Intro
현대의 Text-to-Image 생성 모델(예: Stable Diffusion, Flux 등)은 높은 수준의 퀄리티의 이미지를 생성해내지만, 정확하고 유연한 텍스트(특히 영어 이외의 언어) 렌더링에는 여전히 취약점을 보입니다. 예를 들어, “안녕하세요”나 “こんにちは” 같은 비(非)라틴 문자를 이미지에 담으라고 하면 글자 일부가 깨지거나 엉뚱하게 변형되는 문제가 흔합니다. 이러한 한계의 주요 원인은 텍스트 인코더(예: CLIP, T5)가 다국어 입력을 효과적으로 다루지 못하고, 학습 데이터에 포함된 다양한 문자 분포가 편중되어 있기 때문입니다. 다시 말해, 현존 모델들은 영어처럼 익숙한 문자에는 비교적 강하지만, 한글이나 아랍어같이 드문 문자에는 제대로 대응하지 못합니다.
이 문제를 해결하기 위해 두 갈래의 시도가 있었습니다. 첫 번째는 대체 인코더 도입으로, monolingual(특정 언어에 집중) 텍스트 인코더 대신 멀티링구얼 언어 모델(예: 다국어 T5나 대형 LLM)을 적용하여 모델을 처음부터 다시 학습시키는 것입니다.
실제로 Stable Diffusion 3.5나 FLUX 등 최신 공개 모델들은 CLIP 대신 T5 인코더를 쓰면서 영어 텍스트 표현력을 높였고, 중국의 Seedream 3.0이나 Kolors 2.0, GPT-4o 같은 폐쇄형 모델들은 아예 다국어 대응 인코더를 활용해 다양한 언어의 텍스트를 그려낼 수 있게 했습니다. 그러나 이러한 접근은 막대한 재학습 비용이 들고, 무엇보다 세밀한 제어(예: 글씨 위치 지정 등)가 어렵다는 한계가 있습니다.
두 번째는 보조 모듈 활용입니다. 기본 모델은 그대로 두고, 입력 텍스트나 원하는 글자 이미지를 처리하는 모듈(예: ControlNet 기반 보조망)을 추가해 컨트롤 가능한 텍스트 생성을 시도하는 방법입니다. 대표적으로 GlyphControl, AnyText 등이 글자 모양 정보를 추가로 넣어주는 기법인데, 문제는 이들 대부분이 UNet 기반의 구세대 모델(SD1.5나 SDXL 등) 위주로 개발되어 **최신 고화질 생성 모델(DiT 기반 SD3.5, FLUX 등)**에는 바로 적용하기 어렵다는 점입니다. 구형 모델을 쓸 경우 전반적인 이미지 품질이 낮아지기 때문에, 텍스트가 뚜렷해도 완성된 그림이 전반적으로 떨어지는 문제가 있었습니다.
요약하면 기존에는 텍스트 인코더를 강화하거나 별도 제어 모듈을 추가하는 방식으로 텍스트 렌더링 문제에 도전해 왔으나, 각각 비용과 품질 면에서 한계를 보여 왔습니다. 이러한 상황 속에서 25년 4월 Shakker Labs에서 이런 문제를 해결하기 위한 RepText 라는 새로운 아이디어를 제시하였습니다.
RepText
RepText는 “텍스트의 의미를 이해하지 못해도, 형태만 제대로 복제하면 된다”는 발상의 전환에서 출발합니다. 이는 마치 어린아이가 글자를 배울 때 철자를 몰라도 벼루와 붓으로 글씨 모양을 따라 쓰는 모습에 비유할 수 있습니다. 기존 모델처럼 문장을 이해해서 쓰려 하기보다는, 글자 모양(glyph) 그 자체를 흉내 내서 이미지 위에 얹는 식입니다. 이렇게 함으로써 굳이 모델이 각 언어를 이해하지 않아도 다양한 문자들의 시각적 형상을 렌더링할 수 있다는 것이죠.
구체적으로, RepText는 프롬프트의 텍스트를 직접 그 의미로 해석하지 않고, 해당 텍스트의 시각적 윤곽과 위치 정보를 조건으로 사용합니다. 이를 위해 ControlNet 구조를 채택하는데, 사용자가 “어떤 글자들을, 어떤 폰트로, 어디에 배치할지” 지정하면 그에 해당하는 글자 외곽선(edge)과 영역 마스크(mask)를 생성하여 기본 확산 모델에 입력합니다. 다시 말해, RepText는 글자 이미지를 제어 신호로 삼아 베이스 모델이 그 모양을 따라 그림을 생성하도록 유도합니다. 이러한 접근 덕분에 사용자는 원하는 텍스트 내용과 폰트, 위치 등을 자유롭게 지정할 수 있습니다. 모델 입장에서는 텍스트를 “이해”할 필요 없이 그저 주어진 스텐실(stencil)을 똑같이 그리기만 하면 되므로, 특히 비라틴 문자나 특수 폰트의 경우에도 정확도를 높일 수 있습니다.

또 하나의 착안점은, 텍스트 정확도를 높이려면 diffusion loss만으로는 부족하다는 것입니다. 사람이 보기엔 그럴듯해 보여도, 정작 OCR로 인식해 보면 철자가 틀리게 나오는 경우가 많은데요. RepText 연구진은 OCR 모델의 도움을 받아 이미지 속 텍스트 인식 정확도를 추가로 평가하고, 이를 학습에 반영하였습니다. 즉, 생성된 이미지 속 텍스트를 PP-OCRv3 같은 광학문자인식 모델로 판독하여 “정답 텍스트와 얼마나 유사한가”를 측정하는 perceptual OCR loss를 도입한 것입니다. 이 손실을 확산 모델의 손실과 함께 최적화하면, 모델이 사람이 읽을 수 있는 글자를 그리도록 유도할 수 있습니다 (OCR 결과가 나쁘면 페널티를 주는 방식). 이러한 텍스트 인식 기반 보상을 통해 글자 획 하나하나의 모양까지 더욱 정확히 그리게 됩니다.
다음으로, 생성 과정 안정화에 관한 아이디어입니다. 텍스트 생성이 특히 어려운 이유 중 하나는 확산 모델이 처음에는 랜덤 노이즈로부터 시작하기 때문입니다. 일반적인 이미지 생성에는 문제가 없지만, 글자의 경우 처음부터 무작위 노이즈에서 시작하면 나중에 형태가 흐트러지거나 엉뚱한 문양으로 변질되기 쉽습니다. RepText는 이를 해결하기 위해 초기 노이즈를 똑똑하게 설계하는 방식을 취했습니다. 간단히 말하면, 확산 프로세스의 초기 상태(latent)에 완전 랜덤 노이즈를 넣는 대신 “희미한 글자 그림자”를 깔아주는 것입니다. 모델이 처음부터 글자 모양의 윤곽을 참고하면서 생성하도록 하여, 글자가 스파게티처럼 흐트러지지 않고 형태를 유지하도록 하는 것이죠. 논문에서는 이를 Glyph Latent Replication이라 부르며, 노이즈-프리(noise-free) 글리프 잠재 텐서를 초기 상태로 복제하여 활용한다고 설명합니다. 실제 구현 시 완전한 복제 대신 글자 latent와 가우시안 노이즈를 섞은 혼합 초기 텐서를 사용하며, 글자가 들어갈 부분에만 이 기법을 적용합니다. 연구 결과 이러한 간단한 조치만으로 타이포그래피 정확도가 크게 향상되었고, 추가로 글자 색상 제어까지 자연스럽게 가능해졌다고 보고합니다.
마지막으로, 영역별 제어에 대한 기법입니다. 일반적인 ControlNet은 입력 조건(edge, depth 등)을 이미지 전역에 걸쳐 적용하지만, 텍스트의 경우 국소적인 위치에만 적용되는 정보입니다. 잘못하면 글자 정보가 배경에도 영향을 미쳐서 전체 이미지 품질을 해칠 수 있습니다. RepText는 이를 방지하고자 텍스트 영역에만 ControlNet 출력을 주입하는 Region Masking 기법을 사용했습니다. 텍스트의 바운딩 박스 영역을 이진 마스크로 만들어 해당 부분에만 ControlNet 피처를 활성화하고, 그 외 영역에서는 제어 신호를 차단합니다. 이를 통해 글자가 아닌 배경이나 인물 등 다른 요소들은 영향을 받지 않고, 글자 부분만 정확히 제어되도록 하였습니다. 연구진은 이 부분 마스킹이 배경 왜곡을 막아 전반적인 화질을 높이는 효과가 있다고 보고합니다.
정리하면, RepText의 핵심 기여는 다음과 같습니다:
- monolingual 기반 모델의 다국어 텍스트 렌더링 능력을 향상시키는 효율적 프레임워크 제안 (전면 재학습 없이 추가 모듈로 구현).
- Glyph Latent Replication(초기 latent에 글자형 복제) 도입으로 글자 형태 정확도 향상 및 색상 제어 지원, 그리고 Region Masking 적용으로 배경 품질 저하 없이 텍스트 삽입 성공.
Model Implementation
FLUX 기반 모델과 ControlNet 설정
RepText는 기본 생성 모델(base model)로 FLUX.1-dev를 사용합니다. FLUX.1-dev는 2560×2560 해상도까지 지원하는 거대한 T5-XXL 인코더 기반 모델로, 영어권 텍스트에 대해서는 이미 우수한 묘사와 어느 정도의 텍스트 작성 능력을 보유하고 있습니다. RepText는 이 FLUX 모델 위에 텍스트 전용 ControlNet 분기(branch)를 추가하는 형태로 구현되었습니다. ControlNet 분기는 ControlNet-Union-Pro-2.0 구조를 참고하여 6개의 더블 블록으로 이루어져 있으며, 초기 가중치는 FLUX의 일부를 그대로 활용해 학습 안정성을 높였습니다.
다시 말해, FLUX 모델 + 텍스트 ControlNet이 합쳐진 Diffusers 파이프라인 형태로 동작합니다. ControlNet은 두 가지 조건을 입력받도록 구성되는데, 하나는 텍스트의 윤곽(edge) 이미지, 다른 하나는 텍스트 위치를 나타내는 마스크 이미지입니다. Edge 정보는 OpenCV의 Canny 등을 이용해 글자 그림의 외곽선을 추출한 것이고, 위치 마스크는 글자 바운딩 박스 영역을 흰색으로 표시한 이진 이미지입니다. 이러한 glyph+position 조건이 주어지면, ControlNet은 해당 위치에 해당 모양을 생성하도록 중간 확산 과정에 영향을 미치게 됩니다.
학습 데이터와 전략
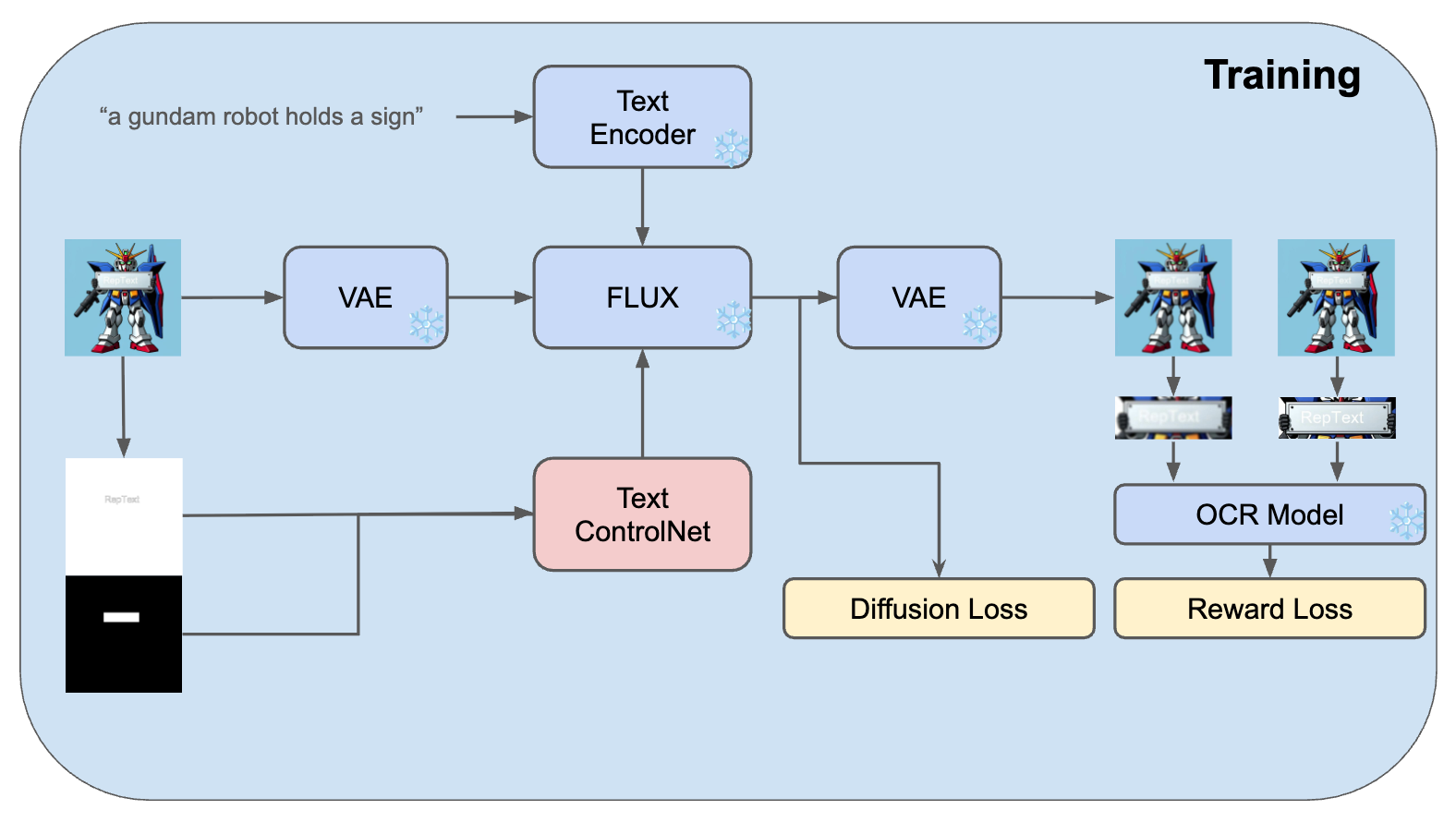
학습 단계에서는 합성 데이터와 실제 이미지 데이터를 순차적으로 활용했습니다. 먼저, 공개된 AnyText-3M 데이터셋(다국어 텍스트 이미지 약 300만 장)으로 사전 학습(pre-training)을 수행했습니다. 해상도 512×512의 합성 이미지에 대해 학습하면서, 기본 확산 손실과 앞서 언급한 OCR 인식 손실을 함께 최적화했습니다. 이때 AdamW Optimizer(learning rate 2e-5)와 대규모 배치(256)를 사용하여 안정적으로 학습시켰으며, OCR loss 가중치는 초기에는 0.05로 작게 두어 모델이 우선 그림을 그리는 법을 배우도록 했습니다. 또한 Text Drop이라는 기법을 도입했는데, 이는 일부 비율(30% 정도)로 텍스트 조건을 무시한 채 학습하여 모델이 텍스트 없이도 배경을 자연스럽게 생성하도록 도와주는 regularization 기법입니다.
1차 학습을 마친 후, 실제 사진 이미지 1만 장으로 파인튜닝(fine-tuning)을 진행했습니다. 여기에는 도로 표지판, 간판, 현수막 등 현실 세계의 텍스트가 포함된 이미지들이 사용되었으며, 합성 이미지로 학습한 모델을 실제 도메인에 적응시키는 단계입니다. 파인튜닝 시에는 다양한 ratio 이미지를 학습하기 위해 bucketing 기법을 적용하고, 학습률을 5e-6로 낮춰 미세 조정했습니다. 이 단계에서는 OCR loss의 비중을 0.1로 높이고, Text Drop 비율도 40%로 약간 올려서텍스트 인식 정확도를 최대한 끌어올리는 동시에 과도한 오버피팅을 방지했습니다. 이러한 2단계 학습 전략(합성 데이터 pre-train → 실제 데이터 fine-tune)을 통해 모델은 글자 렌더링 능력과 현실감을 갖추게 되었습니다.
추론 단계와 활용
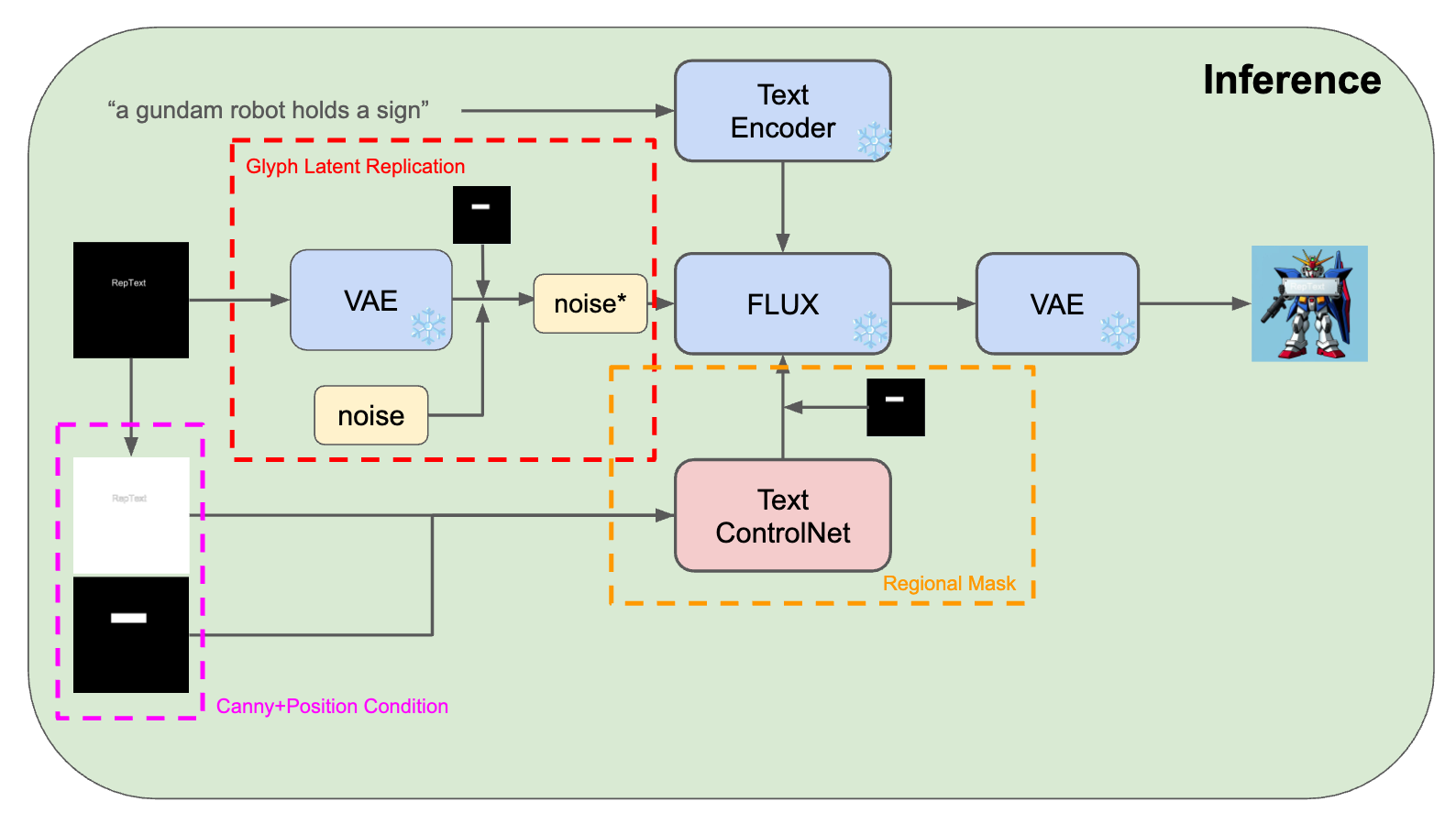
추론(inference) 시에는 사용자가 원하는 텍스트와 속성을 입력하면, 그에 맞는 제어 이미지들을 만들어 파이프라인에 넣어주는 절차가 필요합니다. 예를 들어 “Hello”를 빨간색 Arial 폰트로 이미지 중앙에 넣고 싶다면, 우선 1024×1024 빈 캔버스에 해당 텍스트를 그려 얻은 글자 그림(glyph image)을 준비합니다. 이 글자 그림에 대해 Canny 엣지 검출을 수행하여 윤곽선 이미지를 얻고, 동시에 글자의 bounding box 영역만 흰색으로 채운 마스크 이미지도 생성합니다. 이렇게 준비된 edge 이미지 (리스트 형태로 전달)와 position 마스크를 ControlNet의 입력 조건으로 제공합니다. 또한 영역 마스크도 별도로 만들어 두는데, 이는 bounding box보다 약간 확장된 크기로 설정하여 글자가 들어갈 영역을 지정하는 마스크입니다. 이 마스크는 ControlNet 출력 피처를 해당 영역에만 적용하는데 사용됩니다.
ControlNet 외에 노이즈 초기화 단계에서도 앞서 언급한 glyph latent replication이 적용됩니다. 구체적으로, 방금 만든 글자 그림(glyph 이미지)을 VAE 인코더를 통해 latent 공간으로 임베딩한 후, 거기에 약간의 가우시안 노이즈를 섞어 초기latent로 삼습니다. 이렇게 하면 확산 과정의 첫 단계부터 이미지에 희미하게나마 글자 형태가 자리잡고 있게 되어, 모델이 보다 수월하게 글자를 만들어낼 수 있습니다. 이 초기 glyph latent를 사용할 지 여부나 그 가중치는 옵션으로 조절 가능하며, RepText 논문에서는 랜덤 노이즈 대 글자 latent의 비율을 약 9:1 (α=0.9, β=0.1)로 주는 것이 최적임을 밝혔다고 합니다. 참고로 이러한 방법 대신 역방향 확산(inversion)으로 원하는 텍스트 이미지의 latent를 얻어 초기화하는 것도 실험했지만, 간단한 복제 방식과 큰 차이는 없었다고 합니다.
마지막으로 확산 모델에 텍스트 생성을 암시하는 프롬프트를 함께 넣어주면 추론 준비가 완료됩니다. 영어권 단어나 간단한 문장은 프롬프트에 직접 넣어주면 모델이 장면을 꾸미는 데 참고가 되므로, 예를 들어 “간판에 HELLO 라고 쓰인 거리 사진”처럼 맥락을 함께 주는 것이 권장됩니다. 반면 한글처럼 기본 모델이 전혀 모르는 언어의 경우 프롬프트에 넣어도 효과가 거의 없으므로, 이때는 그냥 “a billboard” 정도의 배경 묘사만 주고 글자 내용은 ControlNet 신호로만 주는 식입니다. 이제 파이프라인을 실행하면 RepText 모델은 지정된 위치에 원하는 모양의 글자를 그리되, 주어진 프롬프트 맥락에 어울리는 화풍과 조명을 가진 완성도 높은 이미지를 출력합니다. 이 전체 추론 과정은 깃허브에 공개된 파이프라인 코드로 구현되어 있으며, PyTorch + Diffusers 환경에서 쉽게 활용할 수 있습니다.
Experiments
RepText 논문의 실험 결과, 제안된 방법이 텍스트 정확도와 렌더링 품질 면에서 뛰어난 향상을 보였습니다. 저자들은 다양한 비교 대상 모델에 대해 정량/정성 평가를 수행했는데, 오픈소스 모델로는 Stable Diffusion 3.5, FLUX-dev, HiDream 등과, 그리고 텍스트 렌더링 특화 기법인 TextDiffuser, GlyphControl 등을 포함했습니다. 클로즈드소스 모델로는 Ideogram 3.0, Recraft V3, GPT-4o, Seedream 3.0, Kolors 2.0 등 최신 멀티랭귀지 이미지 생성 모델들을 대상으로 삼았습니다.
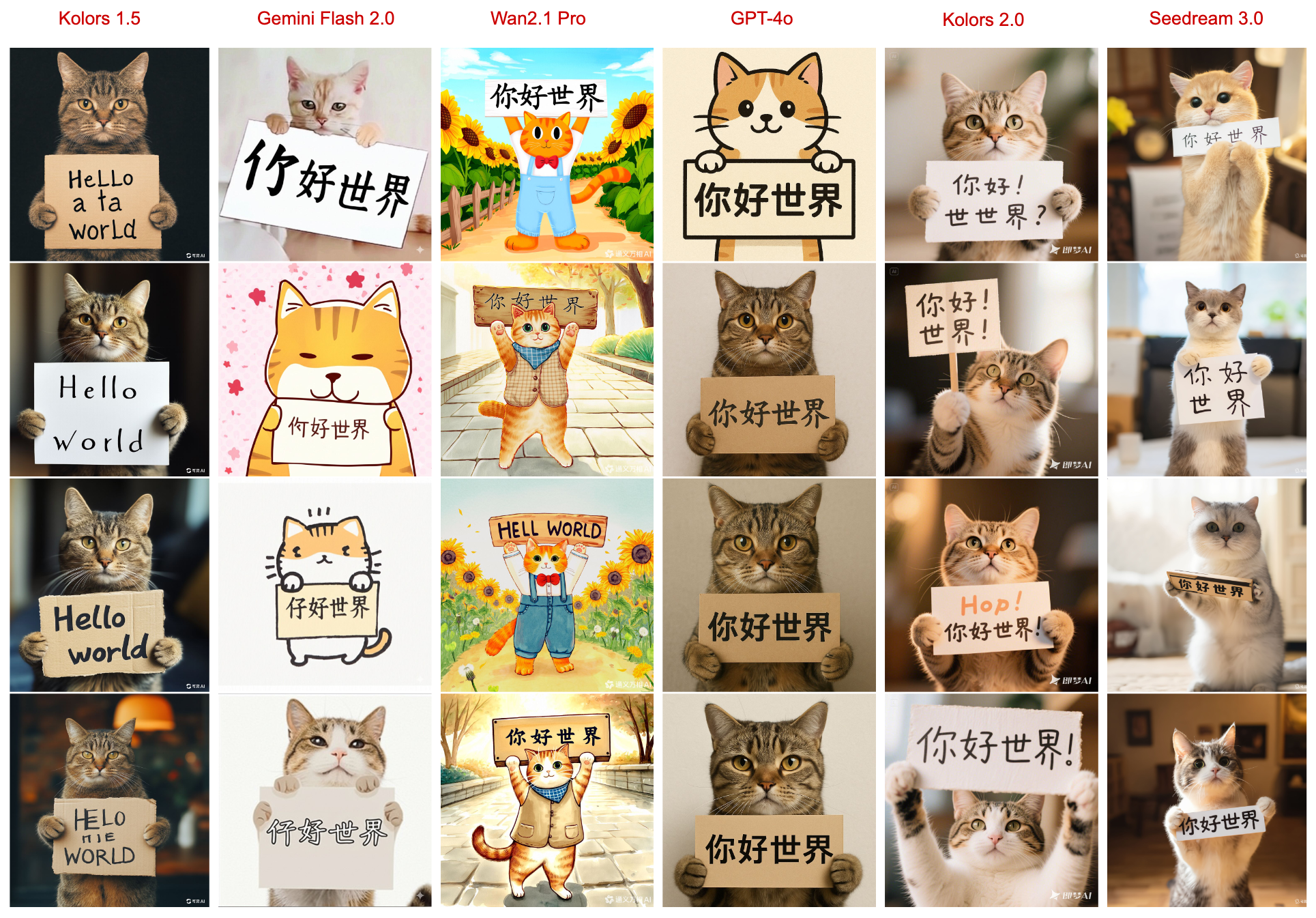

그 결과 RepText는 기존 오픈소스 방법들보다 텍스트의 정확성과 이미지 품질 면에서 확연한 우위를 보였고, 멀티링구얼 지원을 갖춘 폐쇄형 모델들과도 대등한 수준의 텍스트 재현 성능을 달성했습니다. 예를 들어, 한국어 간판이나 아랍어 표지판 같은 사례에서 Stable Diffusion이나 AnyText 등이 글자를 틀리게 쓰거나 일부 글자가 깨진 반면, RepText는 모든 글자가 정확하고 선명하게 표현되었습니다. 심지어 글자 획의 두께나 꼬리 같은 폰트 스타일 요소도 원본 폰트를 잘 복제하여 시각적으로 가장 유사한 결과를 냈습니다. 종합적인 품질 면에서도 FLUX 기반이라 배경제품의 사실감이 높고 해상도가 우수하다는 평가를 받았습니다.
한편, 완성된 이미지를 OCR로 다시 읽어서 텍스트 인식 성공률을 측정한 결과도 제시되었는데, RepText는 다국어 대부분에서 인식 성공률이 크게 향상되었습니다. 예를 들어 중국어 간판 생성 시 기존 AnyText 대비 OCR 정확도가 10%p 이상 개선되었고, 한글의 경우 GlyphControl로 50%대에 그쳤던 정확도가 RepText에서는 80% 이상으로 뛰어났다고 합니다 (논문 부록 참조). 다만 영어 문장의 경우에는 기본 모델 자체가 우수하다보니, RepText를 쓰더라도 프롬프트에 영어 단어를 추가해주는 정도의 간접 제어와 큰 차이는 없었다고 합니다. 즉 영어권에서는 이미 base 모델만으로도 웬만한 단어나 문구는 그려낼 수 있기 때문에, RepText는 주로 비영어권 언어나 특정 폰트 지정 등에 더 유용하다고 볼 수 있습니다.
흥미로운 점은, RepText가 폐쇄형 상용 모델들과 비교해서도 경쟁력을 보였다는 것입니다. Ideogram이나 GPT-4o 같은 모델들은 멀티링구얼 거대 인코더 덕분에 텍스트 이해도는 높지만, 사용자가 원하는 정확한 위치나 특정 폰트 반영은 어려운 편입니다. 반면 RepText는 정밀 제어가 가능하므로, 글씨 배치를 정확히 지정하거나 특수한 폰트 스타일을 반영하는 시나리오에서 월등한 유연성을 보여주었습니다. 저자들은 “다만 GPT-4o, Kolors 2.0 등 최첨단 모델들은 워낙 내부적으로 텍스트 이해능력이 좋아서, 자유로운 문장 생성 면에서는 우리가 따라가기 어렵다”는 점도 인정하고 있습니다. 즉 이해를 통한 생성 vs 복제를 통한 생성의 트레이드오프가 있는데, RepText는 후자 방식을 극한까지 활용함으로써 이해 능력 없이도 실용적인 텍스트 렌더링을 달성했다는 의의를 갖습니다.
Applications and Extensions
RepText의 가장 큰 장점 중 하나는, 기존 모델의 생태계와 호환되면서 텍스트 렌더링 능력을 추가로 부여한다는 점입니다. 베이스로 FLUX 모델이 사용되기 때문에 LoRA, ControlNet, IP-Adapter 등을 그대로 함께 활용할 수 있습니다. 연구에서는 이를 직접 검증하기 위해 세 가지 스타일 LoRA를 결합해 보았는데, 필름 카메라 풍의 질감을 입히는 FilmPortrait LoRA, 털실로 짠 그림처럼 만드는 Yarn-World LoRA, 어린이 스케치 느낌을 주는 Sketch LoRA를 RepText와 함께 적용한 결과 텍스트가 들어간 이미지도 문제없이 원하는 스타일로 변환됨을 확인했습니다.

아래쪽 그림자가 드리워진 입체 텍스트나 만화풍 말풍선 텍스트 등도, 해당 스타일에 맞는 LoRA를 끼우면 쉽게 생성할 수 있었습니다. 이는 RepText의 ControlNet 분기가 다른 플러그인들과 독립적으로 동작하기 때문에 가능한 일로, 텍스트 제어 부분만 추가되었을 뿐 기본 모델의 표현력은 그대로 유지되기 때문입니다.
게다가 RepText는 본질적으로 언어 비의존적인 방식이므로, 입력으로 제공할 glyph 이미지만 만들 수 있다면 사실상 어떤 문자 체계라도 렌더링 가능합니다. 한글, 한자, 아랍어부터 힌디어, 그리스 문자, 기호(font glyph) 등까지 모두 동일한 방법으로 처리되며, 실험 결과 폰트만 변경하면 다양한 서체도 적용할 수 있었습니다. 또한 여러 줄의 텍스트도 각 줄별로 ControlNet 조건을 쌓아서 제어하면 자연스럽게 한 이미지에 복수의 문장을 넣을 수 있습니다. 논문 부록에서는 영어 문장과 중국어 문장을 한 이미지에 동시에 배치한 결과나, 서로 다른 색상의 여러 단어를 한데 배치한 결과 등도 제시되었습니다.

또 다른 응용으로, RepText의 부분 제어 특성을 이용해 이미지 내 텍스트 편집도 고려할 수 있습니다. ControlNet-Inpainting 모듈과 결합하면 이미지의 특정 영역(예: 간판)에 적힌 글자를 다른 내용으로 바꾸는 작업도 수월해집니다. 실제 논문에서는 IP-Adapter와 조합하여 기존 이미지의 스타일은 유지하면서 텍스트만 교체하는 실험을 진행했고, 꽤 그럴듯한 결과를 얻었다고 합니다. 요약하면 RepText는 텍스트를 필요로 하는 모든 이미지 생성/편집 작업을 보다 정확하고 유연하게 만들어 줄 수 있는 도구로서, 충분한 잠재력을 보여주었습니다.
Limitations and Future Works
물론 RepText에도 몇 가지 한계점이 존재하며, 논문에서는 이를 투명하게 논의하고 향후 발전 방향을 제시하고 있습니다. 대표적인 제한사항은 다음과 같습니다.

-
장면 부조화: 모델이 텍스트 의미를 전혀 이해하지 못하기 때문에, 가끔 생성된 글자가 주변 이미지와 부조화를 이루는 경우가 있습니다. 예를 들어 정글 배경에 “Hello”라고 넣으면, 글자가 배경과 어울리지 않고 워터마크처럼 둥둥 뜬 느낌이 날 때가 있습니다. 이는 특히 비라틴 문자에 대해 프롬프트 힌트도 없을 때 자주 발생하며, 글자가 자연스러운 일부라기보다 합성한 스티커처럼 보이는 문제가 있습니다.
-
작은 글자의 품질 저하: 글자 크기가 너무 작거나, **획이 복잡한 문자(예: 한자나 티베트 문자)**의 경우 여전히 렌더링 정확도가 떨어집니다. 이는 ControlNet에 주는 조건 이미지의 해상도 한계와 VAE의 압축 손실 때문으로 추정되는데, 그 결과 작은 폰트는 뭉개지거나 일부 획이 붙어버리는 현상이 나타납니다.
-
불필요한 텍스트 발생: 간혹 생성된 이미지의 다른 부분에 의미없는 글자나 파편이 나타나는 경우가 있습니다. 예를 들어 간판 글씨를 넣었는데, 주변 벽이나 바닥에 알아볼 수 없는 낙서같은 문자가 추가로 생겨나는 식입니다. 이는 비록 영역 마스킹을 적용했어도 확산 모델 특성상 텍스트 질감을 응용하여 주변에 추가적인 패턴을 만들어내는 것으로 보입니다.
-
텍스트 속성 다양성 제한: 현재 RepText는 글자 내용, 폰트, 위치 등은 제어할 수 있으나, 이것이 프롬프트 제어와는 별개로 이루어집니다. 즉 “금색 질감의 글씨”처럼 텍스트의 재질이나 효과를 직접 프롬프트로 지시하기는 어렵습니다. 그런 효과를 내려면 별도의 LoRA나 ControlNet (예: Depth로 양각 효과) 등을 추가로 써야 합니다. 현 버전은 텍스트를 평면적이고 단색으로 복제하는 데 최적화되어 있어 재질 변화나 3D 효과 등은 지원하지 않습니다.
-
정밀한 색상 제어의 어려움: 앞서 글자 색을 지정할 수 있다고는 했지만, 아주 세밀한 색 표현은 힘듭니다. 예를 들어 글자 내부에 복잡한 색 그라데이션을 넣거나, 정확한 CMYK 값에 맞추는 등은 불가능합니다. 논문에서도 현재 방식은 거친 색상만 복제할 뿐, 미세한 색조차이까지는 표현하지 못한다고 인정합니다. 향후에는 색상까지 세밀하게 제어할 수 있는 메커니즘 (예: 추가적인 color embedding 등)이 고려될 수 있습니다.
-
왜곡/원근 효과의 부재: RepText로 생성한 글자는 항상 정면(view) 기준의 평평한 텍스트입니다. 그러므로 회전되거나 원근이 적용된 표지판 글씨, 물체 표면을 따라 굽어지는 텍스트 등은 직접적으로 생성하기 어렵습니다. 현재는 글자 그림 자체를 그렇게 왜곡해서 ControlNet에 넣어도 모델이 따라 그리지는 못하며, 이는 전처리 글리프의 한계입니다. 향후엔 3D 변형이나 곡면 위 텍스트 표현을 위해 역변환(unprojection) 기법이나 3D-aware 모델과의 결합 등이 필요해 보입니다.
정리하면, RepText는 현재 평면상의 명시적 텍스트 복제에 최적화된 솔루션으로서 훌륭한 성능을 보이지만, 텍스트 의미의 부재로 인한 제한과 렌더링 다양성 부족이라는 과제가 남아 있습니다. 이러한 부분은 궁극적으로 모델이 텍스트를 이해하도록 만드는 방향으로 발전시킬 여지가 있습니다. 저자들 또한 “가장 이상적인 건 결국 모델이 각 단어의 의미를 이해해서 장면과 어울리게 표현하는 것”이라며, 다만 그 방법으로 완전 초기화 재학습이 아닌 경량 추가 학습(예: 멀티모달 LLM과 확산모델을 연결하는 MetaQuery 등의 접근)을 향후 연구 과제로 제시했습니다.
Conclusion
RepText는 텍스트의 의미를 학습하는것이 아닌 복제컨셉으로 다중 언어 텍스트에 대한 문제를 풀어냈습니다. 대규모 언어 모델을 쓰지 않고도 다국어 텍스트를 그려낼 수 있다는 점에 대해서는 의의가 크지만 퀄리티면에서 아직 부족해 보입니다.
저 또한 이미지 생성 관련 글로벌 서비스를 운영하면서 아직 텍스트 생성을 영어로만 제한하고 있어 글로벌 서비스를 운영하는데 큰 제약이 되고 있습니다. 아직 완벽하지는 않지만, RepText가 오픈소스로 공개되었기 때문에 앞으로 다양한 후속 연구와 응용을 기대합니다.
Keep going
Project Page:https://reptext.github.io/
Paper: https://arxiv.org/abs/2504.19724
GitHub: https://github.com/Shakker-Labs/RepText