Intro
최근 이미지 생성분야에서 가장 핫한 모델은 역시 Black forest에서 공개한 FLUX.1 Kontext 입니다. 특히 Kontext Dev 모델이 드디어 Open Weight로 풀리면서 reddit 등의 커뮤니티에 다양한 워크플로우와 Kontext LoRA가 공유되고 있습니다.
Flux Kontext는 이미지와 텍스트 지시문을 함께 이해하여 이미지 수정 및 생성을 빠르고 일관성 있게 수행하는 AI 모델입니다. 기존 모델과 달리 기존 이미지의 스타일과 구조를 유지하면서 사용자의 자연어 명령에 맞춰 이미지를 변형할 수 있습니다.
Kontext Example

Original

Result
-
핵심 원리
- 텍스트(예: "이미지에서 남자를 제거해줘.")와 이미지를 동시에 입력하면, 두 정보를 토큰 시퀀스로 합쳐 하나의 컨텍스트로 만듭니다.
- 플로우 매칭(flow matching) 기법을 기반으로, 이미지의 '잠재공간(latent space)' 레벨에서 연속적으로 변화 방향(velocity)을 예측해 노이즈 상태의 이미지를 지시문에 맞는 새 이미지로 변환합니다. 이 방식은 많은 디퓨전 모델보다 빠르고 효율적입니다.
- 이미지는 오토인코더로 압축된 latent 형태로 다루며, 여기서 수정이 이루어져 결과적으로 글로벌 구조와 디테일이 잘 보존됩니다.
- 모델 내부에서 어텐션 메커니즘과 정규화(norm), 그리고 이미지·텍스트 별 모듈레이션 기법이 적용되어 지시문과 이미지 특성 모두를 정밀하게 반영합니다.
-
주요 특징
- 새로운 이미지를 생성할 때뿐 아니라, 기존 이미지를 보존하며 부분 수정(예: 캐릭터 일관성 유지, 스타일 유지)이 매우 강력합니다.
- 빠른 속도로 실시간 편집이 가능하며, 이미지 설명 방식의 프롬프팅이 아니라 자연어 방식의 프롬프트로 이미지 편집이 가능합니다.
Flux Kontext를 사용하기 위한 방법은 두가지가 있습니다.
- API: Replicate, together.ai, fal.ai 같은 플랫폼에서 Kontext Max, Pro, Dev 모델을 API로 사용. (charge per request)
- Local: Kontext Dev 모델을 로컬 GPU를 사용해서 Diffuers, ComfyUI에서 사용.
하지만 API는 Kontext 추론 이외의 커스텀 워크플로우가 존재하는 경우 별도로 통합할 시스템을 구축해야 하며 kontext pro 기준 요청당 4센트(25번 요청에 1달러)의 비용이 발생합니다.
테스트를 위해 사용하기에는 부담스러운 금액이고 로컬에서 사용하자니 이미 GPU를 다른곳에서 사용하고 있거나 보유하고 있지 않은 상황이라면 로컬에서 사용하기에도 어렵습니다.
그래서 이번 포스팅에서는 저렴한 가격에 Kontext Dev를 Runpod Serverless로 배포해서 기존 API보다 훨씬 저렴하면서 nunchaku라는 기술을 적용해 base kontext dev model 보다 2배 단축시키는 방식을 소개하려고 합니다. (Custom Workflow 적용 가능)
Diffusers with nunchaku
Flux Kontext Dev 모델은 Diffusers 라이브러리를 사용해서 쉽게 실행할 수 있습니다.
위와같은 방식을 사용했을때 RTX 4090 기준으로 denoise 28step에 대해 약 30초 정도의 시간이 소요됩니다. 하지만 Flux Pro API는 평균적으로 5~7초 정도의 속도를 생각해보면 많이 아쉬운 것이 사실입니다.
하지만 nunchaku를 적용한다면 이 속도를 2배정도 더 빠르게 만들 수 있습니다.
Nunchaku는 SVDQuant 논문에서 소개된, 4비트 신경망에 최적화된 고성능 추론 엔진입니다. 논문에 대해서는 지난 포스트에 정리해 두었으니 동작 방식이 궁금하시다면 읽어 보시는 것을 추천 드립니다.
nunchaku 설치 방법: https://nunchaku.tech/docs/nunchaku/installation/installation.html
nunchaku를 설치했다면 아래 diffusers 코드를 테스트를 진행해 볼 수 있습니다.
nunchaku-tech 에서 이미 4비트 양자화가 적용된 모델을 huggingface에 올려두었기 때문에 위 코드 실행으로 바로 모델을 다운받고 추론을 할 수 있습니다. 코드 실행 결과 15초의 추론시간이 측정되었고 이 속도는 정확히 기본 모델을 사용했을 때보다 2배 더 빠른 속도입니다.
Runpod Serverless
자, 이제 모델을 로컬이 아닌 API 형태로 저렴하게 배포하기 위해서 어떻게 해야할까요? 저는 이런 상황에서 Runpod의 Serverless 기능을 활용하고 있습니다.
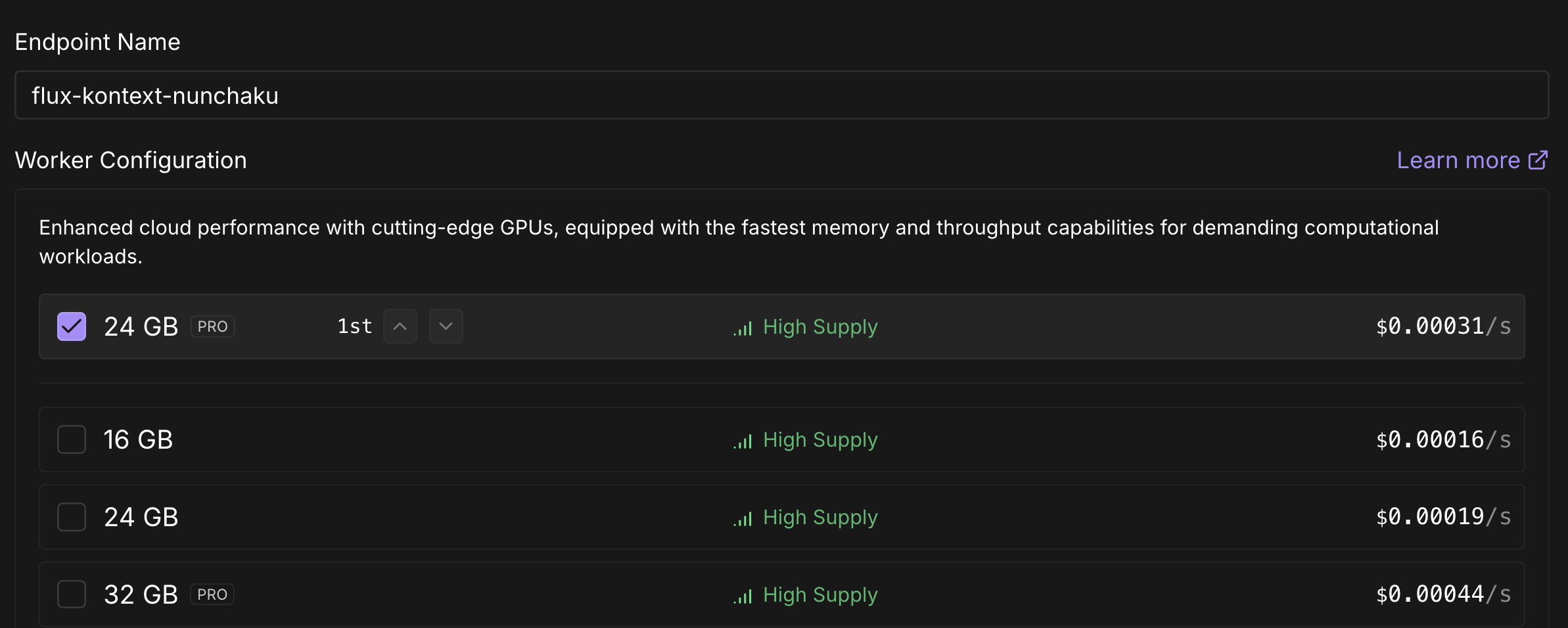
Runpod Serverless의 장점은 다양한 GPU를 보유하고 있어 사용하고자 하는 모델에 맞는 최적의 GPU 선택할 수 있으며 github repo로 부터 Runpod의 자체 리소스를 통해 CI/CD가 관리되기 때문에 별도의 리소스 없이 쉽게 배포가 가능하다는 점 입니다.
Runpod Serverless에 배포하기 위해서는 먼저 handler가 구현된 코드가 필요합니다.
main.py 코드 예시:
코드의 로직은 diffusers와 동일합니다. 다만 입력 이미지가 http 혹은 base64 두개를 받을 수 있도록 처리했고 5step마다 latent를 클라이언트에게 전달해서 UX를 개선하기 위해 on_step_end_callback 콜백함수를 구현했습니다.
💡 Tip
diffusion 기반 이미지 생성에서 latent 이미지는 그 자체로는 사람의 눈으로 이미지로 보이지 않기 때문에 vae decode를 수행해야 합니다. 하지만 추론 중간과정에서도 vae decode를 지속적으로 사용하게 되면 리소스 낭비 및 지연시간이 발생하기 때문에 이 방법을 latent preview에 사용하기에 적합하지 않습니다.
그래서 이미지 생성 과정(step 중간)에서 완전히 디코딩(Decode)하는 대신 latent space 값(보통 4채널, 1/8 크기)을 RGB로 근사 변환해 빠른 preview가 가능하도록 linear latent-to-RGB projection 기법을 구현했습니다.
handler 함수를 구현했다면 이제 이미지 빌드를 위해 Dockerfile을 준비해야 합니다.
Runpod Serverless를 사용할때 문제가 되는 부분은 바로 모델 파일을 어디에 저장하고 있는냐 입니다.
- 모델 파일을 Docker 이미지 내부에 포함시켜 로컬파일로서 모델 로드
- Network Storage에 모델 파일을 저장해두고 Network Volume Mount 방식으로 모델 로드
1번 방법은 로컬에 있는 모델을 로드하기 때문에 Network로 인한 로딩 지연시간을 최소화 할 수 있습니다. 다만 이미지 빌드 시간이 오래걸리며 huggingface token과 같은 암호화가 필요한 변수를 Dockerfile에 노출해야합니다.(아직까지 Runpod에서 컨테이너 빌드차원의 secret 변수는 지원되지 않음)
2번 방법은 미리 Runpod Network Volume에 모델을 저장해두고 워커(컨테이너)에서 이곳의 모델을 로드해서 사용하는 방식입니다. 그렇기 때문에 빌드 시간단축 및 보안측면의 문제는 해결되지만 네트워크 volume으로부터 모델을 로딩하는 과정에서 cold starts 현상이 발생할 수 있습니다. 또한 엔드포인트를 Network Storage의 region과 동일한 region을 사용해야 하기 때문에 원하는 GPU리소스가 해당 리전에 충분한 여유가 없다면 곤란한 상황에 빠질 수 있습니다.
현재 저희는 오픈 모델을 사용하기 때문에 1번 방식을 위해 Dockerfile을 작성했습니다. 주석 4번을 보시면 nunchaku 방식의 kontext를 실행하기 위해 필요한 모델을 다운로드 하는 코드를 볼 수 있습니다.
💡 Tip
huggingface-cli 에서는 --exclude 이라는 파라미터를 제공합니다. 이 파라미터를 활용하면 원하지 않는 폴더 및 파일을 제외하고 다운로드를 받을 수 있어서 불필요한 리소스 낭비를 줄일 수 있습니다.
이제 해당 프로젝트를 github repo에 push한 뒤에 runpod serverless 에서 new endpoint 버튼을 누르면 github repo의 Dockerfile을 활용해 Runpod 자체적으로 이미지를 빌드하고 배포를 할 수 있습니다.
API Test on Gradio
생성한 엔드포인트에서 Build 탭의 상태가 completed가 된후 Workers 탭에서 idle 상태가 되었다면 이제 api요청을 보낼 수 있습니다.
저는 간단하게 Gradio를 사용해서 파이썬 웹 애플리케이션을 만들어 보았습니다. 일반적인 API처럼 이미지를 업로드하고 prompt, 비율설정을 하고 generate 버튼을 누르면 이미지가 생성됩니다.
여기에 별도로 runpod / local radio 버튼을 통해 api 및 로컬 추론을 선택할 수 있도록 했습니다.
공식 문서에서 endpoint로 실행 요청 과 status 확인 등을 python sdk 사용하는 방법에 대해 자세히 나와있으니 여기서 코드는 생략하겠습니다.
Conclusion
지금까지 flux kontext를 nunchaku를 사용해서 추론하는 방법과 runpod serverless를 사용해서 배포하는 방법에 대해 알아보았습니다.
nunchaku-tech에서는 지속적으로 새로운 모델에 대한 경량화를 진행하고 있습니다. (FLUX.1-Krea-dev 가 7월 31일에 추가됨) 이미지 생성모델을 배포를 해야 한다면 이런 경량화 기법을 적극적으로 테스트해서 적용한다면 리소스를 줄이고 UX를 개선할 수 있을 것 입니다.
Keep Going