You Only Look Once: Unified, Real-Time Object Detection (2016)
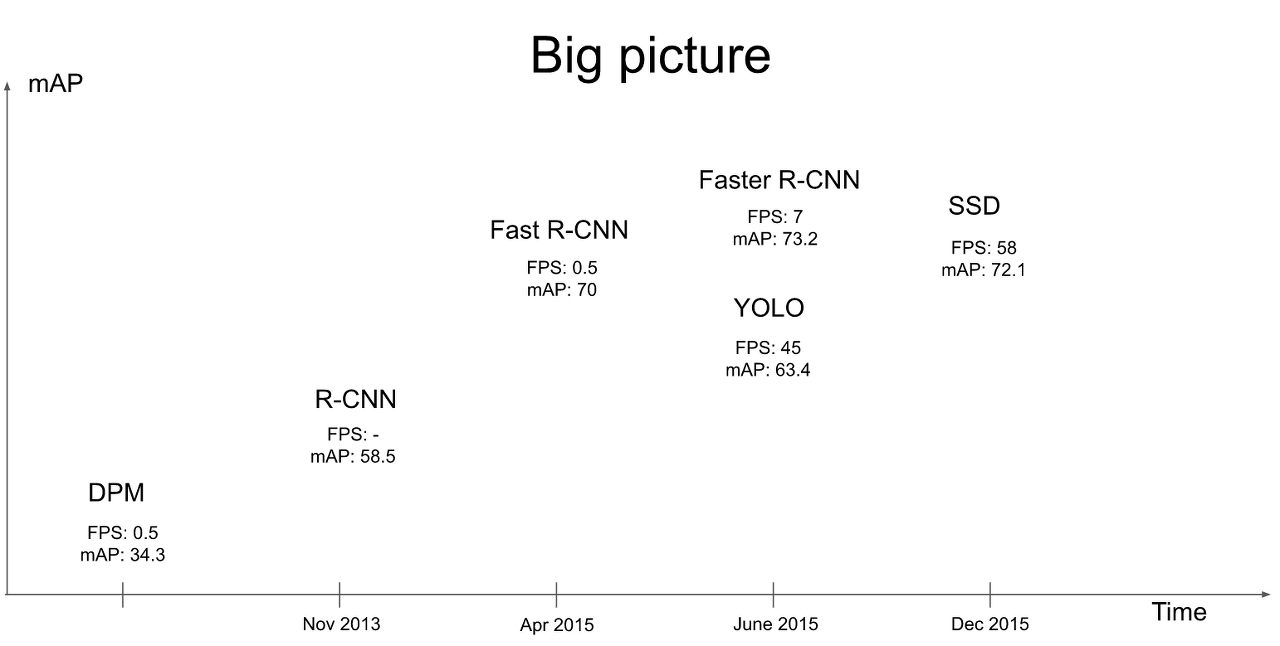
1. Introduction
기존의 R-CNN 계열의 detection 모델들은 localization과 classification 파트가 분리 되있는 2-stage-detector였지만 YOLO는 bounding box 예측과 classificaion을 동시에 수행하는 1-stage-detector를 제시하였다.
YOLO의 장점은 다음과 같다.
- Object detection을 regression 문제로 변환해 단순화 하여 실시간으로 detection이 가능해졌다. (엄청나게 빠른 속도)
- 기존 detection 방식은 예측된 bounding box 내부만을 이용해서 클래스를 예측하는데 YOLO는 전체 이미지를 통해 bounding box의 class를 예측한다.
- 학습한 이미지에 대한 예측 뿐 아니라 다른 도메인의 이미지에도 어느정도 괜찮은 성능을 보였다.
하지만 당시 새로 나온 구조라서 그런지 YOLO v1은 단점도 적지않은데 단점은 아래에서 나올 것이다.
2. Unified Detection
위에서 언급한 것 처럼 YOLO v1에서는 end-to-end 방식으로 하나의 convolution network를 거쳐서 마지막 feature_map에서 bounding box와 class를 예측한다.
모델의 최종 feature map은 7 x 7 x 30의 사이즈를 가지고 있게 되고 이것을 49개의 영역의 grid cell로 보고 각 grid cell에서 2개의 bounding box와 class를 예측을 하게 된다.
즉 7 x 7 x 30 의 의미는 다음과 같다.
- 7 x 7 x 30 == S x S x (5 x B + C)
- S = feature size : 7
- 5 = (cx, cy, w, h, conffidence)
- B = number of boxes : 2
- C = classes : 20 (PASCAL VOC dataset)
yolo의 conffidence score는 Pr(Object) x IOU 로 물체가 있을 확률과 실제 물체의 bounding box와 예측 bounding box와의 iou를 곱해서 구하게 된다.
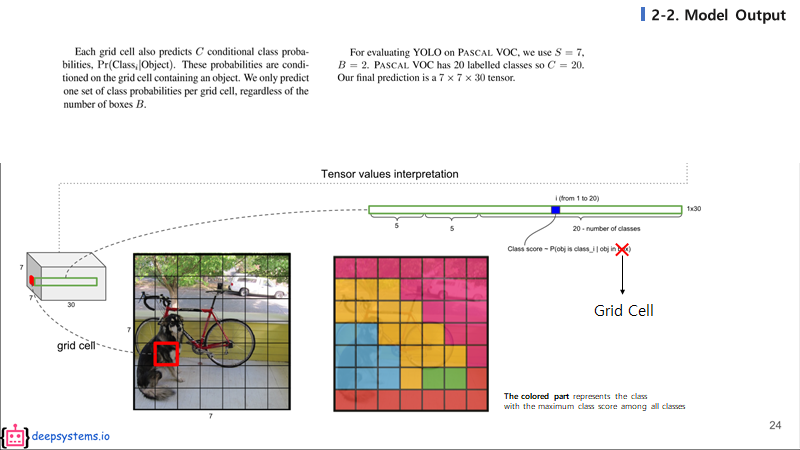
각 grid cell 하나하나는 20개의 클래스에 대한 예측 값들을 가지게 된다. 위 그림의 grid cell을 여러가지의 색으로 구분한 그림을 보자. 서로 다른 색은 서로 다른 클래스이고, 각 그리드 셀에서 가장 높게 예측된 클래스의 색을 칠하면 위와 같은 그림이 나올 것이다.
2-1. Network Design
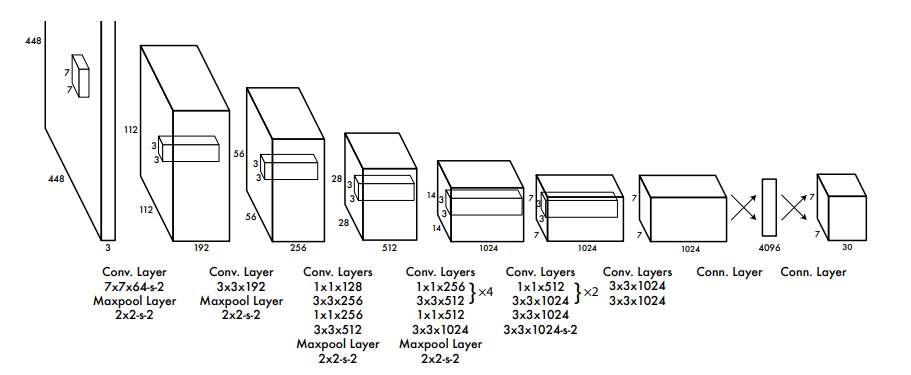
YOLO v1은 GoogLeNet의 네트워크 구조를 모티브로 하였고 총 24개의 conv layer와 2개의 FC layer를 포함하고 있다. GoogLeNet의 inception을 가져와 1x1 conv를 활용하여 연산량을 줄이려고 하였고 그 외의 모든 conv layer에서는 3x3 filter만 사용하였다.
참고로 논문에서는 왼쪽 20개의 conv layer는 GoogLeNet을 이용하여 ImageNet classification에 사용된 weight를 가져와 fine tuning하였는데 구현 코드에서는 그냥 처음부터 학습을 시켰다.
2-2 Training
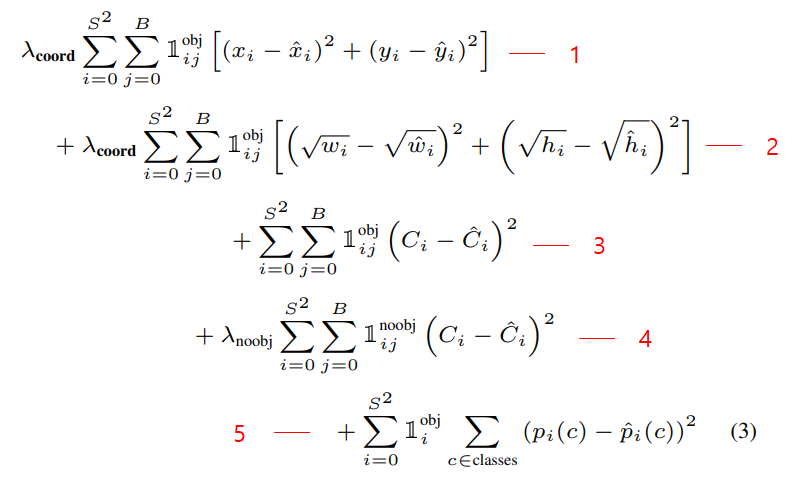
YOLO v1은 위와같은 Multi Loss를 사용하였다. 특이한 점은 CrossEntropy가 아닌 SSE(Sum Square Error)를 사용했다는 것인데 구간별로 천천히 살펴보자
lambda_coord : 5
lambda_noobj : 0.5
- Localization loss : x, y값을 regression하는 SSE loss
- Localization loss : width, height값은 regression하는 SSE loss
- Confidence loss : object가 있는 곳의 confidence SSE loss
- Confidence loss : object가 없는 곳의 confidence SSE loss
- Classification loss : object가 있는 곳의 각 class별 SSE loss (각 셀당 1개의 class probability가 나오므로 ij가 아닌 i뿐)
참고로 loss를 구하기 전에 미리 ground truth쪽 confidence와 해당 클래스의 인덱스에 1을 할당해준다.
2-3 Inference
테스트할 때, 성능을 확인하기 위해서 최종적인 bounding box를 예측해야 한다.
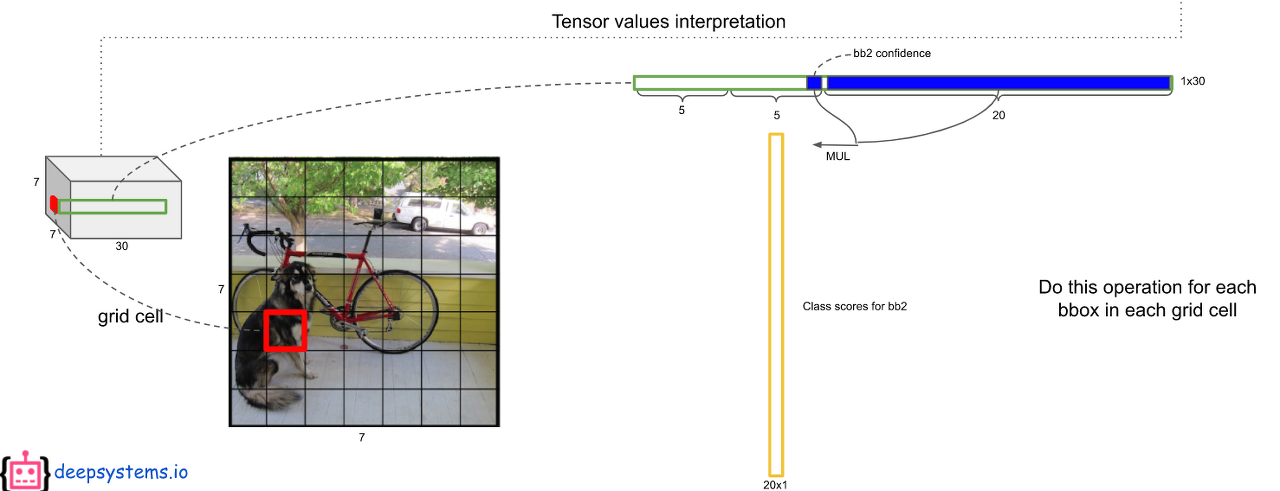
첫번째로 ouput 에서 예측된 bbox의 confidence score와 class score를 곱한다.
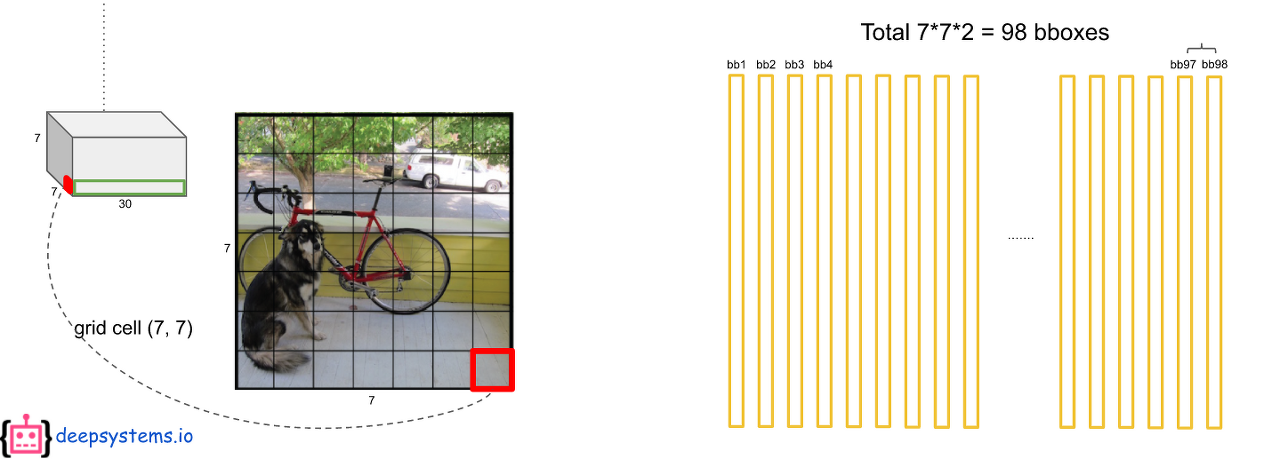
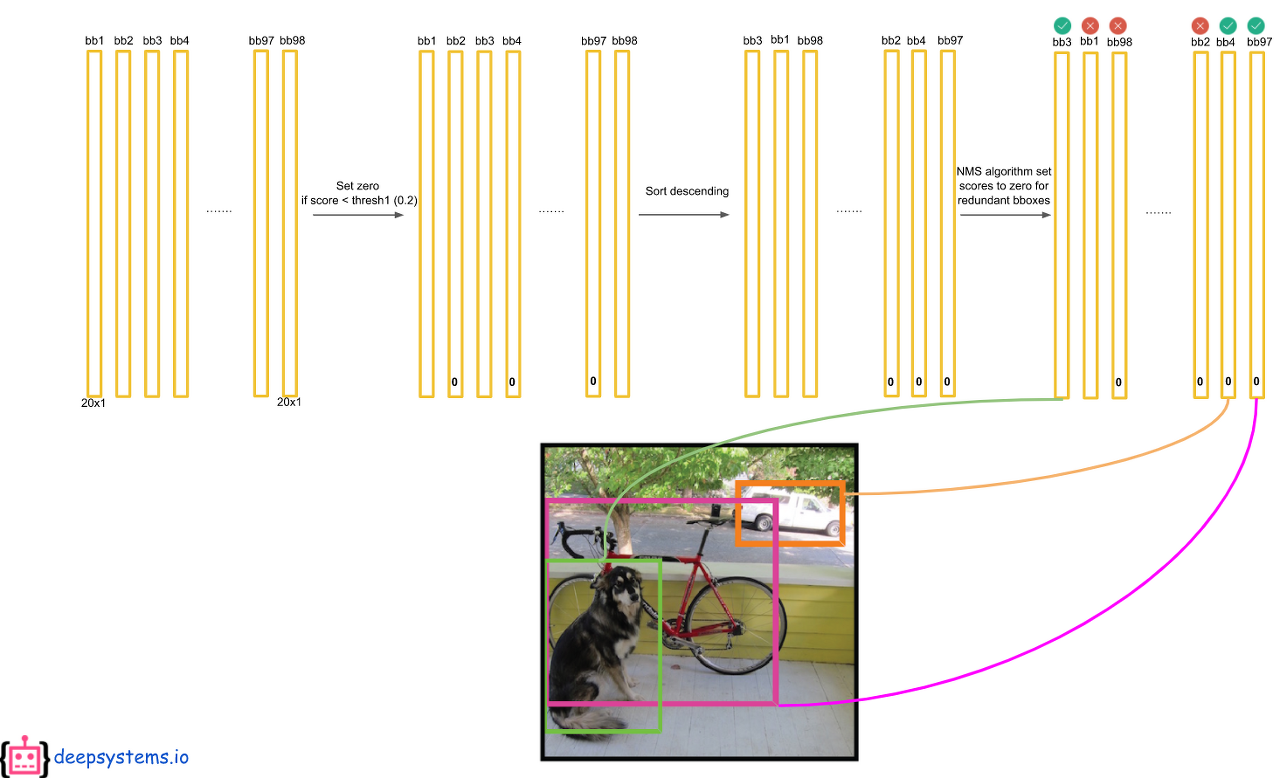
7 x 7의 각 grid cell에 2개의 bbox를 예측하므로 총 98개의 막대(20 x 1 벡터)가 나오게 된다. 그러면 최종적으로 98 x 20 = 1440개의 값이 나오는데 이것을 어떻게 처리해야 한 물체에 하나의 bbox가 나오게 될까?
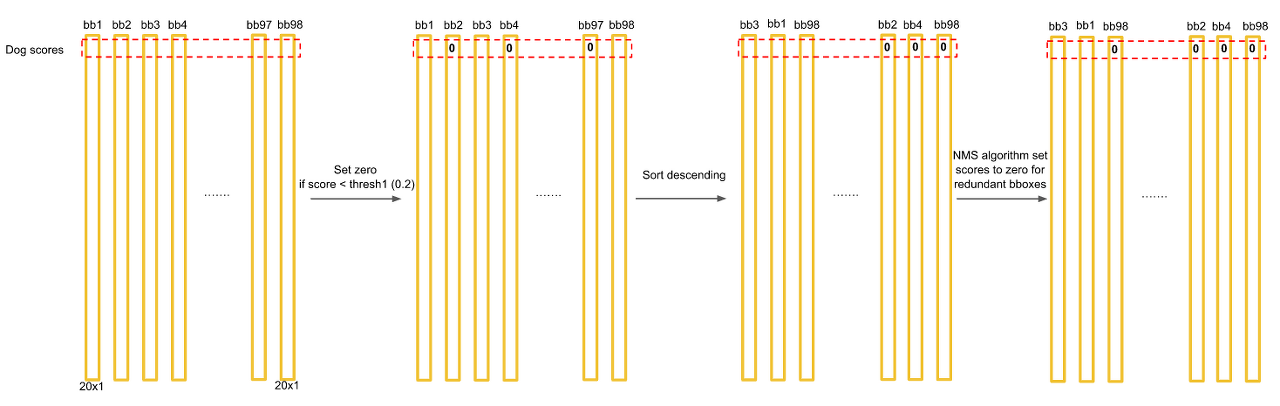
먼저 1440개의 값중에 0.2(Threshold)보다 작은 값들은 모두 0으로 만든다. 그 후에 클래스별로 내림차순으로 정렬을 하고 NMS 기법을 통해서 최종 detection output을 만들어 낸다. NMS는 아래 포스팅에서 자세히 다뤘으니 넘어가겠다.
[NMS(Non Max Suppression)
NMS(Non Max Suppression) 이번 포스팅 에서는 IOU에 이어서 NMS(Non Max Suppression)에 대해 알아보려고 한다. NMS는 여러 Object Detection논문(YOLO, SSD 등)에서 사용한 방법으로 각각의 물체에 대한 bound..
visionhong.tistory.com](https://visionhong.tistory.com/11)
모든 클래스에 대해 NMS을 적용하면 대부분의 값들이 0으로 만들어 질 것이다.
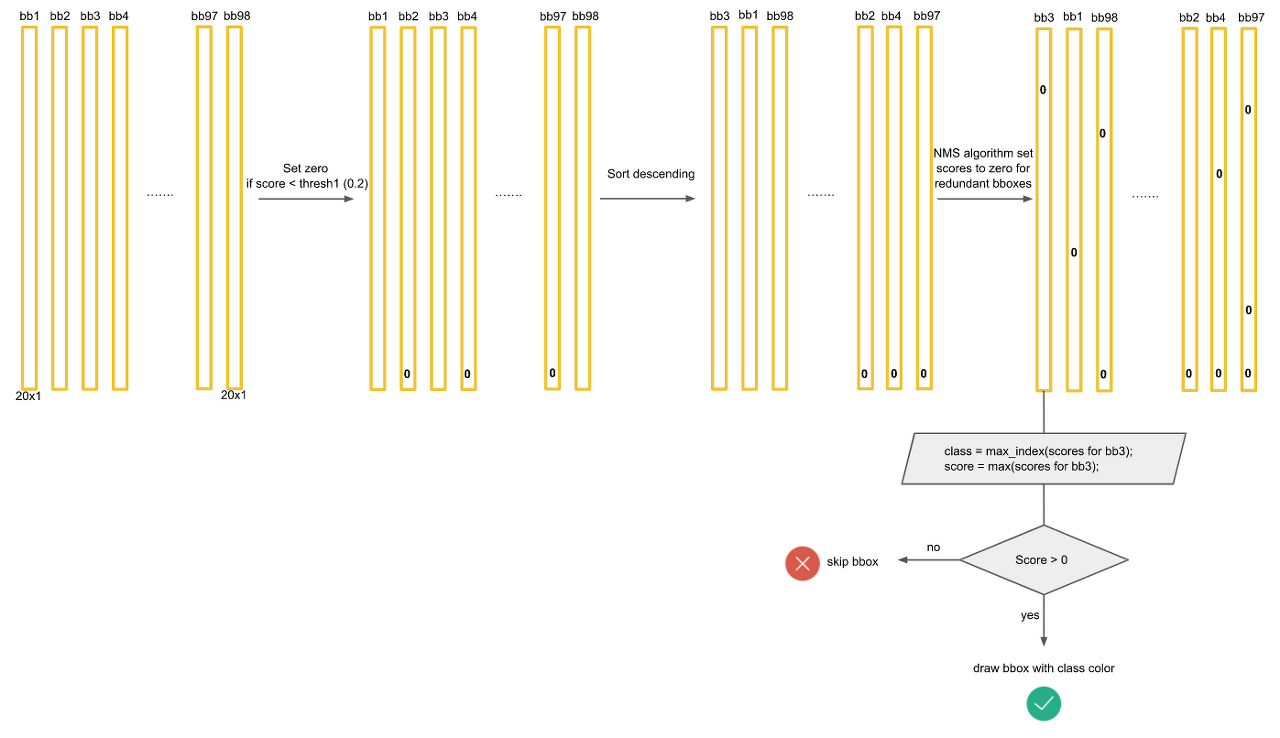
마지막으로 각 bbox에 대해서 가장 크게 예측되고 0보다 큰 클래스만 뽑아내면 아래와 같이 몇개의 막대만 살아남게되고 이것이 최종 output이 된다.
2.4 Limitations of YOLO
- YOLO는 1개의 grid cell당 1개의 class만 취급하기 때문에 2개 이상의 물체들의 중심이 한 grid cell에 모여있더라도 한가지의 class만 예측할 수 있다. 그렇다는 것은 새 떼와 같은 작은 물체들이 모여있을때 감지를 하지 못하게 된다.
- 일정한 비율의 bbox로만 예측을 하다보니 색다른 비율을가진 물체에 대한 예측이 좋지 못하다. -> 일반화가 어려움
- 작은 bbox의 loss와 큰 bbox의 loss를 동일하게 처리한다. -> 큰 상자의 작은 움직임에 비해 작은 상자의 작은 움직임은 훨씬 더 큰 형향을 끼치기 때문
이러한 단점들로 인해 YOLO v1의 속도는 엄청 빠르지만 반면에 정확도가 SOTA에 비해 낮았다.
3. Experiments
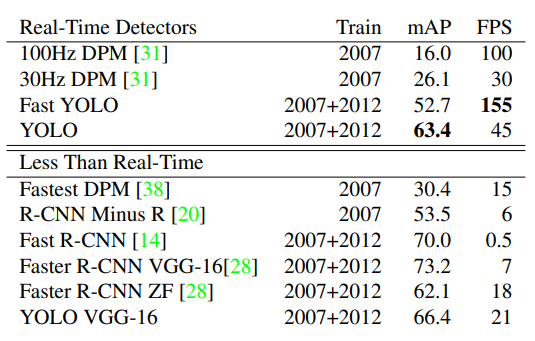
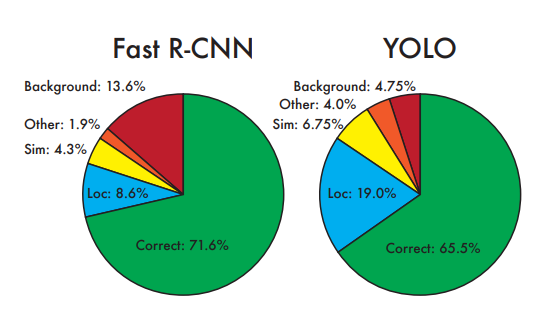
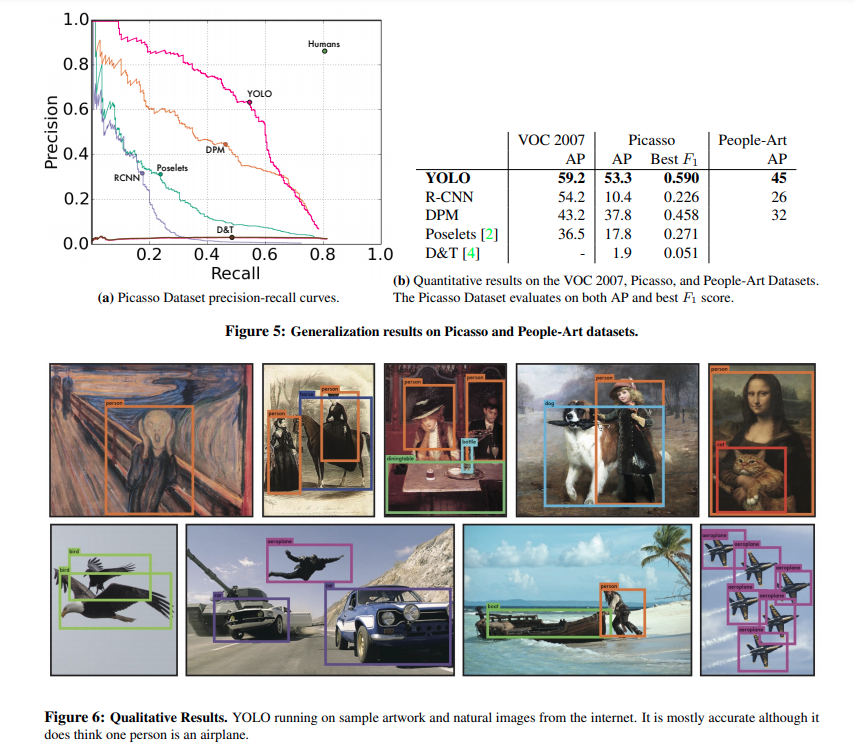
4. Conclusion
- one stage detector로서 엄청 빠르다. (Real Time Object Detection)
- 다른 도메인에서도 빠르고 나름 괜찮은 성능을 보인다.
- 하지만 단점이 많다. (YOLO v2 부터 많은 개선이 일어남)
Pytorch 구현(Colab)
PASCAL VOC 2007 데이터를 train, test 폴더를 만들어서 받아온다.
- xml파일을 parsing하기 위해 xml라이브러리 대신 xmltodict이라는 라이브러리를 설치
- augmentation을 위한 albumentations 라이브러리 설치
``` python root_dir = '/content' annot_f = './{}/VOCdevkit/VOC2007/Annotations' image_f = './{}/VOCdevkit/VOC2007/JPEGImages/{}'
classes = ['person', 'bird', 'cat', 'cow', 'dog', 'horse',
'sheep', 'aeroplane', 'bicycle', 'boat', 'bus', 'car',
'motorbike', 'train', 'bottle', 'chair', 'dining table',
'potted plant', 'sofa', 'tv/monitor' ]
num_classes = len(classes)
feature_size = 7
num_bboxes = 2
<br>
파일 경로와 PASCAL VOC class 정의
``` python
import sys
from torch.autograd import Variable
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.optim.lr_scheduler
from torch.utils.data import Dataset, DataLoader
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
## utils
import numpy as np
import random, math, time
from tqdm.notebook import tqdm
## File Loader
import os, xmltodict
import os.path as pth
from PIL import Image
# Draw Image
import matplotlib.pyplot as plt
import matplotlib.patches as patches
## Transformer
from random import sample
import albumentations as A
from albumentations.pytorch.transforms import ToTensor
# Seed
random.seed(53)
필요한 라이브러리, 모듈 import
시각화

- xml파일을 읽어서 필요한 정보만 parsing해서 딕셔너리를 감싼 리스트로 반환
- len(traval_list) = 3067
- len(traval_list) = 4952
- traval_list 파일을 train, valid set으로 나누어주는 함수
- 사용자 정의 Dataset
- target data에 대한 encoding을 하는 함수
- target (7 x 7 x 30) 에서 물체의 담당 셀의 정보(confidence, class index)에 1 나머지는 0으로 만들어줌
- albumentations을 사용하여 transform 정의
- albumentationd은 bbox의 변환도 알아서 같이 해주는 미친 라이브러리!
- DataLoader 정의
- YOLO v1 모델 정의
- IOU(Intersection Over Union)를 계산해주는 함수
- loss를 구해주는 Loss Function 함수
- 모델 인스턴스 생성, optimizer정의, Learning rate schedule 함수
- Training 진행 (80 epoch까지 약 1시간 30분걸렸음)
- 예측결과 Tensor를 다시 boxes, labels, confidences, class_score로 decoding하는 함수
- Test Visualization
End
이번 포스팅에서는 YOLO v1에대해 알아보았다. 지금을 기점으로 차근차근 논문 구현코드를 하나하나씩 뒤집어 엎어 볼 예정이다. 아직은 정말 너무 어렵지만 계속 나아갈 것이다. Keep going
Reference
- Paper- arxiv.org/abs/1506.02640
- PPT - docs.google.com/presentation/d/1aeRvtKG21KHdD5lg6Hgyhx5rPq_ZOsGjG5rJ1HP7BbA/pub?start=false&loop=false&delayms=3000&slide=id.p
- Review- www.youtube.com/watch?v=eTDcoeqj1_w&t=1680s
- YOLO v1 pytorch Colab - wolfy.tistory.com/259?category=903250
- YOLO v1 pytorch Github - github.com/motokimura/yolo_v1_pytorch