머신러닝 모델 개발에서는 데이터, 프로그램, 모델이라고 하는 세 가지 리소스를 모두 관리해야 한다. 이 세가지 리소스는 반드시 동기화되어 함께 변경된다고 장담할 수 없기에 학습할 때마다 각 리소스를 기록하고 실험관리를 해야한다. 이번 포스팅에서는 올바른 실험관리 방법과 모델관리 시스템에 대해 알아보려고 한다.
머신러닝 프로젝트를 시작하기 앞서 프로젝트를 지칭하는 이름이 필요하다. 프로젝트 이름은 현재 프로그램을 나타낼 수 있는 이름으로 누군가 보았을때 프로젝트를 단적으로 파악할 수 있는 명칭을 붙이는 것이 좋다. 예를들어 한국어를 영어로 번역하는 프로젝트라면 translate kr2en, 핸드폰 스크린에서 스크래치를 검출하는 프로젝트라면 Clean the screen 과 같은 이름을 지을 수 있을 것이다.
프로젝트명을 정했다면, 다음으로 머신러닝 모델의 버전 관리 방법을 정해야 한다. 머신러닝 모델을 버전으로 관리하는 것은 매우 중요한 일이다. 머신러닝의 학습 단계에서는 파라미터를 수정하고 데이터를 추가해 나가면서 모델의 좋고 나쁨을 평가한다. 어떤 파라미터들로 어떤 모델이 좋은 결과를 냈는지 관리하면 파라미터를 효율적으로 선택할 수 있다. 그리고 학습에 사용한 데이터의 관리를 통해 학습된 모델이 정확하게 추론할 수 있는 데이터, 추론할 수 없는 데이터의 경향도 쉽게 파악할 수 있다. 데이터가 관리되지 않으면 train data가 valid, test 과정에서 다시 사용되는 상황이 발생할 수 있기 때문에 정당하게 평가되지 않은 모델이 릴리스될 위험도 있다.
모델 버전 관리와 더불어 모델에 대한 평가도 함께 관리해야 한다. 모델의 평가는 주로 데이터베이스에 테이블을 만들어 관리한다. 학습을 여러 차례 반복하는 프로젝트에서는 데이터와 파라미터, 모델 평가 간의 관계를 기억하기 어렵기 때문에 각 요소 간의 관계를 정의하고 관리하는 것이 바람직하다. 이를 위해 모델 관리 데이터베이스를 만들고 학습 결과를 함께 기록하는 테이블을 만들어 보려고 한다.
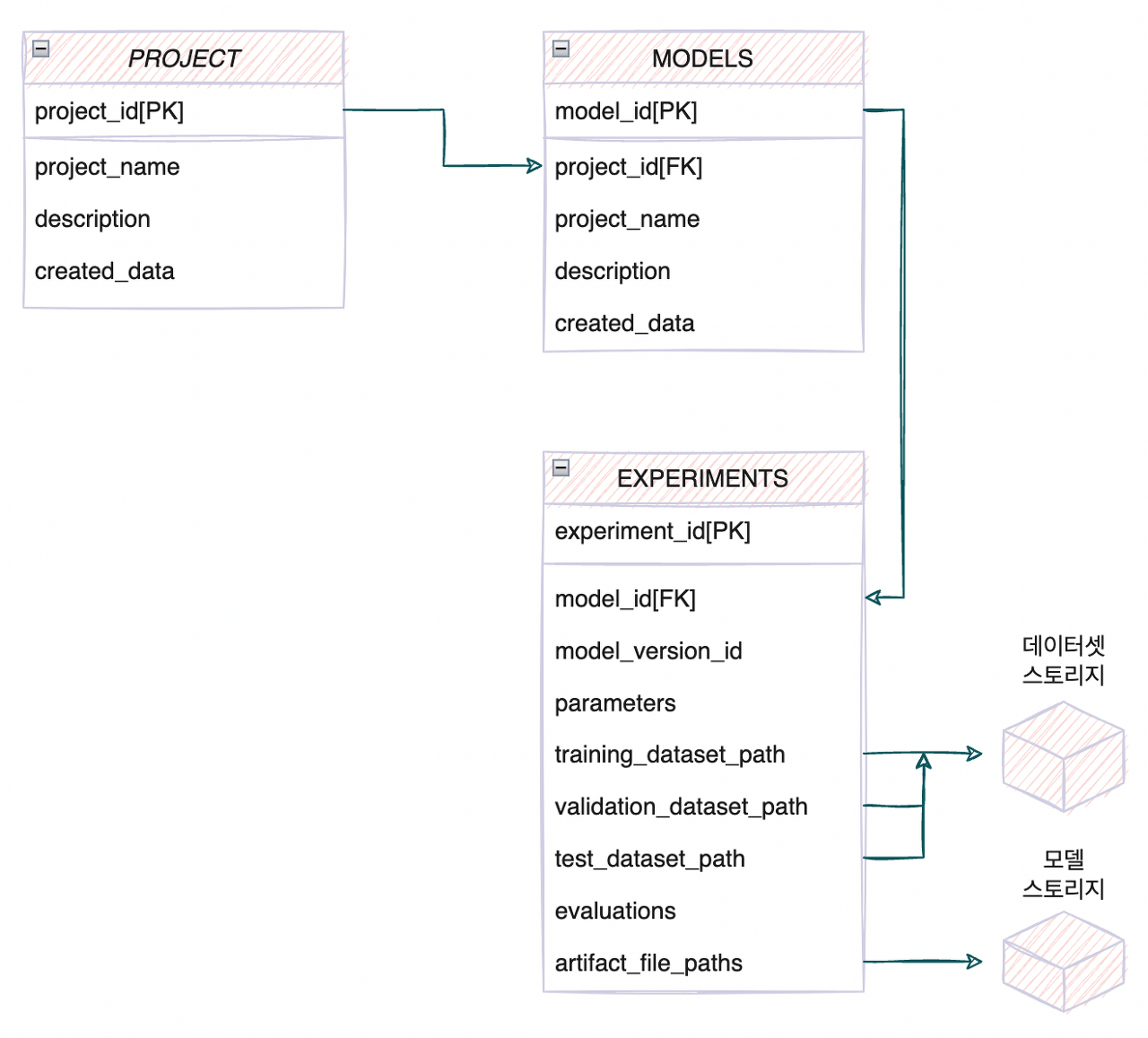
위 테이블은 간단하게 프로젝트 안에 모델이 있고 모델 안에 실험이 여러 개 등록된 형식이다. 실험 테이블에서는 파라미터, 데이터의 경로, 평가, 모델 파일이 관리되고 있음을 알 수 있다. 어떠한 프로젝트에 관한 모델의 학습과 평가를 할 때마다 실험 테이블에 그 결과가 쿼리 실행을 통해 데이터가 쌓이게 되는 것이다. 실험의 평가나 파라미터 선정, 데이터 선정에서는 모델 테이블로부터 여러 실험의 기록을 수집해 비교할 수 있다.
모델을 실제 시스템에 릴리스한 이우에도 모델의 버전명이 정해져 있다면 실제 데이터로부터 추론 결과를 추적할 수 있다는 장점이 있다. 추론 결과는 실제 시스템의 로그로 출력하게 되는데, 해당 로그를 모델 실험번호와 결합해서 모델의 장단점을 평가하고 다음 모델 개발에도 활용할 수 있게 된다.
구현
위 그림의 테이블을 활용해 모델 관리 서비스를 만들 수 있다.. 모델관리 서비스를 통해 여러 프로젝트 및 개발 환경에서 접근해 모델의 정보와 실험 결과들이 등록될 것이다. REST API 등에서 엔드포인트를 준비하고, 외부로부터 데이터 등록이나 참조 요청을 받는 구조가 필요하기 때문에 이를 파이썬 환경에서 FastAPI, PostgreSQL을 활용해 해결할 수 있다.
모델 관리 서비스의 구조는 아래와 같이 나타낼 수 있다.
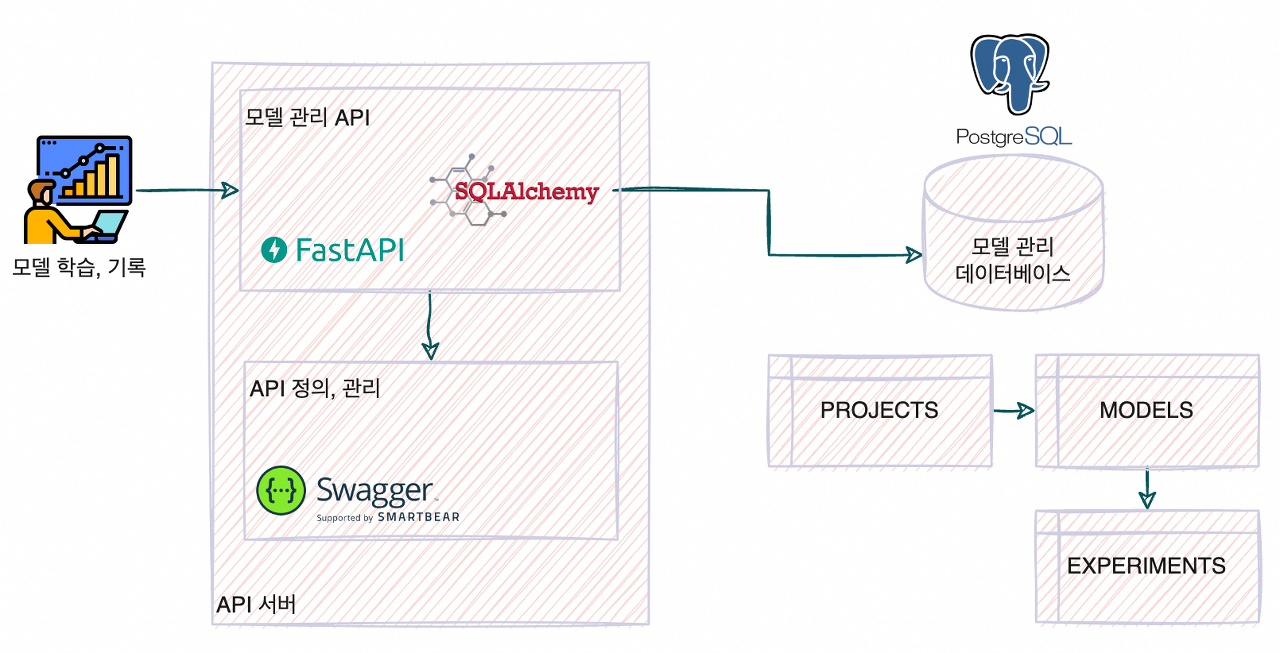
API 서버인 FastAPI로부터 SQLAlchemy라고 하는 ORM 라이브러리(데이터베이스의 테이블을 클래스 객체로 취합하는 라이브러리)를 사용해서 PostgresSQL 테이블에 접근 가능하다. 먼저 테이블을 아래와 같이 작성한다.
src/db/models.py
- 세개의 테이블 중 Project에 대한 테이블 구조를 확인해 보자
- 테이블 식별을 위한 __tablename__ 이 설정되어 있고 project_id는 Model 테이블에서 참조키로 필요하기 때문에 primary key로 선언되었다.
- 그 외 프로젝트명, 설명, 생성 시간에 대해서도 테이블 생성을 위한 설정을 해준다.
다음으로는 CRUD에서 Delete를 제외한 SQL 쿼리용 함수를 작성한다. SQL Alchemy에서는 다음과 같이 파이썬 함수로 SQL 쿼리를 작성할 수 있다.
src/db/cruds.py
- 이번엔 세가지 테이블중 Experiments 과 관련된 쿼리를 확인해보자.
- 전체를 select 하거나 실험 ID, 모델 버전 ID, 모델 ID, 프로젝트 ID를 통해 특정 실험을 select 할 수있다.
- add_experiment 함수를 통해 실험들 등록할 수 있으며 이때 experiment_id는 uuid 모듈의 해시값을 활용한다.
- update와 관련된 함수로는 실험 평가에 대한 메타데이터를 수정하기 위한 update_experiment_evaluation(), 모델의 경로를 수정하기 위한 update_experiment_artifact_file_path() 가 구현되었다.
이제 위와같은 쿼리를 실행하는 즉 데이터 조작을 실시하는 API는 FastAPI로 구현할 수 있다. FastAPI의 엔드포인트는 데코레이터를 통해 파이썬 함수로 정의한다.
src/api/routers/api.py
- 세가지 테이블 중 Model에 관련된 router를 확인해보자.
- 각 함수들은 고유한 엔드포인트를 가지고 있으며 해당 엔드포인트에 접속하면 쿼리문을 실행하는 구조로 설계되었다.
- 웹사이트에서는 http://
/<엔드포인트> 형식으로 접속 가능하다.
여기까지 기본적인 구현은 끝났다. FastAPI는 Uvicorn이라는 비동기 처리가 가능한 프레임워크에서 동작하는 라이브러리로 되어있다. Uvicorn은 ASGI(Asynchronous Server Gateway Interface)라고 불리는 표준 인터페이스를 제공하는 프레임워크로, 비동기 싱글 프로세스로 동작한다. 게다가 Uvicorn을 Gunicorn(green unicorn)에서 기동함으로써 멀티 프로세스로 사용할 수도 있다. Gunicorn은 WSGI(Web Server Gateway Interface)라 불리는 동기적 애플리케이션 인터페이스를 제공한다. Uvicorn을 Gunicorn에서 기동함으로써 ASGI의 비동기 처리와 WSGI 멀티 프로세스를 조합할 수 있게 되어있다.
웹 서버를 실행하는 run.sh파일에 여러 환경변수와 gunicorn 명령어가 작성되어있다.
run.sh
모델 관리 서비스를 컨테이너로 실행하려고 한다. 물론 개인 환경에서 서비스를 실행할 수도 있지만 이는 매우 좋지 못한 안티 패턴중 하나이다. 여기서 말하는 이른바 Only me 안티 패턴은 모델 개발의 전 과정을 머신러닝 엔지니어 개인 환경에서 실시하기 때문에 해당 환경에 강하게 의존하는 모델이 된다. 완성된 모델을 운영 환경에서 정상적으로 가동하려면 머신러닝 엔지니어의 개인 환경을 실제 환경에서도 재현해야 한다. 이를 위해서는 머신러닝 엔지니어의 프로그래밍 언어와 라이브러리의 버전 등을 입수해서 실제 시스템상에 구축해야 한다.
이 문제를 해결하기 위해 모델의 개발 환경과 실제 시스템에서의 공통의 OS, 언어, 의존 라이브러리의 버전을 미리 준비한다. 요즘은 도커와 같은 컨테이너 환경에서 시스템 환경을 구축하고 더 나아가 쿠버네티스 환경에서 관리하고 있다.
모델 관리 서비스를 컨테이너를 위해 먼저 이미지를 생성한다. 이미지는 Dockerfile을 작성 후 빌드하여 작성할 수 있다.
Dockerfile
- 소스코드를 컨테이너에 넘겨주고 실행에 필요한 리눅스 패키지와 파이썬 라이브러리를 설치 후 최종적으로 run.sh 파일을 실행하여 모델 관리 서비스를 실행시키는 로직
도커 이미지를 컨테이너로 실행하기 위해서 docker run 명령어를 실행하거나 docker-compose.yml 파일을 생성하여 docker-compose up 명령어를 실행하는 방법 2가지가 있다. 모델 관리 서비스를 실행하기 위해 필요한 이미지는 위 Dockerfile로 생성할 메인 이미지와 데이터베이스로 활용할 postgreSQL 이미지 두개가 필요하기 때문에 docker-compose.yml로 정리하여 손쉽게 실행하는 것이 좋아보인다.
docker-compose.yml
- 모델 관리 서비스가 실행되기 이전에 먼저 postgres DB가 실행될 필요가 있다. 이때 depends_on 을 사용해서 실행 순서를 지정한다.
- 컨테이너가 종료되더라도 DB에 저장된 데이터가 유지되어야 하기 때문에 postgres 컨테이너의 /var/lib/postgresql/data를 현재 경로에 있는 postgres 폴더에 마운트한다.
Dockerfile을 이미지로 빌드시키기위해 docker build 명령어가 필요하고 docker-compose.yml을 통해 컨테이너를 실행하기 위해 docker-compose up 명령어가 필요하다. 이를 좀 더 간단한 명령어로 바꿔줄 수 있다. makefile이라는 이름의 파일을 생성하고 아래와 같이 작성해주면 마치 .bashrc에서 alias를 활용하듯이 명령어를 쉽게 바꿀 수 있다.
makefile
- makefile에서의 환경변수는 := 를 통해 설정 가능하고 활용할때는 $() 안에 작성해 사용한다.
- docker build ~ 명령어는 build라는 명령어로, docker-compose up 명령어는 c_up 명령어로 세팅하였다.
이제 makefile을 통해 모델관리 서비스를 작동시켜보자.
2개의 컨테이너가 잘 실행되었음을 확인했고 http://localhost:8000/docs에 접속하면 아래와 같은 Swagger UI에 접속 가능하다. localhost:8000 으로 접속 가능한 이유는 run.sh 파일에서 gunicorn 명령어에 -b 옵션으로 0.0.0.0:8000 을 주었기 때문이다.
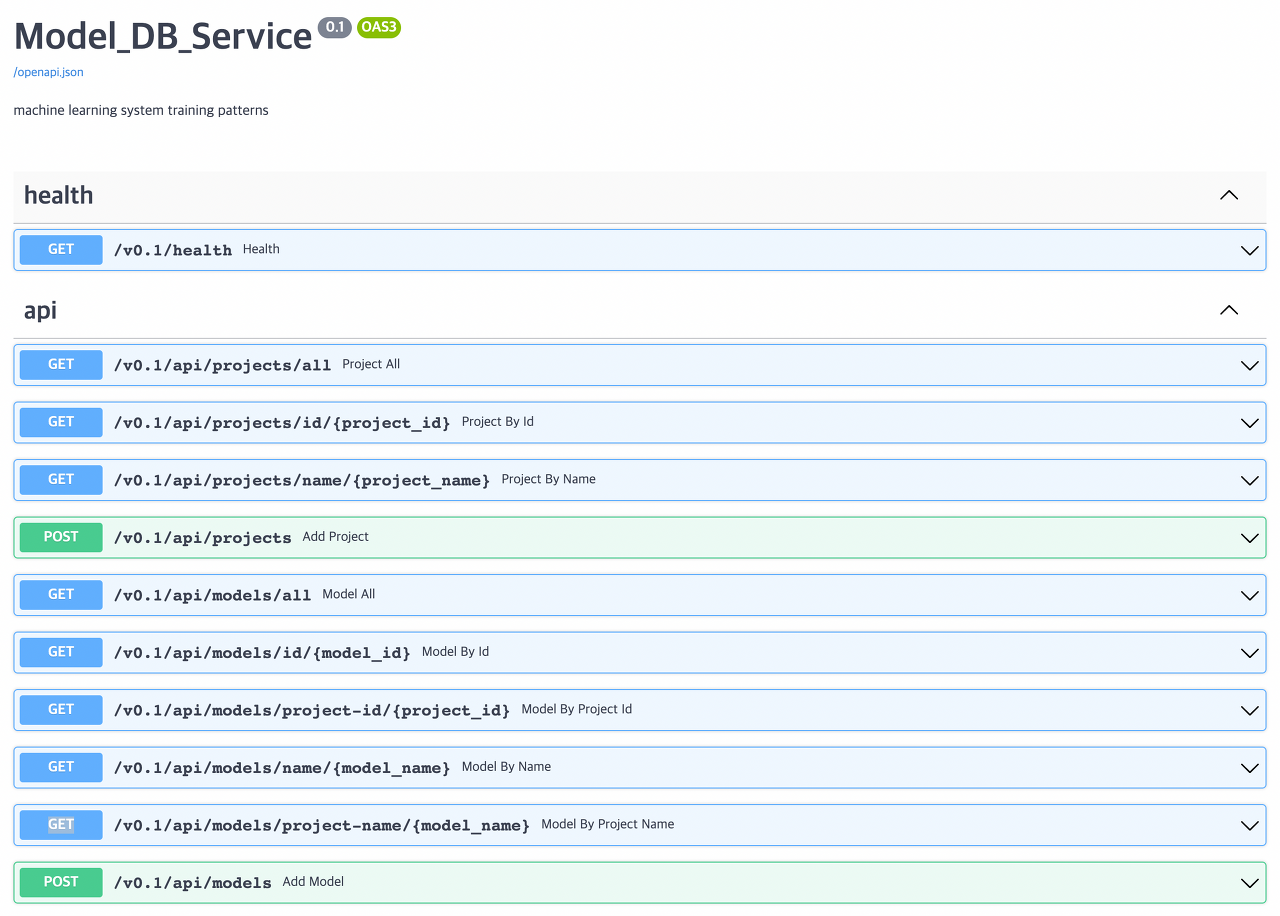
- 상단에서 src/api/app.py 파일에서 FastAPI 클래스를 초기화 하면서 작성한 title과 description, version을 볼 수 있다.
- health와 api라는 두가지의 라우터를 include 하였고 각각의 엔드포인트는 localhost:8000/v0.1/health, localhost:8000/v0.1/api 로 나뉜다.
먼저 상단의 health를 클릭하여 서비스의 health check를 진행해보자
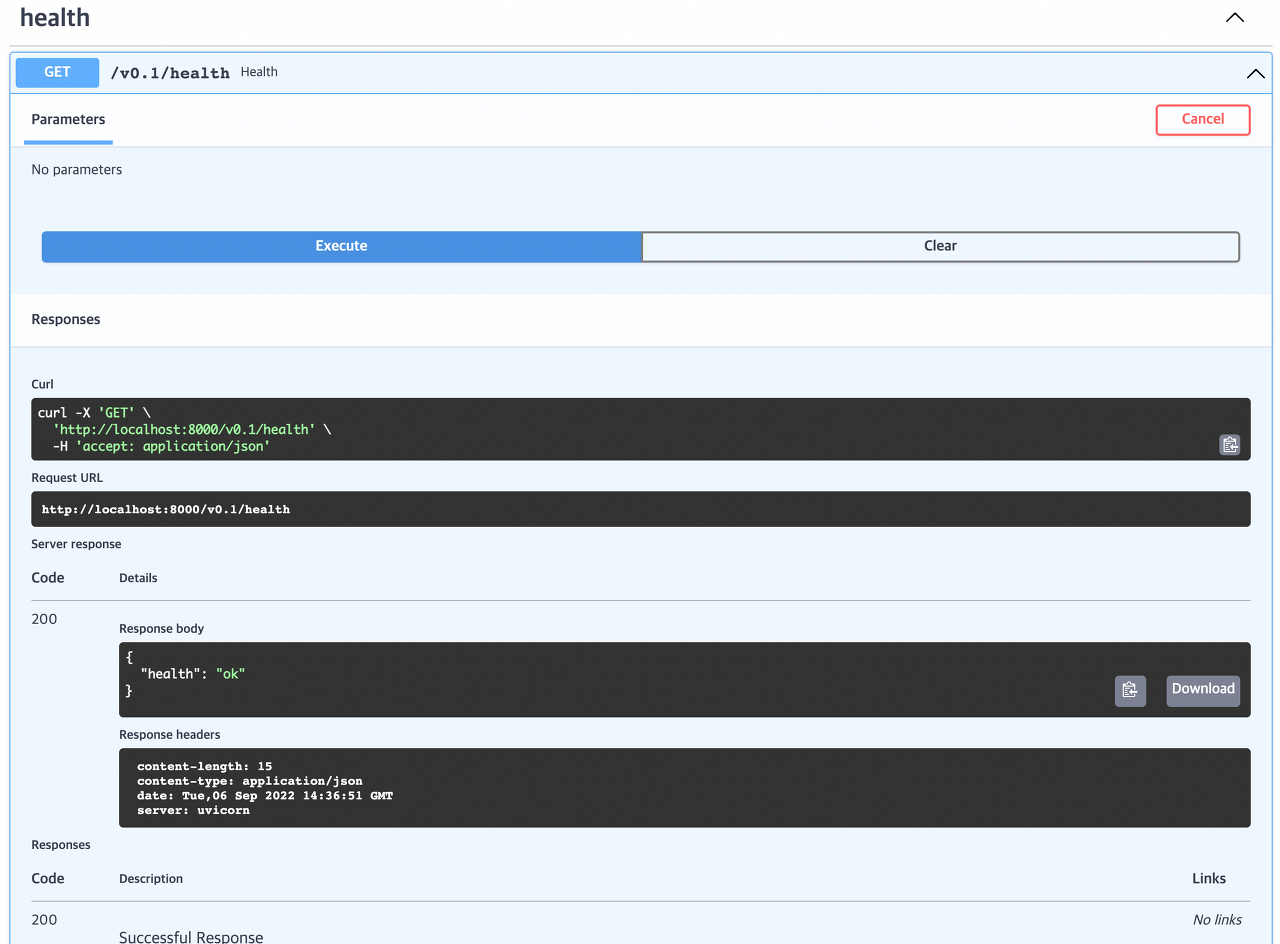
- http://localhost:8000/v0.1/health 로 정상적인 request를 보내면 {health: "ok"} 라는 response를 반환한다.
모델관리 서비스가 정상 작동하는것을 확인했으니 가상의 프로젝트를 생성하고 모델과 실험 관리를 시도해보자. 먼저 Add Project 엔드포인트로 동물 이미지 분류라는 프로젝트를 생성하였다.
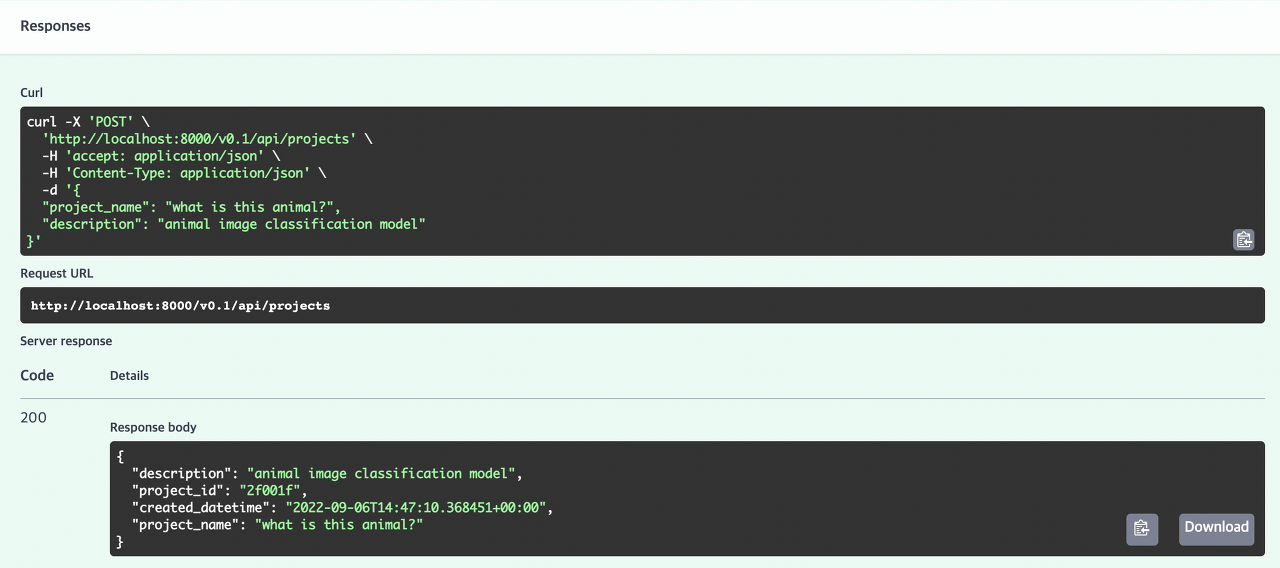
- 프로젝트 이름과 설명에 대한 정보를 포함하여 엔드포인트에 요청을 보내면 응답으로 테이블이 반환되도록 구현되었다.
- Response body를 확인해보면 자동으로 해시값의 project_id와 데이터가 등록된 시간인 created_datetime이 설정된다.
다음으로 모델을 생성해보자.
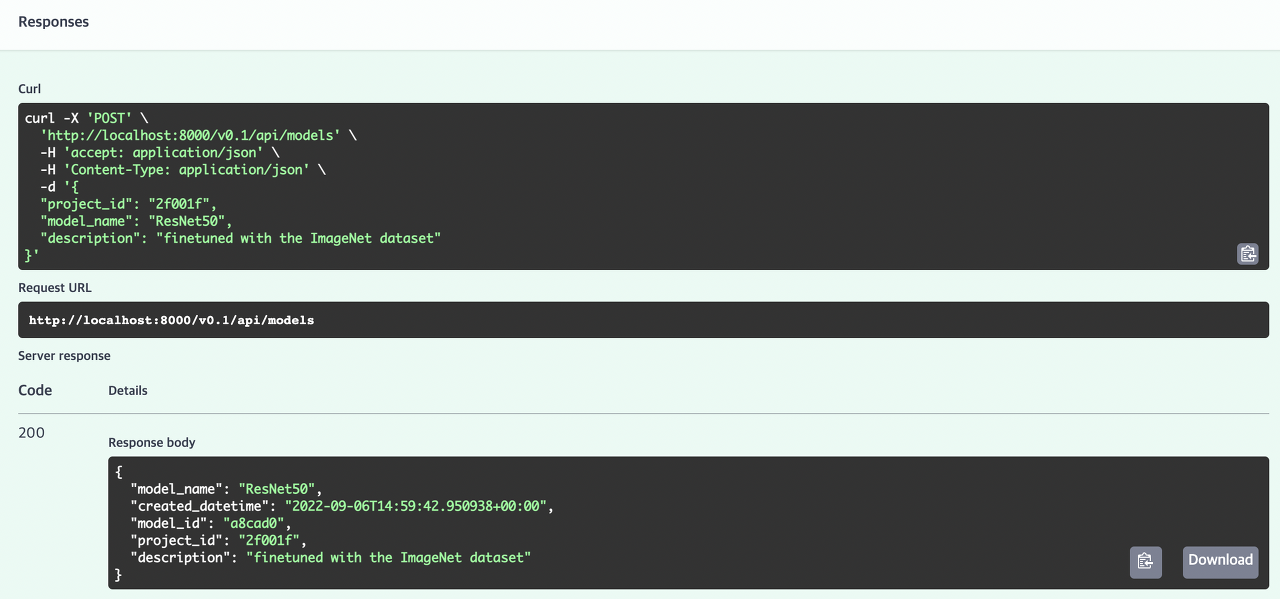
- 위에서 생성한 project_id와 모델이름 그리고 설명을 엔드포인트에 요청을 보내면 마찬가지로 모델 테이블을 반환한다.
생성한 모델이 DB에 잘 저장되었는지 확인하기 위해 모델의 이름을 통해 모델을 검색해보자. FastAPI에서 라우터 엔드포인트를 작성할 때 아래와 같이 중괄호를 설정하면 GET 요청을 보낼 때 파라미터를 입력 할 수 있다.
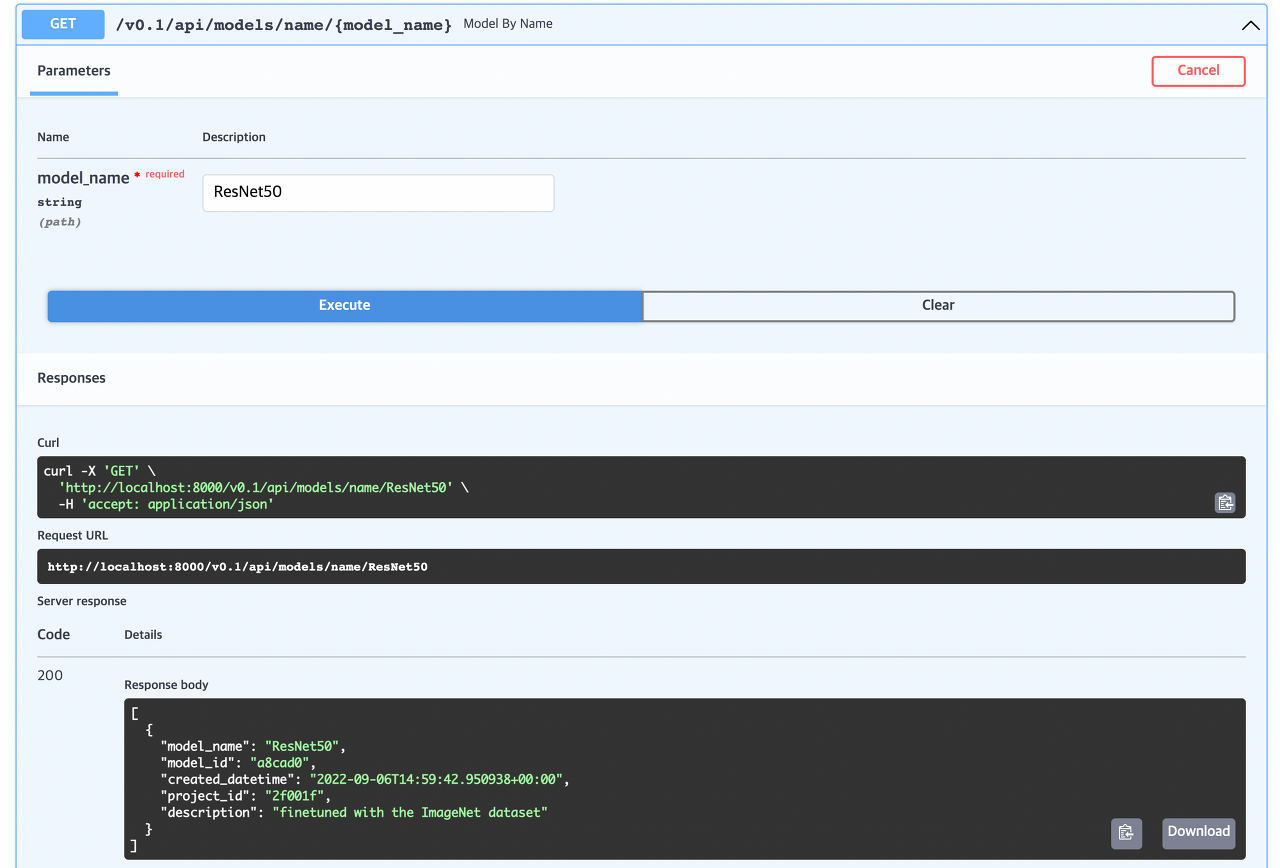
Experiment 생성도 Project, Model과 마찬가지이기 때문에 생략한다. 이 예제에서는 DB 테이블을 직접 구축해서 구현했지만 사실 다양한 툴에서 이미 이러한 기능을 제공하고 있다. 예로 MLflow의 모델 관리 컴포넌트를 활용하면 프로젝트별로 모델과 실험관리가 가능하며 CRUD 기능을 파이썬 함수로 제공한다.
End
이것으로 모델을 개발한 후에 모델과 실험을 관리할 수 있게 되었고 평가나 학습데이터를 등록할 수 있게 되었다. 다음 포스팅에서는 모델을 학습과 관련된 내용을 다루려고 한다. 모델 학습은 엔지니어 개인 컴퓨터나 GPU 서버에서 주피터 노트북으로 개발하는 경우가 대부분인데 학습 결과를 관리하고 추후에 비교 검토하기 위해서는 학습을 단계별로 관리할 필요가 있다. 이러한 학습 방법을 파이프라인 학습 패턴과 배치 학습 패턴으로 나누어 살펴보자.
Keep going
Reference
Book: AI 엔지니어를 위한 머신러닝 시스템 디자인 패턴
Open Source Code: https://github.com/wikibook/mlsdp/tree/main/chapter2_training/model_db#readme
My Code: https://github.com/visionhong/MLOps-DP/tree/main/model_training