 수집, 그리고 충돌 현상 대응" (YouTube)
- California Management Review, "Tacit Knowledge Is Your Next Competitive Moat" (2026.03)
- Fortune, "Interloom raises $16.5M to solve AI agents' tacit knowledge problem" (2026.03)
- Enterprise Knowledge, "Top Knowledge Management Trends 2026" (2026.01)
- CIO Korea, "에이전틱 AI를 위한 컨텍스트 엔지니어링의 부상" (2025.11)
- LINE Engineering, "엔터프라이즈 LLM 서비스 구축기: 컨텍스트 엔지니어링" (2026.01)
- 유니콘팩토리, "피지컬AI 시대, 주목받는 암묵지" (2026.04)
- Gartner, "40% of Enterprise Apps Will Feature AI Agents by 2026" (2025.08)
- Deloitte, "The Agentic Reality Check" (2025.12)
- SECI Model image: Wikimedia Commons, CC BY-SA 3.0